這很重要
- Foundry Local 提供預覽版。 公開預覽版本可讓您搶先試用正在開發期間的功能。
- 正式發行前的功能、方法和程序可能會變更或有功能上的限制。
Foundry Local SDK 透過提供與資料平面推理程式碼分開的控制平面操作,簡化了本機環境中的 AI 模型管理。 此參考說明 Python、JavaScript、C# 和 Rust 的 SDK 實作。
Python SDK 指南
先決條件
- 安裝 Foundry Local,並確認
foundry指令可在你的PATH使用。 - 使用 Python 3.9 或更新版本。
安裝
安裝 Python 套件:
pip install foundry-local-sdk
快速入門
使用此摘要驗證 SDK 是否能啟動服務並存取本地目錄。
from foundry_local import FoundryLocalManager
manager = FoundryLocalManager()
manager.start_service()
catalog = manager.list_catalog_models()
print(f"Catalog models available: {len(catalog)}")
當服務運行且目錄可用時,此範例會列印非零數字。
參考:
FoundryLocalManager 類別
類別 FoundryLocalManager 提供管理模型、快取和 Foundry Local 服務的方法。
初始化
from foundry_local import FoundryLocalManager
# Initialize and optionally bootstrap with a model
manager = FoundryLocalManager(alias_or_model_id=None, bootstrap=True)
-
alias_or_model_id:(選擇性) 在啟動時下載和載入的別名或模型識別碼。 -
bootstrap:(預設值 True) 如果為 True,如果未執行,則會啟動服務,並在提供時載入模型。
別名的附註
此參考中概述的許多方法在簽章中都有參數 alias_or_model_id 。 您可以將 別名 或 模型標識碼 當做值傳遞至 方法。 使用別名將會:
- 為可用的硬體選擇最佳模型。 例如,如果 Nvidia CUDA GPU 可供使用,Foundry Local 會選取 CUDA 模型。 如果有支援的 NPU 可用,Foundry Local 會選取 NPU 模型。
- 可讓您使用較短的名稱,而不需要記住模型標識符。
小提示
建議您在 alias_or_model_id 參數中傳入別名,因為當您部署應用程式時,Foundry Local 會在執行階段取得最適合使用者機器的最佳模型。
備註
如果您在 Windows 上安裝了英特爾 NPU,請確保您已安裝英 特爾 NPU 驅動程序 以獲得最佳 NPU 加速。
服務管理
| 方法 | Signature | Description |
|---|---|---|
is_service_running() |
() -> bool |
檢查 Foundry 本地服務是否正在執行。 |
start_service() |
() -> None |
啟動 Foundry Local 服務。 |
service_uri |
@property -> str |
傳回服務 URI。 |
endpoint |
@property -> str |
傳回服務端點。 |
api_key |
@property -> str |
傳回 API 金鑰(從 env 或預設值)。 |
目錄管理
| 方法 | Signature | Description |
|---|---|---|
list_catalog_models() |
() -> list[FoundryModelInfo] |
列出目錄中所有可用的模型。 |
refresh_catalog() |
() -> None |
重新整理模型目錄。 |
get_model_info() |
(alias_or_model_id: str, raise_on_not_found=False) -> FoundryModelInfo \| None |
依別名或標識碼取得模型資訊。 |
快取管理
| 方法 | Signature | Description |
|---|---|---|
get_cache_location() |
() -> str |
傳回模型快取目錄路徑。 |
list_cached_models() |
() -> list[FoundryModelInfo] |
列出下載至本機快取的模型。 |
模型管理
| 方法 | Signature | Description |
|---|---|---|
download_model() |
(alias_or_model_id: str, token: str = None, force: bool = False) -> FoundryModelInfo |
將模型下載至本機快取。 |
load_model() |
(alias_or_model_id: str, ttl: int = 600) -> FoundryModelInfo |
將模型載入推斷伺服器。 |
unload_model() |
(alias_or_model_id: str, force: bool = False) -> None |
從推理服務器卸載模型。 |
list_loaded_models() |
() -> list[FoundryModelInfo] |
列出服務中目前載入的所有模型。 |
FoundryModelInfo
方法list_catalog_models()、list_cached_models()list_loaded_models()回傳物件清單FoundryModelInfo。 你可以利用這個物件中包含的資訊進一步精煉清單。 或者直接透過呼叫 get_model_info(alias_or_model_id) 方法取得模型資訊。
這些物件包含以下欄位:
| 領域 | 類型 | Description |
|---|---|---|
alias |
str |
模特兒的別名。 |
id |
str |
模型的唯一識別碼。 |
version |
str |
模型的版本。 |
execution_provider |
str |
執行模型的加速器(執行提供者)。 |
device_type |
DeviceType |
型號的裝置類型:CPU、GPU、NPU。 |
uri |
str |
模型的統一資源標識符。 |
file_size_mb |
int |
模型在磁碟上的大小(以 MB 為單位)。 |
supports_tool_calling |
bool |
模型是否支援工具呼叫。 |
prompt_template |
dict \| None |
模型的提示範本。 |
provider |
str |
模型提供者(模型發表地點)。 |
publisher |
str |
模型的出版者(誰是該模型的出版者)。 |
license |
str |
型號的授權名稱。 |
task |
str |
模型的任務。
chat-completions 或 automatic-speech-recognition 的其中之一。 |
ep_override |
str \| None |
覆蓋執行提供者的設定(如果與模型的預設執行提供者不同)。 |
執行提供者
擇一:
-
CPUExecutionProvider- 基於 CPU 的執行 -
CUDAExecutionProvider- NVIDIA CUDA GPU 執行 -
WebGpuExecutionProvider- WebGPU 的執行 -
QNNExecutionProvider- 高通神經網路處理單元(NPU) -
OpenVINOExecutionProvider- 英特爾 OpenVINO 執行環境 -
NvTensorRTRTXExecutionProvider- NVIDIA TensorRT 執行 -
VitisAIExecutionProvider- AMD Vitis AI 執行
範例使用方式
下列程式代碼示範如何使用 類別 FoundryLocalManager 來管理模型,並與 Foundry Local 服務互動。
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be selected
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry.
manager = FoundryLocalManager()
# List available models in the catalog
catalog = manager.list_catalog_models()
print(f"Available models in the catalog: {catalog}")
# Download and load a model
model_info = manager.download_model(alias)
model_info = manager.load_model(alias)
print(f"Model info: {model_info}")
# List models in cache
local_models = manager.list_cached_models()
print(f"Models in cache: {local_models}")
# List loaded models
loaded = manager.list_loaded_models()
print(f"Models running in the service: {loaded}")
# Unload a model
manager.unload_model(alias)
這個範例列出模型,下載並載入一個模型,然後卸載它。
參考:
與 OpenAI SDK 整合
安裝 OpenAI 套件:
pip install openai
下列程式代碼示範如何與 OpenAI SDK 整合 FoundryLocalManager ,以與本機模型互動。
import openai
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be downloaded
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry
# Local service if it is not already running and load the specified model.
manager = FoundryLocalManager(alias)
# The remaining code uses the OpenAI Python SDK to interact with the local model.
# Configure the client to use the local Foundry service
client = openai.OpenAI(
base_url=manager.endpoint,
api_key=manager.api_key # API key is not required for local usage
)
# Set the model to use and generate a streaming response
stream = client.chat.completions.create(
model=manager.get_model_info(alias).id,
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True
)
# Print the streaming response
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
此範例串流來自本地模型的聊天完成結果。
參考:
JavaScript SDK 參考
先決條件
- 安裝 Foundry Local,並確認
foundry指令可在你的PATH使用。
安裝
從 npm 安裝套件:
npm install foundry-local-sdk
快速入門
使用此摘要驗證 SDK 是否能啟動服務並存取本地目錄。
import { FoundryLocalManager } from "foundry-local-sdk";
const manager = new FoundryLocalManager();
await manager.startService();
const catalogModels = await manager.listCatalogModels();
console.log(`Catalog models available: ${catalogModels.length}`);
當服務運行且目錄可用時,此範例會列印非零數字。
參考:
FoundryLocalManager 類別
類別 FoundryLocalManager 可讓您在瀏覽器和 Node.js 環境中管理模型、控制快取,並與 Foundry Local 服務互動。
初始化
import { FoundryLocalManager } from "foundry-local-sdk";
const foundryLocalManager = new FoundryLocalManager();
可用選項:
-
host: Foundry 本地服務的基底 URL -
fetch:(選擇性) Node.js 等環境的自定義擷取實作
別名的附註
此參考中概述的許多方法在簽章中都有參數 aliasOrModelId 。 您可以將 別名 或 模型標識碼 當做值傳遞至 方法。 使用別名將會:
- 為可用的硬體選擇最佳模型。 例如,如果 Nvidia CUDA GPU 可供使用,Foundry Local 會選取 CUDA 模型。 如果有支援的 NPU 可用,Foundry Local 會選取 NPU 模型。
- 可讓您使用較短的名稱,而不需要記住模型標識符。
小提示
建議您在 aliasOrModelId 參數中傳入別名,因為當您部署應用程式時,Foundry Local 會在執行階段取得最適合使用者機器的最佳模型。
備註
如果您在 Windows 上安裝了英特爾 NPU,請確保您已安裝英 特爾 NPU 驅動程序 以獲得最佳 NPU 加速。
服務管理
| 方法 | Signature | Description |
|---|---|---|
init() |
(aliasOrModelId?: string) => Promise<FoundryModelInfo \| void> |
初始化 SDK,並選擇性地載入模型。 |
isServiceRunning() |
() => Promise<boolean> |
檢查 Foundry 本地服務是否正在執行。 |
startService() |
() => Promise<void> |
啟動 Foundry Local 服務。 |
serviceUrl |
string |
Foundry Local Service 的基底 URL。 |
endpoint |
string |
API 端點 (serviceUrl + /v1)。 |
apiKey |
string |
API 金鑰(無)。 |
目錄管理
| 方法 | Signature | Description |
|---|---|---|
listCatalogModels() |
() => Promise<FoundryModelInfo[]> |
列出目錄中所有可用的模型。 |
refreshCatalog() |
() => Promise<void> |
重新整理模型目錄。 |
getModelInfo() |
(aliasOrModelId: string, throwOnNotFound = false) => Promise<FoundryModelInfo \| null> |
依別名或標識碼取得模型資訊。 |
快取管理
| 方法 | Signature | Description |
|---|---|---|
getCacheLocation() |
() => Promise<string> |
傳回模型快取目錄路徑。 |
listCachedModels() |
() => Promise<FoundryModelInfo[]> |
列出下載至本機快取的模型。 |
模型管理
| 方法 | Signature | Description |
|---|---|---|
downloadModel() |
(aliasOrModelId: string, token?: string, force = false, onProgress?) => Promise<FoundryModelInfo> |
將模型下載至本機快取。 |
loadModel() |
(aliasOrModelId: string, ttl = 600) => Promise<FoundryModelInfo> |
將模型載入推斷伺服器。 |
unloadModel() |
(aliasOrModelId: string, force = false) => Promise<void> |
從推理服務器卸載模型。 |
listLoadedModels() |
() => Promise<FoundryModelInfo[]> |
列出服務中目前載入的所有模型。 |
範例使用方式
下列程式代碼示範如何使用 類別 FoundryLocalManager 來管理模型,並與 Foundry Local 服務互動。
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
const manager = new FoundryLocalManager();
// Initialize the SDK and optionally load a model
const modelInfo = await manager.init(alias);
console.log("Model Info:", modelInfo);
// Check if the service is running
const isRunning = await manager.isServiceRunning();
console.log(`Service running: ${isRunning}`);
// List available models in the catalog
const catalog = await manager.listCatalogModels();
// Download and load a model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// List models in cache
const localModels = await manager.listCachedModels();
// List loaded models
const loaded = await manager.listLoadedModels();
// Unload a model
await manager.unloadModel(alias);
此範例先下載並載入模型,然後列出快取與載入的模型。
參考:
與 OpenAI 用戶端整合
安裝 OpenAI 套件:
npm install openai
下列程式代碼示範如何與 OpenAI 用戶端整合 FoundryLocalManager ,以與本機模型互動。
import { OpenAI } from "openai";
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
// Create a FoundryLocalManager instance. This will start the Foundry
// Local service if it is not already running.
const foundryLocalManager = new FoundryLocalManager();
// Initialize the manager with a model. This will download the model
// if it is not already present on the user's device.
const modelInfo = await foundryLocalManager.init(alias);
console.log("Model Info:", modelInfo);
const openai = new OpenAI({
baseURL: foundryLocalManager.endpoint,
apiKey: foundryLocalManager.apiKey,
});
async function streamCompletion() {
const stream = await openai.chat.completions.create({
model: modelInfo.id,
messages: [{ role: "user", content: "What is the golden ratio?" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
}
streamCompletion();
此範例串流來自本地模型的聊天完成結果。
參考:
瀏覽器使用方式
SDK 包含一個瀏覽器相容版本,必須手動指定主機網址:
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
// Note: The `init`, `isServiceRunning`, and `startService` methods
// are not available in the browser version
備註
瀏覽器版本不支援 init、 isServiceRunning和 startService 方法。 在瀏覽器環境中使用 SDK 之前,您必須確定 Foundry Local 服務正在執行。 您可以使用 Foundry Local CLI 啟動服務: foundry service start。 您可以從 CLI 輸出擷取服務 URL。
範例使用方式
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
const alias = "qwen2.5-0.5b";
// Get all available models
const catalog = await manager.listCatalogModels();
console.log("Available models in catalog:", catalog);
// Download and load a specific model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// View models in your local cache
const localModels = await manager.listCachedModels();
console.log("Cached models:", localModels);
// Check which models are currently loaded
const loaded = await manager.listLoadedModels();
console.log("Loaded models in inference service:", loaded);
// Unload a model when finished
await manager.unloadModel(alias);
參考:
C# SDK 參考
專案設定指南
Foundry Local SDK 有兩個 NuGet 套件——一個是 WinML,一個是跨平台套件,兩者擁有相同的 API 表面,但針對不同平台進行優化:
-
Windows:使用
Microsoft.AI.Foundry.Local.WinML專為 Windows 應用程式設計的套件,採用 Windows Machine Learning (WinML) 框架。 -
跨平台:使用
Microsoft.AI.Foundry.Local可用於跨平台應用程式(Windows、Linux、macOS)的套件。
根據你的目標平台,請依照以下指示建立新的 C# 應用程式並加入必要的相依性:
在你的 C# 專案中使用 Foundry Local,請遵循以下 Windows 專用或跨平台(macOS/Linux/Windows)指示:
- 建立一個新的 C# 專案並順利進入:
dotnet new console -n app-name cd app-name - 打開並編輯
app-name.csproj檔案為:<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0-windows10.0.26100</TargetFramework> <RootNamespace>app-name</RootNamespace> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <WindowsAppSDKSelfContained>false</WindowsAppSDKSelfContained> <WindowsPackageType>None</WindowsPackageType> <EnableCoreMrtTooling>false</EnableCoreMrtTooling> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.AI.Foundry.Local.WinML" Version="0.8.2.1" /> <PackageReference Include="Microsoft.Extensions.Logging" Version="9.0.10" /> <PackageReference Include="OpenAI" Version="2.5.0" /> </ItemGroup> </Project> - 在專案根建立
nuget.config一個包含以下內容的檔案,以確保套件能正確還原:<?xml version="1.0" encoding="utf-8"?> <configuration> <packageSources> <clear /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> <add key="ORT" value="https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT/nuget/v3/index.json" /> </packageSources> <packageSourceMapping> <packageSource key="nuget.org"> <package pattern="*" /> </packageSource> <packageSource key="ORT"> <package pattern="*Foundry*" /> </packageSource> </packageSourceMapping> </configuration>
快速入門
使用此片段驗證 SDK 是否能初始化並存取本地模型目錄。
using Microsoft.AI.Foundry.Local;
using Microsoft.Extensions.Logging;
using System.Linq;
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
};
using var loggerFactory = LoggerFactory.Create(builder =>
{
builder.SetMinimumLevel(Microsoft.Extensions.Logging.LogLevel.Information);
});
var logger = loggerFactory.CreateLogger<Program>();
await FoundryLocalManager.CreateAsync(config, logger);
var manager = FoundryLocalManager.Instance;
var catalog = await manager.GetCatalogAsync();
var models = await catalog.ListModelsAsync();
Console.WriteLine($"Models available: {models.Count()}");
這個範例列印出你硬體可用的模型數量。
參考:
重新設計
為了提升你使用裝置 AI 發佈應用程式的能力,C# SDK 的架構在版本 0.8.0 及之後版本中進行了重大變更。 在本節中,我們將概述主要變更,幫助您將應用程式遷移到最新版本的 SDK。
備註
SDK 版本 0.8.0 及之後,API 與先前版本有重大變更。
下圖展示了先前架構—在更早 0.8.0 版本中 —如何大量依賴使用 REST 網頁伺服器來管理模型與推論,例如聊天完成:

SDK 會使用遠端程序呼叫(RPC)在機器上尋找 Foundry Local CLI 執行檔,啟動網頁伺服器,然後透過 HTTP 與它通訊。 此架構存在多項限制,包括:
- 管理網頁伺服器生命週期的複雜性。
- 部署困難:終端使用者必須在他們的機器 和 應用程式上安裝 Foundry 本地 CLI。
- CLI 與 SDK 的版本管理可能導致相容性問題。
為了解決這些問題,重新設計的 0.8.0 架構版本及後續版本採用了更精簡的方法。 新架構如下:

在這個新架構中:
- 你的應用程式是自給自足的。 它不需要將 Foundry 本地 CLI 單獨安裝在終端使用者的機器上,讓你更容易部署應用程式。
- REST 網頁伺服器是 可選的。 如果你想和其他透過 HTTP 通訊的工具整合,仍然可以使用網頁伺服器。 請閱讀「透過 REST 伺服器使用 Foundry Local 進行聊天補全」的詳細資訊,了解如何使用此功能。
- SDK 原生 支援聊天完成與音訊轉錄,讓您能以較少依賴建立對話式 AI 應用程式。 請參閱 Use Foundry Local 本地聊天完成 API 以了解如何使用此功能。
- 在 Windows 裝置上,你可以使用 Windows 機器學習版本,透過拉入正確的執行時和驅動程式,為裝置上的模型進行 硬體加速 。
API 變更
版本 0.8.0 及以後的版本提供更物件導式且可組合的 API。 主要入口仍然是類別FoundryLocalManager,但現在不再是一組以靜態方式呼叫無狀態 HTTP API 的方法。SDK 現在會在FoundryLocalManager實例上,暴露用於維護服務與模型狀態的方法。
| 原始 | 版本 < 0.8.0 | 版本 >等於 0.8.0 |
|---|---|---|
| Configuration | 不適用 | config = Configuration(...) |
| 取得管理器 | mgr = FoundryLocalManager(); |
await FoundryLocalManager.CreateAsync(config, logger);var mgr = FoundryLocalManager.Instance; |
| 取得目錄 | 不適用 | catalog = await mgr.GetCatalogAsync(); |
| 車型列表 | mgr.ListCatalogModelsAsync(); |
catalog.ListModelsAsync(); |
| 取得模型 | mgr.GetModelInfoAsync("aliasOrModelId"); |
catalog.GetModelAsync(alias: "alias"); |
| 取得變體 | 不適用 | model.SelectedVariant; |
| 設定變體 | 不適用 | model.SelectVariant(); |
| 下載模型 | mgr.DownloadModelAsync("aliasOrModelId"); |
model.DownloadAsync() |
| 載入模型 | mgr.LoadModelAsync("aliasOrModelId"); |
model.LoadAsync() |
| 卸載模型 | mgr.UnloadModelAsync("aliasOrModelId"); |
model.UnloadAsync() |
| 清單載入模型 | mgr.ListLoadedModelsAsync(); |
catalog.GetLoadedModelsAsync(); |
| 取得模型路徑 | 不適用 | model.GetPathAsync() |
| 開始營運 | mgr.StartServiceAsync(); |
mgr.StartWebServerAsync(); |
| 停止服務 | mgr.StopServiceAsync(); |
mgr.StopWebServerAsync(); |
| 快取位置 | mgr.GetCacheLocationAsync(); |
config.ModelCacheDir |
| 快取模型列表 | mgr.ListCachedModelsAsync(); |
catalog.GetCachedModelsAsync(); |
API 讓 Foundry Local 在網頁伺服器、日誌記錄、快取位置及型號變體選擇上更具可配置性。 例如,這個 Configuration 類別允許你設定應用程式名稱、日誌層級、網頁伺服器網址,以及應用程式資料、模型快取和日誌的目錄:
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
Web = new Configuration.WebService
{
Urls = "http://127.0.0.1:55588"
},
AppDataDir = "./foundry_local_data",
ModelCacheDir = "{AppDataDir}/model_cache",
LogsDir = "{AppDataDir}/logs"
};
參考:
在先前版本的 Foundry Local C# SDK 中,無法直接透過 SDK 設定這些設定,限制了自訂服務行為的能力。
縮小應用程式套件大小
Foundry Local SDK 會提取 Microsoft.ML.OnnxRuntime.Foundry NuGet 套件當做相依性。 該 Microsoft.ML.OnnxRuntime.Foundry 套件提供 推理執行時套件,這是在特定廠商硬體裝置上有效執行推理所需的函式庫集合。 推論執行時套件包含以下元件:
-
ONNX 執行時函式庫:核心推論引擎(
onnxruntime.dll)。 -
ONNX 執行執行提供者(EP)函式庫。 ONNX Runtime 中一個針對硬體的後端,負責優化並利用硬體加速器執行機器學習模型的部分。 例如:
- CUDA EP:
onnxruntime_providers_cuda.dll - QNN EP:
onnxruntime_providers_qnn.dll
- CUDA EP:
-
獨立硬體供應商(IHV)函式庫。 例如:
- WebGPU:DirectX 相依性 (
dxcompiler.dll,dxil.dll) - QNN:Qualcomm QNN 相依性(
QnnSystem.dll等等)
- WebGPU:DirectX 相依性 (
下表總結了你的應用程式所附帶的 EP 與 IHV 函式庫,以及 WinML 執行時會下載/安裝哪些函式庫:
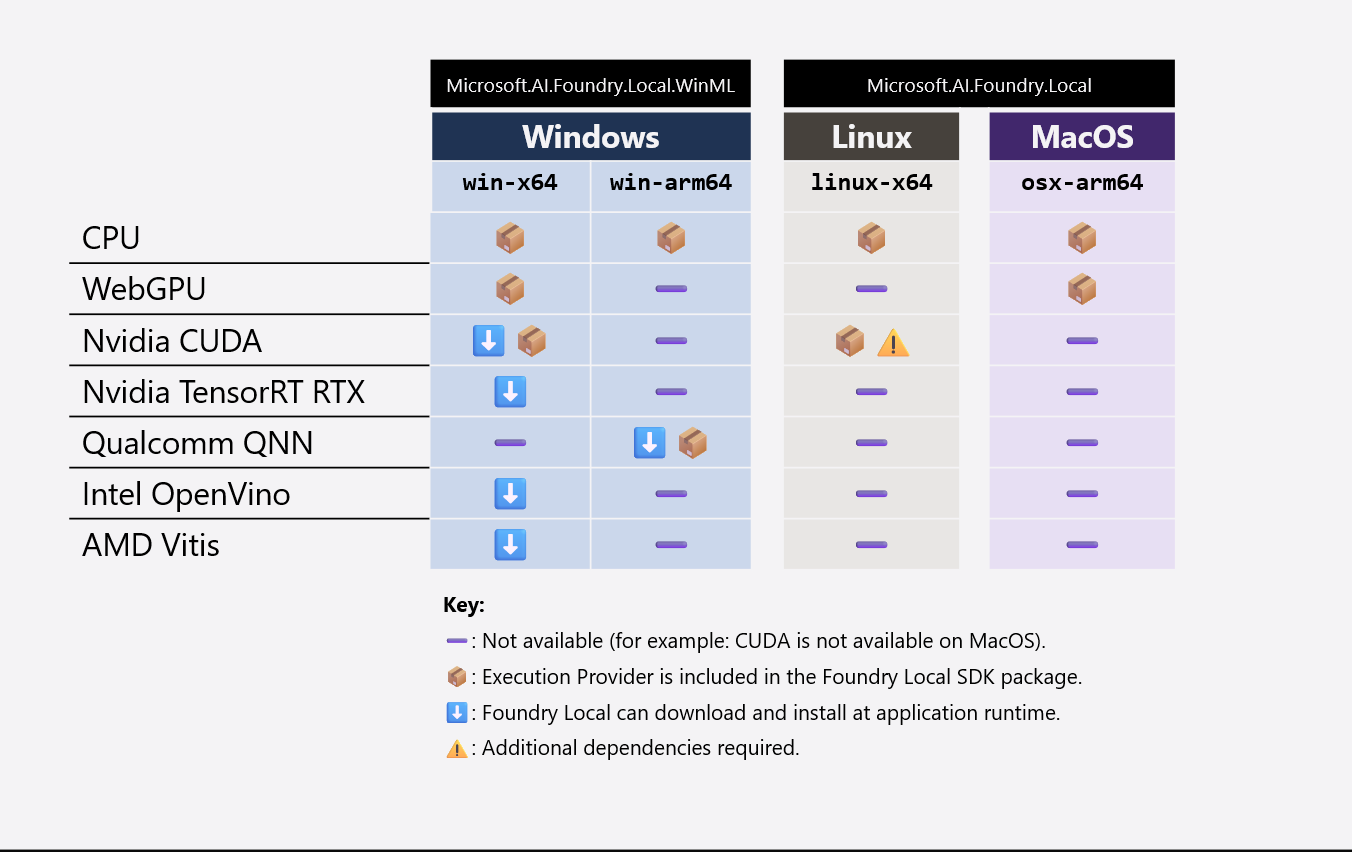
在所有平台與架構中,CPU EP 都是必備的。 WebGPU EP 和 IHV 函式庫體積較小(例如 WebGPU 只會為你的應用程式套件增加 ~7MB),且在 Windows 和 macOS 中是必備的。 然而,CUDA 和 QNN EP 體積較大(例如 CUDA 會為你的應用程式套件增加 ~1GB),因此我們建議將這些 EP 排除在你的應用程式套件之外。 如果終端使用者硬體相容,WinML 會在執行時下載/安裝 CUDA 和 QNN。
備註
我們正在計劃在未來版本中從 Microsoft.ML.OnnxRuntime.Foundry 套件中移除 CUDA 和 QNN EP,這樣你就不需再透過包含 ExcludeExtraLibs.props 檔案來將它們從應用程式套件中移除。
為了縮小應用程式套件的大小,您可以在專案目錄中建立 ExcludeExtraLibs.props 一個包含以下內容的檔案,當您發布應用程式時,這些檔案會排除 CUDA 和 QNN EP 及 IHV 函式庫:
<Project>
<!-- we want to ensure we're using the onnxruntime libraries from Foundry Local Core so
we delete the WindowsAppSdk versions once they're unzipped. -->
<Target Name="ExcludeOnnxRuntimeLibs" AfterTargets="ExtractMicrosoftWindowsAppSDKMsixFiles">
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime.dll"/>
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime_providers_shared.dll"/>
<Message Importance="Normal" Text="Deleted onnxruntime libraries from $(MicrosoftWindowsAppSDKMsixContent)." />
</Target>
<!-- Remove CUDA EP and IHV libraries on Windows x64 -->
<Target Name="ExcludeCudaLibs" Condition="'$(RuntimeIdentifier)'=='win-x64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<!-- match onnxruntime*cuda.* (we're matching %(Filename) which excludes the extension) -->
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^onnxruntime.*cuda.*', RegexOptions.IgnoreCase))" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime CUDA libraries from package." />
</Target>
<!-- Remove QNN EP and IHV libraries on Windows arm64 -->
<Target Name="ExcludeQnnLibs" Condition="'$(RuntimeIdentifier)'=='win-arm64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)%(Extension)',
'^QNN.*\.dll', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^libQNNhtp.*', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="'%(FileName)%(Extension)' == 'onnxruntime_providers_qnn.dll'" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime QNN libraries from package." />
</Target>
<!-- need to manually copy on linux-x64 due to the nuget packages not having the correct props file setup -->
<ItemGroup Condition="'$(RuntimeIdentifier)' == 'linux-x64'">
<!-- 'Update' as the Core package will add these dependencies, but we want to be explicit about the version -->
<PackageReference Update="Microsoft.ML.OnnxRuntime.Gpu" />
<PackageReference Update="Microsoft.ML.OnnxRuntimeGenAI.Cuda" />
<OrtNativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntime.gpu.linux/$(OnnxRuntimeVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
<OrtGenAINativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntimegenai.cuda/$(OnnxRuntimeGenAIVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
</ItemGroup>
<Target Name="CopyOrtNativeLibs" AfterTargets="Build" Condition=" '$(RuntimeIdentifier)' == 'linux-x64'">
<Copy SourceFiles="@(OrtNativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
<Copy SourceFiles="@(OrtGenAINativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
</Target>
</Project>
在你的專案檔案.csproj中,新增以下一行以匯入ExcludeExtraLibs.props檔案:
<!-- other project file content -->
<Import Project="ExcludeExtraLibs.props" />
Windows:CUDA 依賴項
CUDA EP 會透過 Microsoft.ML.OnnxRuntime.Foundry拉入你的 Linux 應用程式,但我們不包含 IHV 函式庫。 若您希望讓具備 CUDA 功能的終端使用者享有更高效能,您需要 在您的應用程式中新增 以下 CUDA IHV 函式庫:
- CUBLAS v12.8.4(從 NVIDIA 開發者下載)
- cublas64_12.dll
- cublasLt64_12.dll
- CUDA RT v12.8.90(從 NVIDIA 開發者下載)
- cudart64_12.dll
- CUDNN v9.8.0(從 NVIDIA 開發者下載)
- cudnn_graph64_9.dll
- cudnn_ops64_9.dll
- cudnn64_9.dll
- CUDA FFT v11.3.3.83(從 NVIDIA 開發者下載
- cufft64_11.dll
警告
將 CUDA EP 和 IHV 函式庫加入您的應用程式,將您的應用程式套件容量增加 1GB。
範例
- 如需示範如何使用 Foundry Local C# SDK,請參閱 GitHub 上的 Foundry Local C# SDK 範例倉庫。
API 參考資料
- 欲了解更多 Foundry Local C# SDK 的詳細資訊,請參閱 Foundry Local C# SDK API REFERENCE。
Rust SDK 參考
Rust SDK for Foundry Local 提供一種方式來管理模型、控制快取,並與 Foundry Local 服務互動。
先決條件
- 安裝 Foundry Local,並確認
foundry指令可在你的PATH使用。 - 使用 Rust 1.70.0 或更新版本。
安裝
若要使用 Foundry Local Rust SDK,請將下列內容新增至 :Cargo.toml
[dependencies]
foundry-local = "0.1.0"
或者,您可以使用 cargo 新增 Foundry Local Crate。
cargo add foundry-local
快速入門
使用此摘要驗證 SDK 是否能啟動服務並讀取本地目錄。
use anyhow::Result;
use foundry_local::FoundryLocalManager;
#[tokio::main]
async fn main() -> Result<()> {
let mut manager = FoundryLocalManager::builder().bootstrap(true).build().await?;
let models = manager.list_catalog_models().await?;
println!("Catalog models available: {}", models.len());
Ok(())
}
當服務運行且目錄可用時,此範例會列印非零數字。
參考:
FoundryLocalManager
Foundry Local SDK 作業的管理員。
Fields
-
service_uri: Option<String>— Foundry 服務的 URI。 -
client: Option<HttpClient>— API 要求的 HTTP 用戶端。 -
catalog_list: Option<Vec<FoundryModelInfo>>— 目錄模型的快取清單。 -
catalog_dict: Option<HashMap<String, FoundryModelInfo>>— 目錄模型的快取字典。 -
timeout: Option<u64>— 選擇性 HTTP 用戶端逾時。
方法
pub fn builder() -> FoundryLocalManagerBuilder
為FoundryLocalManager建立新的建立器。pub fn service_uri(&self) -> Result<&str>
取得服務 URI。
返回: Foundry 服務的 URI。fn client(&self) -> Result<&HttpClient>
取得 HTTP 用戶端實例。
傳回:HTTP 用戶端。pub fn endpoint(&self) -> Result<String>
取得服務的端點。
返回: 端點 URL。pub fn api_key(&self) -> String
取得 API 金鑰以進行驗證。
返回: API 金鑰。pub fn is_service_running(&mut self) -> bool
檢查服務是否正在執行,並在找到時設定服務 URI。
返回:true如果正在執行,則為 ,false否則為 。pub fn start_service(&mut self) -> Result<()>
啟動 Foundry 本地服務。pub async fn list_catalog_models(&mut self) -> Result<&Vec<FoundryModelInfo>>
取得目錄中可用模型的清單。pub fn refresh_catalog(&mut self)
重新整理目錄快取。pub async fn get_model_info(&mut self, alias_or_model_id: &str, raise_on_not_found: bool) -> Result<FoundryModelInfo>
依別名或標識碼取得模型資訊。
引數:-
alias_or_model_id:別名或模型標識碼。 -
raise_on_not_found:若為 true,找不到時會傳回錯誤。
-
pub async fn get_cache_location(&self) -> Result<String>
以字串形式取得快取位置。pub async fn list_cached_models(&mut self) -> Result<Vec<FoundryModelInfo>>
列出快取的模型。pub async fn download_model(&mut self, alias_or_model_id: &str, token: Option<&str>, force: bool) -> Result<FoundryModelInfo>
下載模型。
引數:-
alias_or_model_id:別名或模型標識碼。 -
token:選擇性的驗證令牌。 -
force:如果已快取,則強制重新下載。
-
pub async fn load_model(&mut self, alias_or_model_id: &str, ttl: Option<i32>) -> Result<FoundryModelInfo>
載入模型以進行推斷。
引數:-
alias_or_model_id:別名或模型標識碼。 -
ttl:選擇性的存留時間,以秒為單位。
-
pub async fn unload_model(&mut self, alias_or_model_id: &str, force: bool) -> Result<()>
卸載模型。
引數:-
alias_or_model_id:別名或模型標識碼。 -
force:強制卸載,即便正在使用亦然。
-
pub async fn list_loaded_models(&mut self) -> Result<Vec<FoundryModelInfo>>
列出載入的模型。
FoundryLocalManagerBuilder
用於創建FoundryLocalManager實例的建構器。
Fields
-
alias_or_model_id: Option<String>— 要下載和載入的別名或模型識別碼。 -
bootstrap: bool— 如果未執行,是否要啟動此服務。 -
timeout_secs: Option<u64>— HTTP 用戶端逾時 (以秒為單位)。
方法
pub fn new() -> Self
建立新的產生器實例。pub fn alias_or_model_id(mut self, alias_or_model_id: impl Into<String>) -> Self
設定別名或模型標識碼以下載和載入。pub fn bootstrap(mut self, bootstrap: bool) -> Self
設定是否要在未執行時啟動服務。pub fn timeout_secs(mut self, timeout_secs: u64) -> Self
設定 HTTP 用戶端逾時 (以秒為單位)。pub async fn build(self) -> Result<FoundryLocalManager>
建置FoundryLocalManager實例。
FoundryModelInfo
表示模型的相關信息。
Fields
-
alias: String— 模型別名。 -
id: String— 模型標識碼。 -
version: String— 模型版本。 -
runtime: ExecutionProvider— 執行提供者(CPU、CUDA 等)。 -
uri: String— 模型 URI。 -
file_size_mb: i32— 以 MB 為單位模型檔案大小。 -
prompt_template: serde_json::Value— 模型的提示範本。 -
provider: String— 提供者名稱。 -
publisher: String— 發行者名稱。 -
license: String— 授權類型。 -
task: String— 模型工作(例如文字產生)。
方法
from_list_response(response: &FoundryListResponseModel) -> Self
從目錄回應建立FoundryModelInfo。to_download_body(&self) -> serde_json::Value
將模型資訊轉換為 JSON 主體以取得下載要求。
ExecutionProvider
列舉支援的執行提供者。
CPUWebGPUCUDAQNN
方法
get_alias(&self) -> String
傳回執行提供者的字串別名。
ModelRuntime
描述模型的運行時間環境。
device_type: DeviceTypeexecution_provider: ExecutionProvider