在 Azure HDInsight on AKS 中使用 Delta Lake 搭配 Apache Spark™ 叢集 (預覽)
注意
AKS 上的 Azure HDInsight 將於 2025 年 1 月 31 日退場。 請於 2025 年 1 月 31 日之前,將工作負載移轉至 Microsoft Fabric 或對等的 Azure 產品,以免工作負載突然終止。 訂用帳戶中剩餘的叢集將會停止,並會從主機移除。
在淘汰日期之前,只有基本支援可用。
重要
此功能目前為預覽功能。 Microsoft Azure 預覽版增補使用規定包含適用於 Azure 功能 (搶鮮版 (Beta)、預覽版,或尚未正式發行的版本) 的更多法律條款。 若需此特定預覽版的相關資訊,請參閱 Azure HDInsight on AKS 預覽版資訊。 如有問題或功能建議,請在 AskHDInsight 上提交要求並附上詳細資料,並且在 Azure HDInsight 社群上追蹤我們以獲得更多更新資訊。
Azure HDInsight on AKS 是一項適用於巨量資料分析的受控雲端式服務,可協助組織處理大量資料。 本教學課程說明如何在 Azure HDInsight on AKS 中使用 Delta Lake 搭配 Apache Spark™ 叢集。
必要條件
在 Azure HDInsight on AKS 中建立 Apache Spark™ 叢集

在 Jupyter Notebook 中執行 Delta Lake 案例。 建立 Jupyter Notebook 並在建立筆記本時選取 [Spark],因為下列範例位於 Scala 中。



案例
- 讀取 NYC 計程車 Parquet 資料格式 - Parquet 檔案 URL 清單是由 NYC 計程車和豪華轎車委員提供。
- 針對每個 URL (檔案) 執行一些轉換並以 Delta 格式儲存。
- 從使用累加式載入的 Delta 資料表,計算平均距離、每英里的平均成本以及平均成本。
- 將步驟 3 的計算值以 Delta 格式儲存在 KPI 輸出資料夾中。
- 在 Delta 格式輸出資料夾上建立 Delta 資料表 (自動重新整理)。
- KPI 輸出資料夾具有多個版本的平均距離,以及一趟旅行每英里的平均成本。
提供 Delta Lake 的需求組態
包含 Apache Spark 相容性矩陣的 Delta Lake - Delta Lake,根據 Apache Spark 版本變更 Delta Lake 版本。
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

列出資料檔案
注意
這些檔案 URL 來自紐約市計程車和豪華轎車委員會。
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

建立輸出目錄
您想要建立 Delta 格式輸出的位置,視需要變更 transformDeltaOutputPath 和 avgDeltaOutputKPIPath 變數,
avgDeltaOutputKPIPath- 以 Delta 格式儲存平均 KPItransformDeltaOutputPath- 以 Delta 格式儲存轉換的輸出
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

從 Parquet 格式建立 Delta 格式資料
輸入資料來自
listOfDataFile,其中的資料下載自 https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page若要示範時間旅行和版本,請個別載入資料
對累加式載入執行轉換及計算下列商務 KPI:
- 平均距離
- 每英里的平均成本
- 平均成本
以 Delta 格式儲存已轉換和 KPI 資料
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
使用 Delta 資料表讀取 Delta 格式
- 讀取已轉換的資料
- 讀取 KPI 資料
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
列印結構描述
- 列印已轉換和平均 KPI 資料的 Delta 資料表結構描述。
// tranform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema
顯示資料表中上次計算的 KPI
dtAvgKpi.toDF.show(false)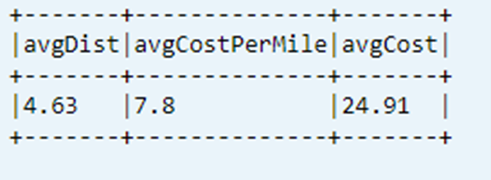


顯示計算 KPI 歷程記錄
此步驟會顯示來自 _delta_log 中 KPI 交易資料表的歷程記錄
dtAvgKpi.history().show(false)

在每次資料載入後顯示 KPI 資料
- 使用時間旅行,您可在每次載入後檢視 KPI 變更
- 您可以在
avgMoMKPIChangePath以 CSV 格式儲存所有的版本變更,讓 Power BI 可以讀取這些變更
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

參考
- Apache、Apache Spark、Spark 和相關聯的開放原始碼專案名稱為 Apache Software Foundation (ASF) 的商標。