在本文中,您將了解如何針對 Apache Hive 設定 Apache Ranger 原則。 您可建立兩個 Ranger 原則來限制對 hivesampletable 的存取。 hivesampletable 隨附 HDInsight 叢集。 設定原則之後,您可使用 Excel 和開放式資料庫連接 (ODBC) 驅動程式連線到 HDInsight 中的 Hive 資料表。
必要條件
- 具有企業安全性套件 (ESP) 的 HDInsight 叢集。 如需詳細資訊,請參閱設定具有 ESP 的 HDInsight 叢集。
- 具有企業版 Microsoft 365 應用程式、Office 2016、Office 2013 專業增強版、Excel 2013 獨立版或 Office 2010 專業增強版的工作站。
連線到 Apache Ranger 管理員 UI
若要連線到 Ranger 管理員使用者介面 (UI):
從瀏覽器移至位於
https://CLUSTERNAME.azurehdinsight.net/Ranger/的 Ranger 管理員 UI,其中CLUSTERNAME是您的叢集名稱。注意
Ranger 會使用與 Apache Hadoop 叢集不同的認證。 若要避免瀏覽器使用快取的 Hadoop 認證,請使用新的 InPrivate 瀏覽器視窗連線至 Ranger 管理員 UI。
使用叢集系統管理員網域使用者名稱和密碼進行登入:
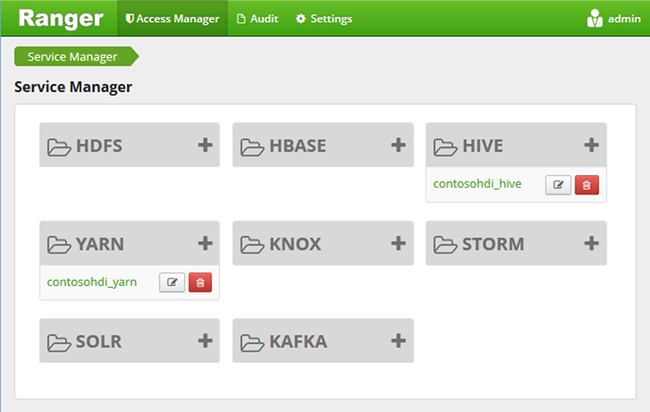
目前,Ranger 僅適用於 Yarn 和 Hive。
建立網域使用者
如需如何建立 hiveruser1 和 hiveuser2 的資訊,請參閱建立具有 ESP 的 HDInsight 叢集。 在本文中,您會使用兩個使用者帳戶。
建立 Ranger 原則
在這一節中,您會建立兩個 Ranger 原則以供存取 hivesampletable。 您會提供不同資料行集的選取權限。 兩個使用者都是使用建立具有 ESP 的 HDInsight 叢集中的指示建立。 在下一節中,您會在 Excel 中測試這兩個原則。
若要建立 Ranger 原則:
開啟 Ranger 管理員 UI。 請參閱上一節:連線到 Apache Ranger 管理員 UI。
選取 [Hive] 底下的 [CLUSTERNAME_Hive]。 您會看到兩個預先設定的原則。
選取 [新增原則],並輸入下列值︰
屬性 值 原則名稱 read-hivesampletable-all Hive 資料庫 預設值 table hivesampletable Hive 資料行 * 選取使用者 hiveuser1 權限 select 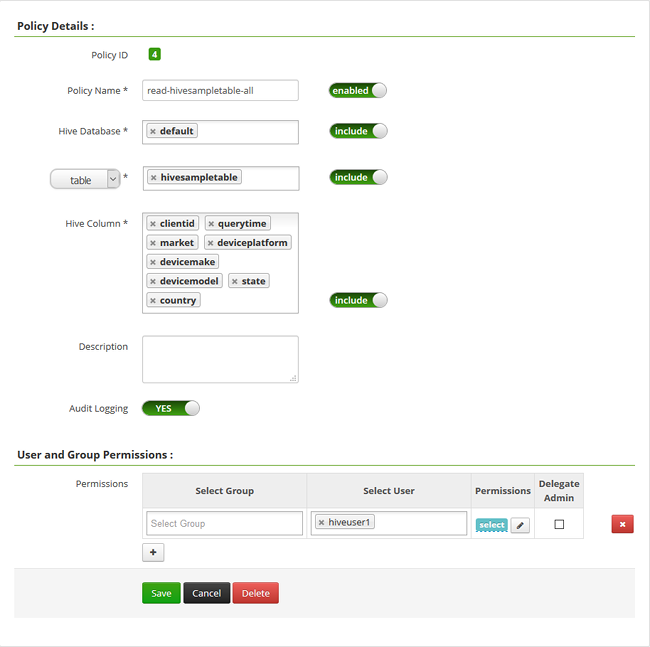 .
.注意
如果 [選取使用者] 中未填入網域使用者,請稍後,讓 Ranger 與 Microsoft Entra ID 同步處理。
選取 [新增] 以儲存規則。
重複最後兩個步驟,使用下列屬性建立另一個原則︰
屬性 值 原則名稱 read-hivesampletable-devicemake Hive 資料庫 預設值 table hivesampletable Hive 資料行 clientid、devicemake 選取使用者 hiveuser2 權限 select
建立 Hive ODBC 資料來源
如需如何建立 Hive ODBC 資料來源的指示,請參閱建立 Hive ODBC 資料來源。
| 屬性 | 說明 |
|---|---|
| 資料來源名稱 | 為資料來源指定名稱。 |
| Host | 輸入 CLUSTERNAME.azurehdinsight.net。 例如,使用 myHDICluster.azurehdinsight.net。 |
| 連接埠 | 使用 443 (此連接埠的範圍是 563 至 443。) |
| Database | 使用預設值 |
| Hive 伺服器類型 | 選取 [Hive Server 2]。 |
| 機制 | 選取 [Azure HDInsight 服務]。 |
| HTTP 路徑 | 保留為空白。 |
| 使用者名稱 | 輸入 hiveuser1@contoso158.onmicrosoft.com。 更新網域名稱 (如果不同的話)。 |
| 密碼 | 輸入 hiveuser1 的密碼。 |
儲存資料來源之前,請先選取 [測試]。
從 HDInsight 將資料匯入 Excel 中
在最後一個區段中,您已設定兩個原則:hiveuser1 具有所有資料行的選取權限,而 hiveuser2 具有兩個資料行的選取權限。 本節中,您可以模擬兩位使用者將資料匯入 Excel 中。
在 Excel 中開啟新的或現有的活頁簿。
在 [資料] 索引標籤上,移至 [取得資料]>[從其他來源]>[從 ODBC],以開啟 [從 ODBC] 視窗。
![顯示 [開啟數據連線精靈] 的螢幕快照。](media/apache-domain-joined-run-hive/simbahiveodbc-excel-dataconnection1.png)
從下拉式清單中,選取您在上一節建立的資料來源名稱,然後選取 [確定]。
第一次使用時,[ODBC 驅動程式] 對話方塊隨即開啟。 從左側功能表中選取 [Windows]。 然後,選取 [連線] 以開啟 [導覽器] 視窗。
等候
Select Database and Table對話框開啟。 此步驟可能需要幾秒鐘的時間。選取 [hivesampletable]>[下一步]。
選取 [完成]。
在 [匯入資料] 對話方塊中,您可以變更或指定查詢。 若要這樣做,請選取 [屬性]。 此步驟可能需要幾秒鐘的時間。
選取 [定義] 索引標籤。命令文字如下:
SELECT * FROM "HIVE"."default"."hivesampletable"`透過您定義的 Ranger 原則,
hiveuser1對所有資料行具有選取權限。 此查詢適用於hiveuser1的認證,但此查詢不適用於hiveuser2的認證。選取 [確定] 以關閉 [連接屬性] 對話方塊。
選取 [確定] 以關閉 [匯入資料] 對話方塊。
重新輸入
hiveuser1的密碼,然後選取 [確定]。 經過數秒後,資料即會匯入至 Excel。 完成後,您會看到 11 行的資料。
測試您在上一節中建立的第二個原則 (read-hivesampletable-devicemake):
在 Excel 中新增工作表。
依照上一個程序匯入資料。 您所做的唯一變更是使用
hiveuser2(而不是hiveuser1) 的認證。 此動作失敗,因為hiveuser2只具有兩個資料行的權限。 您看到下列錯誤:[Microsoft][HiveODBC] (35) Error from Hive: error code: '40000' error message: 'Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [hiveuser2] does not have [SELECT] privilege on [default/hivesampletable/clientid,country ...]'.依照相同程序匯入資料。 這次使用
hiveuser2的認證,而且修改 select 陳述式:SELECT * FROM "HIVE"."default"."hivesampletable"變更為:
SELECT clientid, devicemake FROM "HIVE"."default"."hivesampletable"完成後,您會看到兩個匯入的資料行。
下一步
- 若要設定具有 ESP 的 HDInsight 叢集,請參閱設定具有 ESP 的 HDInsight 叢集。
- 如需管理具有 ESP 的 HDInsight 叢集,請參閱管理具有 ESP 的 HDInsight 叢集。
- 如需在具有 ESP 的 HDInsight 叢集上使用 Secure Shell (SSH) 執行 Hive 查詢,請參閱使用 SSH 搭配 HDInsight。
- 若要使用 Hive Java 資料庫連線 (JDBC) 來連線 Hive,請參閱使用 Hive JDBC 驅動程式連線到 Azure HDInsight 上的 Apache Hive。
- 若要使用 Hive ODBC 將 Excel 連接到 Hadoop,請參閱使用 Microsoft Hive ODBC 驅動程式將 Excel 連接到 Apache Hadoop。
- 若要使用 Power Query 將 Excel 連接到 Apache Hadoop,請參閱使用 Power Query 將 Excel 連接到 Hadoop。