Azure HDInsight 的複製機制可整合進高可用性解決方案架構中。 本文以一個虛構的 Contoso Retail 案例研究,說明可能的高可用性災難復原方法、成本考量及其相應設計。
高可用性災難復原建議可以有多種組合與排列。 這些解決方案應在審議每個選項的優缺點後得出。 本文僅討論一種可能的解決方案。
客戶架構
下圖展示 Contoso 零售的主要建築。 架構包含串流工作負載、批次工作負載、服務層、消耗層、儲存層及版本控制。
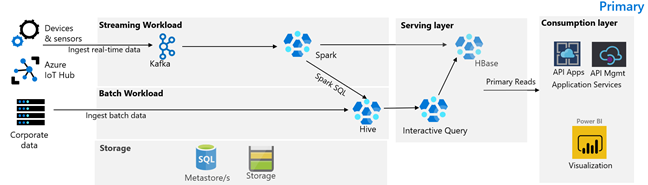
串流工作量
裝置與感測器將資料傳送至 HDInsight Kafka,構成訊息傳遞框架。 HDInsight Spark 取用者從 Kafka 主題讀取資料。 Spark 會轉換收到的訊息,並將其寫入服務層的 HDInsight HBase 叢集。
批次工作負載
運行 Hive 與 MapReduce 的 HDInsight Hadoop 叢集從本地交易系統擷取資料。 由 Hive 與 MapReduce 轉換的原始資料會儲存在資料湖邏輯分割區的 Hive 資料表中,該分區由 Azure Data Lake Storage Gen2 支援。 儲存在 Hive 資料表中的資料也會提供給 Spark SQL,SSQL 會先進行批次轉換,然後將精選資料儲存在 HBase 中以供服務。
服務層
HDInsight HBase 叢集搭配 Apache Phoenix 用於向網頁應用程式及視覺化儀表板提供資料。 HDInsight LLAP 叢集用於滿足內部報告需求。
消耗層
Azure API Apps 和 API 管理層支援面向公眾的網頁。 內部報告需求由 Power BI 完成。
儲存層
邏輯分割的 Azure Data Lake Storage Gen2 被用作企業級資料湖。 HDInsight 的元儲存庫是由 Azure SQL DB 支援的。
控制系統版本
一個整合在 Azure Pipelines 中,並託管於 Azure 外部的版本控制系統。
客戶業務持續性需求
確定如果發生災難時,您需要的最低業務功能非常重要。
Contoso Retail 的業務持續性要求
- 我們必須得到保護,以防地區性故障或地區服務健康問題。
- 我的客戶絕不能看到404錯誤。 公開內容必須隨時提供。 (RTO = 0)
- 在一年中的大部分時間內,我們可以顯示最多延遲 5 小時的公眾內容。 (RPO = 5小時)
- 在節慶季節,我們的面向公眾的內容必須始終保持最新。 (RPO = 0)
- 我的內部報告要求對業務持續性並不重要。
- 優化業務持續性成本。
建議的解決方案
以下圖片展示了 Contoso Retail 的高可用性災難復原架構。
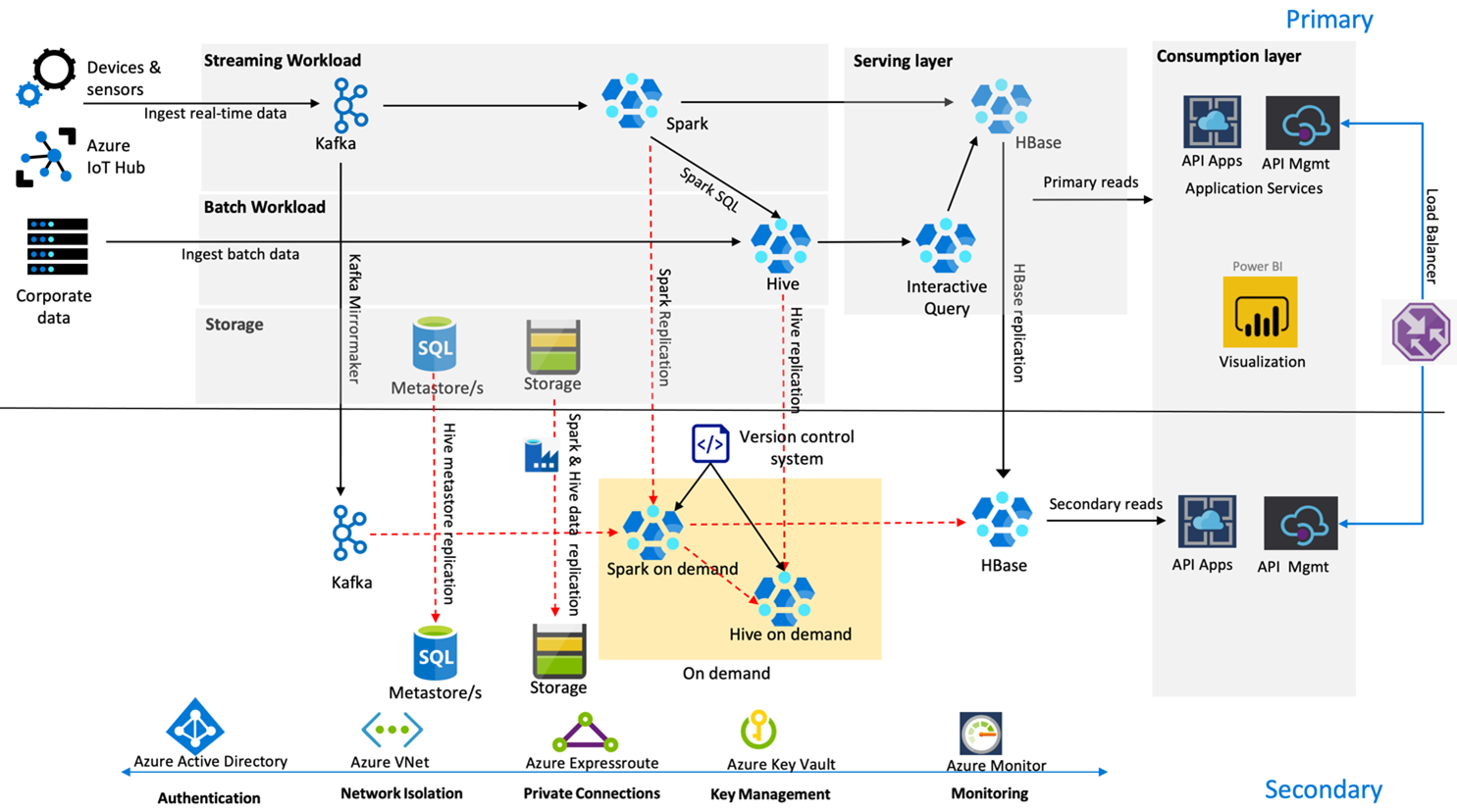
Kafka 採用 主動-被動 複製,將 Kafka 主題從主要區域鏡像到次要區域。 Kafka 複寫的替代方案是同時在兩個區域產生至 Kafka。
Hive 與 Spark 在正常時間內使用 Active Primary – On-Demand Secondary 複製模型。 Hive 複製流程會定期執行,並包含 Hive Azure SQL 中繼資料庫及 Hive 儲存帳戶的複製。 Spark 儲存帳號會定期使用 ADF DistCP 複製。 這些叢集的短暫性有助於優化成本。 系統每 4 小時排程一次複寫,以達成遠低於 5 小時需求的復原點目標。
HBase 複寫在正常情況下使用 Leader – Follower 模型,以確保無論區域為何都能提供資料,且復原點目標非常低。
若主區域發生區域故障,網頁及後端內容會由次要區域提供 5 小時,且有一定程度的停滯。 如果 Azure 服務健康儀表板在五小時內沒有顯示復原預計時間,Contoso Retail 會在次要區域建立 Hive 和 Spark 轉換層,然後將所有上游資料來源指向次要區域。 將次要區域設為可寫入會導致容錯移轉回復流程,並將資料複寫回主要區域。
在購物旺季,整個次級管線始終保持運作。 Kafka 產生者同時將資料寫入兩個區域,並將 HBase 複寫從領導者–追隨者變更為領導者–領導者,以確保面向公眾的內容保持最新。
內部報告無需設計備援解決方案,因為它對業務持續性並非關鍵。
後續步驟
若要深入了解本文中討論的項目,請參閱: