Azure HDInsight 支援的高可用性服務
為了為您提供分析元件的最佳可用性層級,HDInsight 是使用獨特的架構來開發,以確保重要服務的高可用性 (HA) 。 Microsoft 開發了此架構的一些元件,以提供自動故障轉移。 其他元件是部署以支援特定服務的標準 Apache 元件。 本文說明 HDInsight 中 HA 服務模型的架構、HDInsight 如何支援 HA 服務的故障轉移,以及從其他服務中斷中復原的最佳做法。
注意
本文包含「從屬」一詞的參考,Microsoft 已不再使用該字詞。 從軟體中移除該字詞時,我們也會將其從本文中移除。
高可用性基礎結構
HDInsight 提供自定義的基礎結構,以確保四個主要服務具有自動故障轉移功能的高可用性:
- Apache Ambari 伺服器
- Apache YARN 的應用程式時程表伺服器
- Hadoop MapReduce 的作業歷程記錄伺服器
- Apache Livy
此基礎結構包含許多服務和軟體元件,其中有些是由 Microsoft 所設計。 下列元件對 HDInsight 平臺而言是唯一的:
- 從屬故障轉移控制器
- 主要故障轉移控制器
- 從屬高可用性服務
- 主要高可用性服務
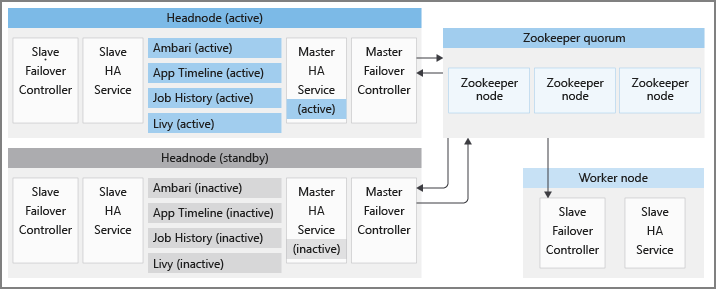
另外還有其他高可用性服務,由開放原始碼 Apache 可靠性元件支援。 這些元件也存在於 HDInsight 叢集上:
- Hadoop 文件系統 (HDFS) NameNode
- YARN ResourceManager
- HBase Master
下列各節提供這些服務如何共同運作的詳細數據。
HDInsight 高可用性服務
Microsoft 支援 HDInsight 叢集中下表中的四個 Apache 服務。 為了區分它們與 Apache 元件支援的高可用性服務,它們稱為 HDInsight HA 服務。
| 服務 | 叢集節點 | 叢集類型 | 目的 |
|---|---|---|---|
| Apache Ambari 伺服器 | 主動前端節點 | 全部 | 監視和管理叢集。 |
| Apache YARN 的應用程式時程表伺服器 | 主動前端節點 | Kafka 以外的所有 | 維護叢集上執行之 YARN 作業的偵錯資訊。 |
| Hadoop MapReduce 的作業歷程記錄伺服器 | 主動前端節點 | Kafka 以外的所有 | 維護 MapReduce 作業的偵錯數據。 |
| Apache Livy | 主動前端節點 | Spark | 透過 REST 介面與 Spark 叢集輕鬆互動 |
注意
HDInsight 企業安全性套件 (ESP) 叢集目前僅提供Ambari伺服器高可用性。 應用程式時間軸伺服器、作業歷程記錄伺服器和 Livy 全都只在 headnode0 上執行,而且當 Ambari 故障轉移時,它們不會故障轉移至 headnode1。 應用程式時間軸資料庫也位於 headnode0 上,而不是在 Ambari SQL Server 上。
架構
每個 HDInsight 叢集分別有兩個作用中和待命模式的前端節點。 HDInsight HA 服務只會在前端節點上執行。 這些服務應該一律在作用中的前端節點上執行,並停止並置於待命前端節點上的維護模式。
為了維護正確的HA服務狀態並提供快速故障轉移,HDInsight會利用Apache ZooKeeper,這是分散式應用程式的協調服務,可進行主動前端節點選舉。 HDInsight 也會布建幾個背景 Java 程式,以協調 HDInsight HA 服務的故障轉移程式。 這些服務包括:主要故障轉移控制器、從屬故障轉移控制器、 master-ha-service 和 從屬 ha-service。
Apache ZooKeeper
Apache ZooKeeper 是分散式應用程式的高效能協調服務。 在生產環境中,ZooKeeper 通常會以複寫模式執行,其中已復寫的 ZooKeeper 伺服器群組會形成仲裁。 每個 HDInsight 叢集都有三個 ZooKeeper 節點,可讓三部 ZooKeeper 伺服器形成仲裁。 HDInsight 有兩個 ZooKeeper 報價彼此平行執行。 一個仲裁決定叢集中應該執行 HDInsight HA 服務的作用中前端節點。 另一個仲裁是用來協調Apache所提供的HA服務,如後續小節所述。
從屬故障轉移控制器
從屬故障轉移控制器會在 HDInsight 叢集中的每個節點上執行。 此控制器負責在每個節點上啟動Ambari代理程式和 從屬ha-service 。 它會定期查詢有關使用中前端節點的第一個 ZooKeeper 仲裁。 當作用中和待命前端節點變更時,從屬故障轉移控制器會執行下列步驟:
- 更新 主機組態檔。
- 重新啟動Ambari代理程式。
從 屬ha-service 負責停止待命前端節點上的 HDInsight HA 服務(Ambari 伺服器除外)。
主要故障轉移控制器
主要故障轉移控制器會在兩個前端節點上執行。 這兩個主要故障轉移控制器會與第一個 ZooKeeper 仲裁通訊,以提名其作為作用中前端節點執行的前端節點。
例如,如果前端節點 0 上的主要故障轉移控制器贏得選舉,就會進行下列變更:
- 前端節點 0 變成作用中。
- 主要故障轉移控制器會啟動前端節點 0 上的 Ambari 伺服器和 master-ha-service 。
- 另一個主要故障轉移控制器會停止前端節點 1 上的Ambari伺服器和 master-ha-service 。
master-ha-service 只會在作用中的前端節點上執行,它會停止待命前端節點上的 HDInsight HA 服務(Ambari 伺服器除外),並在作用中前端節點上啟動它們。
故障轉移程式
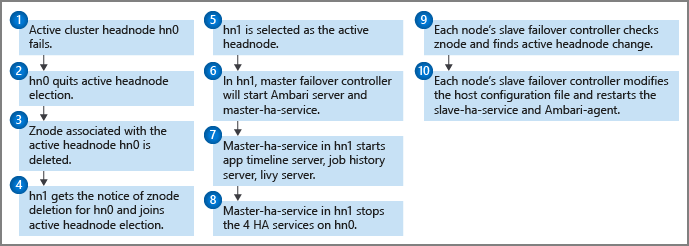
健康情況監視器會在每個前端節點上以及主要故障轉移控制器上執行,以將活動訊號通知傳送至 Zookeeper 仲裁。 前端節點在此案例中被視為HA服務。 健康情況監視器會檢查每個高可用性服務是否狀況良好,以及是否準備好加入領導選舉。 如果是,這個頭節點在選舉中競爭。 如果沒有,它退出選舉,直到它再次準備好。
如果待命前端節點曾經達到領導地位並變成作用中(例如在先前作用中節點失敗的情況下),其主要故障轉移控制器會在其上啟動所有 HDInsight HA 服務。 主要故障轉移控制器會停止其他前端節點上的這些服務。
針對 HDInsight HA 服務失敗,例如服務關閉或狀況不良,主要故障轉移控制器應該根據前端節點狀態自動重新啟動或停止服務。 用戶不應該在兩個前端節點上手動啟動 HDInsight HA 服務。 相反地,允許自動或手動故障轉移來協助服務復原。
不小心手動介入
HDInsight HA 服務應該只在作用中的前端節點上執行,並在必要時自動重新啟動。 由於個別HA服務沒有自己的健康情況監視器,因此無法在個別服務層級觸發故障轉移。 故障轉移可確保在節點層級,而不是在服務層級進行。
一些已知問題
在待命前端節點上手動啟動HA服務時,它不會停止,直到下一次故障轉移發生為止。 當HA服務在這兩個前端節點上執行時,一些潛在的問題包括:無法存取Ambari UI、Ambari擲回錯誤、YARN、Spark和 Oozie 作業可能會停滯。
當作用中前端節點上的HA服務停止時,它不會重新啟動,直到下一次故障轉移發生或主要故障轉移控制器/master-ha-service 重新啟動為止。 當作用中前端節點上有一或多個HA服務停止時,特別是當Ambari伺服器停止時,無法存取Ambari UI,其他潛在問題包括YARN、Spark和 Oozie 作業失敗。
Apache 高可用性服務
Apache 提供 HDFS NameNode、YARN ResourceManager 和 HBase Master 的高可用性,HDInsight 叢集中也提供。 不同於 HDInsight HA 服務,ESP 叢集中支持它們。 Apache HA 服務會與第二個 ZooKeeper 仲裁通訊(如上一節所述),以選取作用中/待命狀態並執行自動故障轉移。 下列各節將詳細說明這些服務的運作方式。
Hadoop 分散式文件系統 (HDFS) NameNode
以 Apache Hadoop 2.0 或更新版本為基礎的 HDInsight 叢集提供 NameNode 高可用性。 前端節點上有兩個 NameNode 正在執行,這些節點已設定為自動故障轉移。 NameNodes 會使用 ZKFailoverController 與 Zookeeper 通訊,以選擇作用中/待命狀態。 ZKFailoverController 會在兩個前端節點上執行,而且運作方式與主要故障轉移控制器相同。
第二個 Zookeeper 仲裁與第一個仲裁無關,因此使用中 NameNode 可能不會在作用中前端節點上執行。 當作用中的 NameNode 已失效或狀況不良時,待命 NameNode 會贏得選舉並變成作用中。
YARN ResourceManager
以 Apache Hadoop 2.4 或更高版本為基礎的 HDInsight 叢集支援 YARN ResourceManager 高可用性。 有兩個 ResourceManagers,rm1 和 rm2,分別在前端節點 0 和前端節點 1 上執行。 如同 NameNode,YARN ResourceManager 也會設定為自動故障轉移。 當目前的使用中 ResourceManager 關閉或沒有回應時,系統會自動選取另一個 ResourceManager 為使用中。
YARN ResourceManager 使用其內嵌 的 ActiveStandbyElector 作為失敗偵測器和領導者選民。 不同於 HDFS NameNode,YARN ResourceManager 不需要個別的 ZKFC 精靈。 使用中的 ResourceManager 會將狀態寫入 Apache Zookeeper。
YARN ResourceManager 的高可用性與 NameNode 和其他 HDInsight HA 服務無關。 使用中的 ResourceManager 可能不會在作用中前端節點或作用中 NameNode 執行所在的前端節點上執行。 如需 YARN ResourceManager 高可用性的詳細資訊,請參閱 ResourceManager 高可用性。
HBase Master
HDInsight HBase 叢集支援 HBase Master 高可用性。 與其他在前端節點上執行的HA服務不同,HBase Masters會在三個 Zookeeper 節點上執行,其中一個是作用中主機,另外兩個則是待命。 如同 NameNode,HBase Master 會與 Apache Zookeeper 協調進行領導者選舉,並在目前作用中主要主機發生問題時自動故障轉移。 隨時只有一個作用中的 HBase Master。
下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應