Azure HDInsight 中的 Apache Phoenix
Apache Phoenix 是建置在 Apache HBase 上的開放原始碼、大規模平行關聯式資料庫層。 Phoenix 可讓您透過 HBase 使用類似 SQL 的查詢。 Phoenix 使用下方的 JDBC 驅動程式,讓使用者建立、刪除及更改 SQL 資料表、索引、檢視表和序列,以及個別或大量更新插入資料列。 Phoenix 會使用 noSQL 原生編譯 (而不是使用 MapReduce) 來編譯查詢,以在 HBase 上建立低延遲的應用程式。 Phoenix 新增了副處理器,以支援在伺服器的位址空間中執行用戶端提供的程式碼,並執行與資料共置的程式碼。 這種方法可將用戶端/伺服器資料傳輸降至最低。
Apache Phoenix 會對非開發人員 (他可以使用類似 SQL 的語法而不是程式設計) 開啟巨量資料查詢。 Phoenix 已針對 HBase 高度最佳化,不同於 Apache Hive 和 Apache Spark SQL 等其他工具。 開發人員的優勢是可以使用較少的程式碼寫入較高效能的查詢。
當您提交 SQL 查詢時,Phoenix 會將查詢編譯至 HBase 原生呼叫,並且以平行方式執行掃描 (或計劃) 以獲得最佳化。 這個抽象層可以讓開發人員免於寫入 MapReduce 作業,轉而將焦點放在 Phoenix 巨量資料儲存體周圍應用程式的商務邏輯和工作流程。
查詢效能最佳化和其他功能
Apache Phoenix 會將數個效能增強和功能新增至 HBase 查詢。
次要索引
HBase 有單一索引,依辭典編纂順序儲存在主要資料列索引鍵。 只能透過資料列索引鍵存取這些記錄。 透過任何資料行 (而非資料列索引鍵) 存取記錄需要在套用所需的篩選條件時掃描所有資料。 在次要索引中,從替代數據列索引鍵編製索引的數據行或表示式,允許在該索引上進行查閱和範圍掃描。
使用 CREATE INDEX 命令建立次要索引:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
相較於執行單一索引查詢,這種方法可以產生顯著的效能提升。 這種類型的次要索引是涵蓋索引,包含查詢中所含的所有資料行。 因此,不需要資料表查閱,索引就可以滿足整個查詢。
檢視
Phoenix 檢視提供克服 HBase 限制的方法,此限制是當您建立超過約 100 個實體資料表時,效能就會開始降低。 Phoenix 檢視可以讓多個虛擬資料表共用一個基礎實體 HBase 資料表。
建立 Phoenix 檢視類似於使用標準的 SQL 檢視語法。 其中一個差異是除了從其基底資料表繼承的資料行以外,您還可以針對檢視定義資料行。 您也可以新增 KeyValue 資料行。
例如,以下是名為 product_metrics 且具有下列定義的實體數據表:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
在此資料表上定義檢視,其中包含更多資料列:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
若要稍後新增更多資料行,請使用 ALTER VIEW 陳述式。
略過掃描
略過掃描會使用一或多個複合式索引的資料行來尋找相異值。 不同於範圍掃描,略過掃描會實作資料列內部掃描,產生更佳的效能。 當您掃描時,會略過第一個相符的值以及索引,直到找到下一個值為止。
略過掃描會使用 HBase 篩選的 SEEK_NEXT_USING_HINT 列舉。 略過掃描會使用 SEEK_NEXT_USING_HINT,追蹤每個資料行中搜尋的索引鍵集合或索引鍵範圍。 然後略過掃描會取用在篩選評估期間傳遞給它的索引鍵,並且判斷它是否為其中一個組合。 如果不是,略過掃描會評估下一個最高索引鍵,並跳至該處。
交易
HBase 提供資料列層級交易,而 Phoenix 會與 Tephra 整合,以使用完整 ACID 語意新增跨資料列和跨資料表交易支援。
如同傳統的 SQL 交易,透過 Phoenix 交易管理員所提供的交易可讓您確保數據不可部分完成的單位已成功向上插入,如果在任何啟用交易的數據表上失敗,則會回復交易。
若要啟用 Phoenix 交易,請參閱 Apache Phoenix 交易文件。
若要建立已啟用交易的新資料表,在 CREATE 陳述式中將 TRANSACTIONAL 屬性設為 true:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
若要將現有資料表改變為交易式,使用 ALTER 陳述式中的相同屬性:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
注意
您無法將交易式資料表切換回非交易式。
進行 Salt 處理的資料表
將具有循序索引鍵的記錄寫入至 HBase 時可能會出現區域伺服器作用區。 雖然您在叢集中可能有多個區域伺服器,但是您的寫入只會在其中一個伺服器中發生。 此集中情形會產生作用區問題,其中您的寫入工作負載並非分散到所有可用的區域伺服器,而是只有一個伺服器會處理負載。 因為區域具有預先定義的大小上限,當區域達到該大小限制時,它會分割成兩個小區域。 發生這種情況時,其中一個新區域會採用所有新的記錄,變成新的作用區。
若要減輕這個問題並達到更佳的效能,請預先分割資料表,讓所有區域伺服器的使用都相等。 Phoenix 提供以 Salt 處理的資料表,明確地將已 Salt 處理的位元組新增至特定資料表的資料列索引鍵。 資料表是在 Salt 位元組界限上預先分割,以確保在資料表初始階段期間,區域伺服器之間的負載分配相等。 這種方法會將寫入工作負載散佈到所有可用的區域伺服器,改善寫入和讀取效能。 若要以 Salt 處理資料表,在建立資料表時指定 SALT_BUCKETS 資料表屬性:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
使用 Apache Ambari 啟用並調整 Phoenix
HDInsight HBase 叢集包括 Ambari UI,可進行設定變更。
若要啟用或停用 Phoenix,並且控制 Phoenix 的查詢逾時設定,使用您的 Hadoop 使用者認證登入 Ambari Web UI (
https://YOUR_CLUSTER_NAME.azurehdinsight.net)。從左側功能表中的服務清單選取 [HBase],然後選取 [設定] 索引標籤。
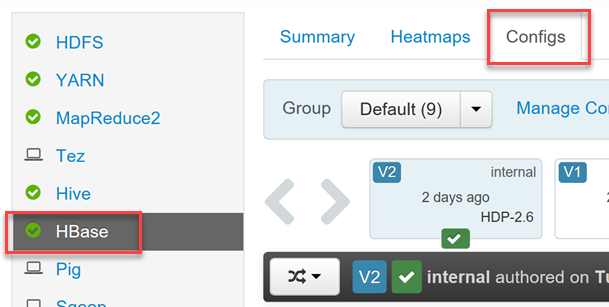
尋找 Phoenix SQL 設定區段以啟用或停用 Phoenix,並且設定查詢逾時。