本文討論如何優化 Apache Spark 叢集的記憶體管理,以在 Azure HDInsight 上獲得最佳效能。
概觀
Spark 透過將資料放入記憶體來運作。 因此,管理記憶體資源是最佳化 Spark 作業執行的關鍵層面。 有數種技術可以有效使用叢集的記憶體。
- 偏好較小的資料分割區,並在分割策略中考量資料大小、類型和發佈。
- 請考慮較新、更高效的
Kryo data serialization,而不是預設的 Java 序列化。 - 建議使用 YARN,因為它按批次分隔
spark-submit。 - 監視和微調 Spark 組態設定。
下圖顯示 Spark 記憶體結構,以及部分索引鍵執行程式記憶體參數,以供您參考。
Spark 記憶體考量
如果您使用 Apache Hadoop YARN,則 YARN 會控制每個 Spark 節點上所有容器所使用的記憶體。 下圖顯示索引鍵物件及其關聯性。
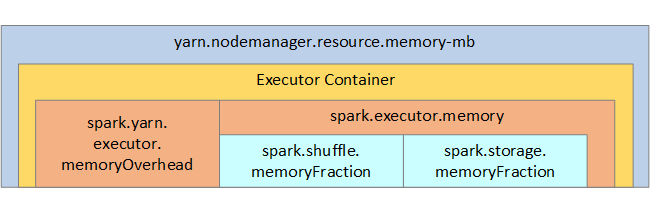
若要處理「記憶體不足」訊息,請嘗試:
- 檢閱 DAG 管理重組。 以對應端減少、預先分割 (或貯體分類) 來源資料加以減少、最大化單一重組,並減少傳送的資料量。
- 首選
ReduceByKey,因其具有固定的記憶體限制,相較之下,GroupByKey提供聚合、視窗和其他功能,但具有無界的記憶體限制。 - 偏好對於執行程式或資料分割進行較多作業的
TreeReduce,而不偏好對於驅動程式進行所有作業的Reduce。 - 使用 DataFrames 而不是較低層級的 RDD 物件。
- 建立封裝動作的 ComplexTypes,例如「前 N 項」、各種彙總或視窗化作業。
如需其他疑難排解步驟,請參閱 Azure HDInsight 中 Apache Spark 的 OutOfMemoryError 例外狀況。