代理程式資源是定義 MQTT 代理程式整體設定的主要資源。 它也會決定執行代理程式組態的 Pod 數目和類型,例如前端和後端。 您也可以使用代理程式資源來設定其記憶體設定檔。 自我修復機制內建於訊息代理程式,而且通常可以從元件失敗中自動復原。 例如,針對高可用性設定的 Kubernetes 叢集中,節點會失敗。
您可以藉由新增更多前端複本和後端分割區,水平調整 MQTT 代理程式。 前端複本負責接受來自用戶端的 MQTT 連線,並將其轉送至後端分割區。 後端分割區負責儲存和傳遞訊息給用戶端。 前端 Pod 會將訊息流量散佈到後端 Pod。 後端備援因數會決定資料複本數目,以針對叢集中的節點失敗提供復原能力。
如需可用設定的清單,請參閱代理程式 API 參考。
設定縮放設定
重要事項
此設定會要求您修改代理程式資源。 它只會使用 Azure CLI 或 Azure 入口網站,在初始部署時進行設定。 如果需要代理程式設定變更,則需要新的部署。 若要深入了解,請參閱自訂預設代理人。
若要設定 MQTT 代理程式的調整設定,請在 Azure IoT 操作部署期間指定代理程式資源的規格中的基數欄位。
自動部署基數
若要在部署期間自動判斷初始基數,請省略代理程式資源中的基數欄位。
當您透過 Azure 入口網站部署 IoT 操作時,尚不支援自動基數。 您可以手動將叢集部署模式指定為單一節點或多節點。 若要深入了解,請參閱部署 Azure IoT 操作 (部分內容可能是機器或 AI 翻譯)。
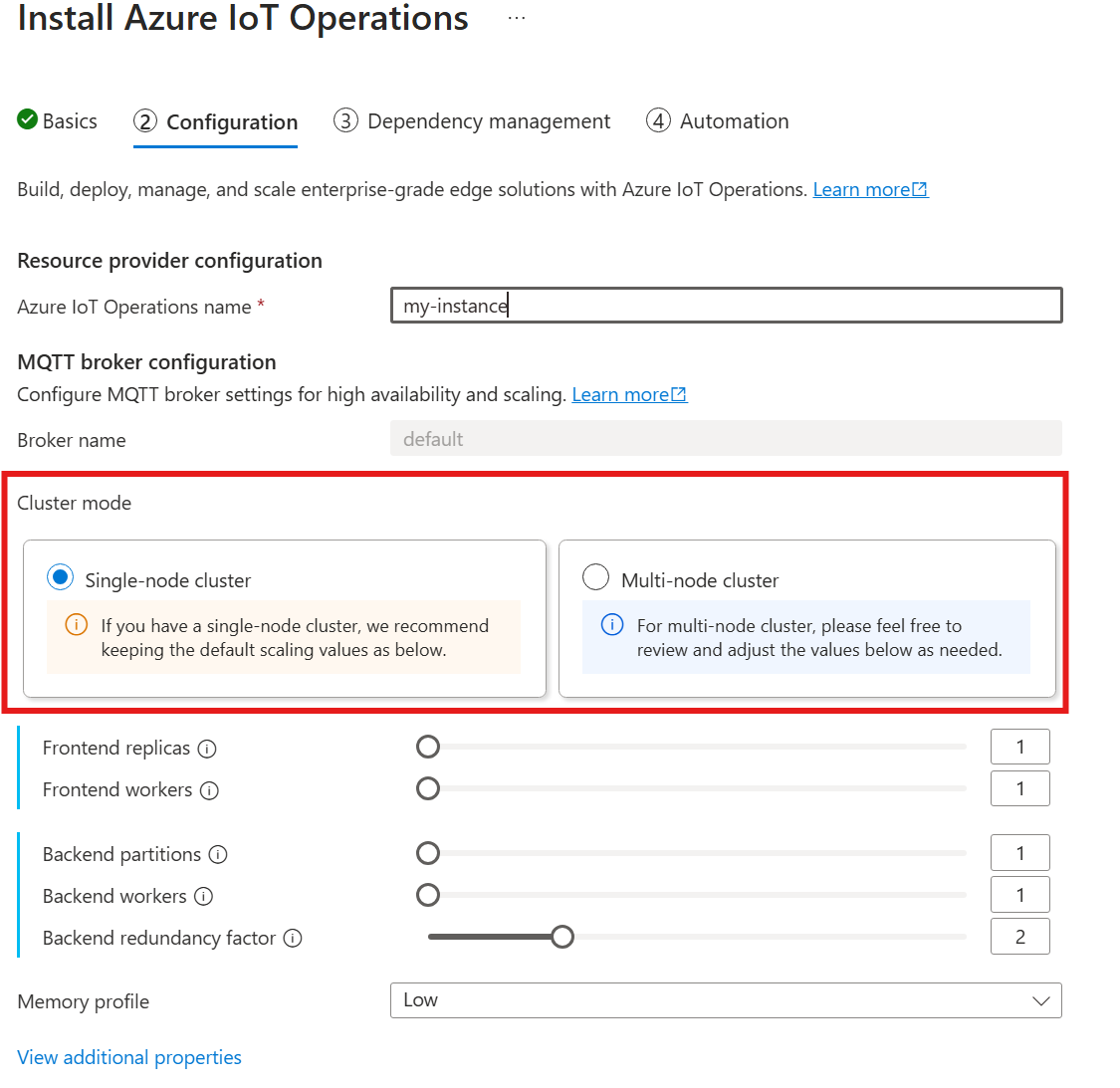
MQTT 代理程式運算子會根據部署時可用的節點數目,自動部署適當的 Pod 數目。 這項功能適用於您不需要高可用性或調整的非生產案例。
這項功能不會自動調整。 運算子不會根據負載自動調整 Pod 數目。 運算子會根據叢集硬體決定要部署的初始 Pod 數目。 如先前所述,基數只會在初始部署時設定。 如果需要變更基數設定,則需要新的部署。
直接設定基數
若要直接設定基數設定,請指定每個基數欄位。
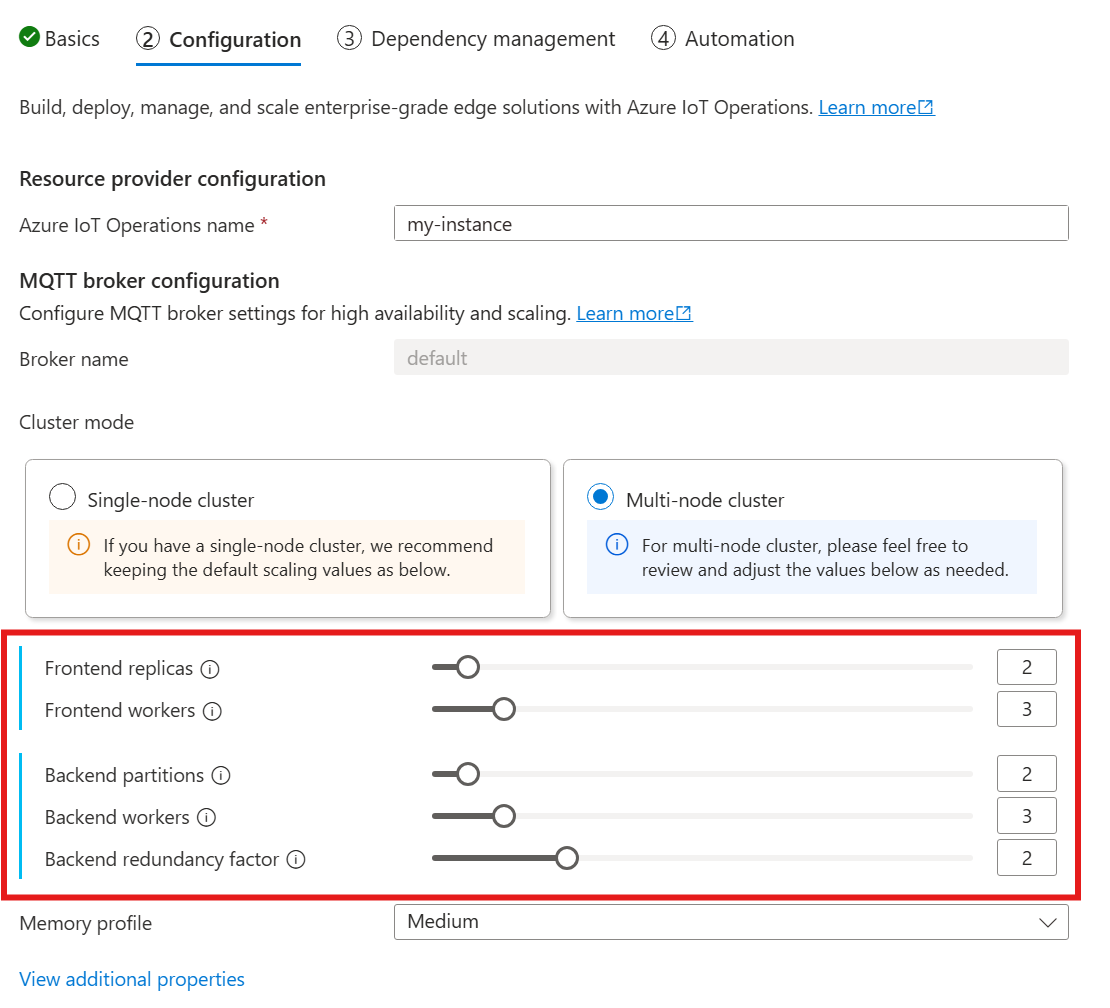
了解基數
基數表示集合中特定實體的執行個體數目。 在 MQTT 代理程式的內容中,基數是指要部署的前端複本、後端分割區和後端背景工作角色的數目。 基數設定是用來水平調整代理程式,並在發生 Pod 或節點失敗時改善高可用性。
基數欄位是巢狀欄位,具有前端和後端鏈結的子欄位。 每個子欄位都有自己的設定。
前端
前端子欄位會定義前端 Pod 的設定。 這兩個主要設定如下:
- 複本:要部署的前端複本 (Pod) 數目。 增加前端複本數目可提供高可用性,以防其中一個前端 Pod 失敗。
- 背景工作角色:每個複本的邏輯前端背景工作角色數目。 每個背景工作角色最多可以取用一個 CPU 核心。
後端鏈結
後端鏈結子欄位會定義後端分割區的設定。 三個主要設定如下:
- 分割區:要部署的分割區數目。 透過稱為分區化的程序,每個分割區會負責部分訊息,依主題識別碼和工作階段識別碼分割。 前端 Pod 會將訊息流量散佈到分割區之間。 增加分割區數目會增加代理程式可以處理的訊息數目。
- 備援因數:每個分割區要部署的後端複本 (Pod) 數目。 增加備援因數會增加資料複本數目,以針對叢集中的節點失敗提供復原能力。
- 背景工作角色:每個後端複本要部署的背景工作角色數目。 增加每個後端複本的背景工作角色數目可能會增加後端 Pod 可以處理的訊息數目。 每個背景工作角色最多可以取用兩個 CPU 核心,因此當您增加每個複本的背景工作角色數目時,請小心不要超過叢集中的 CPU 核心數目。
考量
當您增加基數值時,代理程式處理更多連線和訊息的能力通常會改善,如果 Pod 或節點失敗,則會增強高可用性。 此增加的容量也會導致較高的資源使用量。 因此,當您調整基數值時,請考慮記憶體設定檔設定和代理程式的 CPU 資源要求。 如果您發現前端 CPU 使用率是瓶頸,增加每個前端複本的背景工作角色數目,有助於增加 CPU 核心使用率。 如果後端 CPU 使用率是瓶頸,增加後端背景工作角色數目有助於訊息輸送量。
例如,如果您的叢集有三個節點,每個節點都有八個 CPU 核心,則設定前端複本數目以符合節點數目 (3),並將背景工作角色數目設定為 1。 設定後端分割區數目以符合節點數目 (3),並將後端背景工作角色設定為 1。 視需要設定備援因數 (2 或 3)。 如果您發現前端 CPU 使用率是瓶頸,請增加前端背景工作角色的數目。 請記住,後端和前端背景工作角色可能會與彼此和其他 Pod 競爭 CPU 資源。
設定記憶體設定檔
記憶體配置檔會針對資源有限的環境指定訊息代理程式記憶體使用量。 您可以選擇具有不同記憶體使用量特性的預先定義記憶體設定檔。 記憶體配置檔設定可用來設定前端和後端復本的記憶體使用量。 記憶體設定檔會與基數設定互動,以判斷代理程式的記憶體使用量總計。
重要事項
此設定會要求您修改代理程式資源。 它只會使用 Azure CLI 或 Azure 入口網站,在初始部署時進行設定。 如果需要代理程式設定變更,則需要新的部署。 若要深入了解,請參閱自訂預設代理人。
若要設定 MQTT 代理程式的記憶體設定檔設定,請在 IoT 操作部署期間指定代理程式資源的規格中的記憶體設定檔欄位。
當您使用下列指南來部署 IoT 操作時,請在 [設定] 區段中查看 [MQTT 代理程式設定],並尋找 [記憶體設定檔] 設定。 在這裡,您可以從下拉式清單中的可用記憶體設定檔中選取。
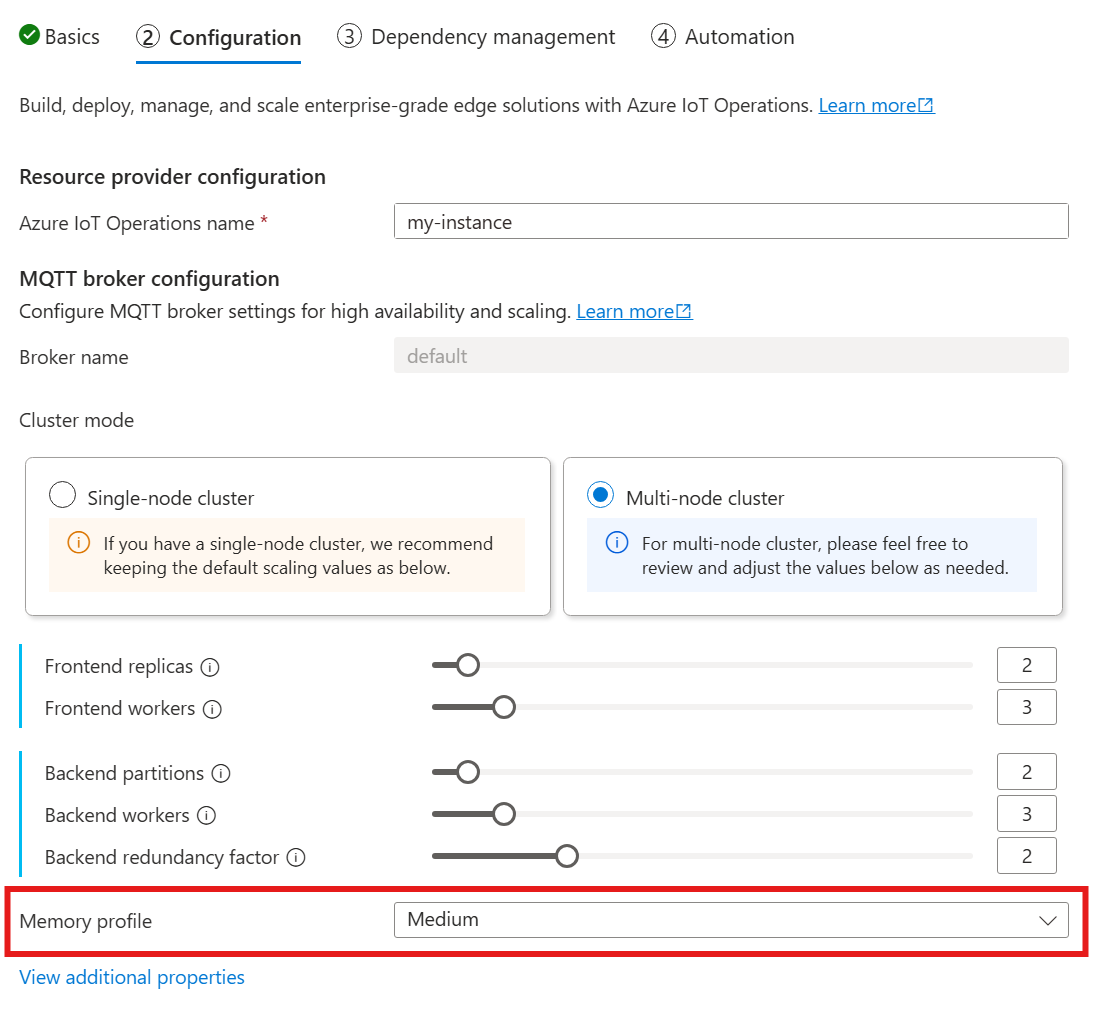
有預先定義的記憶體配置檔,具有發行訊息的不同記憶體使用量特性。 代理程式可以處理的會話或訂用帳戶數量沒有上限。 記憶體配置檔只會管理 PUBLISH 流量的記憶體使用量。
微型
當您記憶體資源有限且用戶端發佈流量不足時,請使用此配置檔。
當您使用此設定檔時:
- 每個前端複本的記憶體使用量上限約為 99 MiB,但實際的記憶體使用量上限可能較高。
- 每個後端複本的記憶體使用量上限約為 102 MiB 乘以後端背景工作角色的數目,但實際的記憶體使用量上限可能較高。
- 訊息大小上限為 4 MB。
- 每個後端工作程序的 PUBLISH 數據傳入緩衝區大小上限約為 16 MiB。 不過,由於反壓機制,有效大小可能會較低,當緩衝區達到 75% 容量時,就會啟動,導致緩衝區大小大約為 12 MiB。 拒絕的封包會收到 PUBACK 回應,並包含 配額超過 的錯誤碼。
使用此設定檔時的建議:
- 應該只使用一個前端。
- 用戶端不應該傳送大型封包。 您應該只傳送小於 4 MiB 的封包。
低
當您有有限的記憶體資源和用戶端發佈小型封包時,請使用此配置檔。
當您使用此設定檔時:
- 每個前端複本的記憶體使用量上限約為 387 MiB,但實際的記憶體使用量上限可能較高。
- 每個後端複本的記憶體使用量上限約為 390 MiB 乘以後端背景工作角色的數目,但實際的記憶體使用量上限可能較高。
- 訊息大小上限為 16 MB。
- PUBLISH 數據的傳入緩衝區大小上限約為每個後端工作者 64 MiB。 不過,由於回壓機制,有效大小可能會較低,當緩衝區達到 75% 容量時,就會啟動,導致緩衝區大小大約為 48 MiB。 拒絕的封包會收到 PUBACK 回應,並包含 配額超過 的錯誤碼。
使用此設定檔時的建議:
- 應該只使用一或兩個前端。
- 用戶端不應該傳送大型封包。 您應該只傳送小於 16 MiB 的封包。
中
當您需要處理中等數量的用戶端訊息時,請使用此配置檔。
中是預設設定檔。
- 每個前端複本的記憶體使用量上限約為 1.9 GiB,但實際的記憶體使用量上限可能較高。
- 每個後端複本的記憶體使用量上限約為 1.5 GiB 乘以後端背景工作角色的數目,但實際的記憶體使用量上限可能較高。
- 訊息大小上限為 64 MB。
- PUBLISH 資料的傳入緩衝區大小上限約為每個後端背景工作角色 576 MiB。 不過,由於反壓機制,有效大小可能會較低,當緩衝區達到 75% 容量時,就會啟動,導致緩衝區大小大約為 432 MiB。 拒絕的封包會收到 PUBACK 回應,並包含 配額超過 的錯誤碼。
高
當您需要處理大量用戶端訊息時,請使用此設定檔。
- 每個前端複本的記憶體使用量上限約為 4.9 GiB,但實際的記憶體使用量上限可能較高。
- 每個後端複本的記憶體使用量上限約為 5.8 GiB 乘以後端背景工作角色的數目,但實際的記憶體使用量上限可能較高。
- 訊息大小上限為 256 MB。
- PUBLISH 資料的傳入緩衝區大小上限約為每個後端背景工作角色 2 GiB。 不過,由於反壓機制,有效大小可能會較低,當緩衝區達到 75% 容量時,就會啟動,導致緩衝區大小大約為 1.5 GiB。 拒絕的封包會收到 PUBACK 回應,並包含 配額超過 的錯誤碼。
計算記憶體使用量總計
記憶體設定檔設定會指定每個前端和後端復本的記憶體使用量,並與基數設定互動。 您可以使用公式來計算記憶體使用量總計:
M_total = R_fe * M_fe + (P_be * RF_be) * M_be * W_be
地點:
| 變數 | 說明 |
|---|---|
| M_total | 記憶體使用量總計 |
| R_fe | 前端復本的數目 |
| M_fe | 每個前端復本的記憶體使用量 |
| P_be | 後端分割區的數目 |
| RF_be | 後端備援因素 |
| M_be | 每個後端復本的記憶體使用量 |
| W_be | 每個後端複本的背景工作角色數目 |
例如,如果您選擇 中型 記憶體配置檔,配置檔的前端記憶體使用量為 1.9 GB,後端記憶體使用量為 1.5 GB。 假設訊息代理程式組態是 2 個前端復本、2 個後端分割區,以及後端備援因數 2。 記憶體使用量總計為:
2 * 1.9 GB + (2 * 2) * 1.5 GB * 2 = 15.8 GB
相比之下, Tiny 記憶體配置檔的前端記憶體使用量為 99 MiB,後端記憶體使用量為 102 MiB。 如果您假設相同的訊息代理程式組態,記憶體使用量總計為:
2 * 99 MB + (2 * 2) * 102 MB * 2 = 198 MB + 816 MB = 1.014 GB。
重要事項
當記憶體已滿 75% 時,MQTT 訊息代理程式就會開始拒絕訊息。
基數和 Kubernetes 資源限制
若要防止叢集中的資源耗盡,代理程式預設會設定為要求 Kubernetes CPU 資源限制。 按比例調整複本或背景工作角色的數目,會增加所需的 CPU 資源。 如果叢集中沒有足夠的 CPU 資源,就會發出部署錯誤。 此通知可協助您避免要求的代理程式基數缺乏足夠的資源而無法以最佳方式執行的情況。 它也有助於避免潛在的 CPU 爭用和 Pod 收回。
MQTT 代理程式目前要求每個前端背景工作角色一個 (1.0) CPU 單位,每個後端背景工作角色兩個 (2.0) CPU 單位。 如需詳細資訊,請參閱 Kubernetes CPU 資源單位。
例如,下列基數會要求下列 CPU 資源:
- 針對前端:每個前端 Pod 2 個 CPU 單位,總計 6 個 CPU 單位。
- 針對後端:每個後端 Pod 4 個 CPU 單位 (適用於兩個後端背景工作角色)、乘以 2 (備援因數)、乘以 3 (分割區數目),總計 24 個 CPU 單位。
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
若要停用此設定,請將代理程式資源中的 generateResourceLimits.cpu 欄位設定為 Disabled。
多節點部署
為了確保具有多節點部署的高可用性和復原能力,IoT 操作 MQTT 代理程式會自動設定後端 Pod 的反親和性規則。
這些規則已預先定義且無法修改。
反親和性規則的目的
反親和性規則可確保來自相同分割區的後端 Pod 不會在相同的節點上執行。 此功能有助於散佈負載,並針對節點失敗提供復原能力。 具體而言,來自相同分割區的後端 Pod 彼此具有反親和性。
確認反親和性設定
若要確認後端 Pod 的反親和性設定,請使用下列命令:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
輸出會顯示反親和性設定,類似於下列範例:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
這些規則是代理程式唯一設定的反親和性規則。