執行 R 指令碼元件
本文說明如何使用「執行 R 指令碼」元件,在 Azure Machine Learning 設計工具管線中執行 R 程式碼。
R 可讓您執行現有元件不支援的工作,例如:
- 建立自訂資料轉換
- 使用您自己的計量來評估預測
- 使用未在設計工具中實作為獨立元件的演算法來建立模型
R 版本支援
Azure Machine Learning 設計工具使用 CRAN (Comprehensive R Archive Network) 的 R 發行版本。目前使用的版本是 CRAN 3.5.1。
受支援的 R 套件
R 環境已預先安裝超過 100 個封裝。 如需完整清單,請參閱預先安裝的 R 封裝一節。
您也可以將下列程式碼新增至任何「執行 R 指令碼」元件,以查看已安裝的封裝。
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
注意
如果管線包含多個「執行 R 指令碼」元件,而這些元件需要的封裝不在預先安裝清單中,請在每個元件中安裝封裝。
安裝 R 套件
若要安裝其他 R 封裝,請使用 install.packages() 方法。 安裝的封裝為每個「執行 R 指令碼」元件專用。 不與其他「執行 R 指令碼」元件共用。
注意
不建議從指令碼套件組合安裝 R 封裝。 建議直接在指令碼編輯器中安裝封裝。
當您安裝封裝時,請指定 CRAN 存放庫,例如 install.packages("zoo",repos = "https://cloud.r-project.org")。
警告
「執行 R 指令碼」元件不支援安裝需要原生編譯的封裝,例如 qdap 封裝需要 JAVA,drc 封裝需要 C++。 這是因為此元件以非管理員權限在預先安裝的環境中執行。
因為設計工具元件是在 Ubuntu 上執行,請勿安裝預先建立在/給 Windows 的封裝。 若要檢查封裝是否在 Windows 上預先建立,您可以移至 CRAN 來搜尋封裝,根據您的作業系統下載一個二進位檔案,然後檢查 DESCRIPTION 檔案中的 Built: 部分。 以下是範例: 
此範例說明如何安裝 Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
注意
安裝封裝之前,請檢查封裝是否已存在,以免重複安裝。 重複安裝可能導致 Web 服務要求逾時。
存取已註冊的資料集
您可以參考下列範例程式碼,以存取工作區中已註冊的資料集:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
如何設定執行 R 指令碼
「執行 R 指令碼」元件包含範例程式碼作為起點。
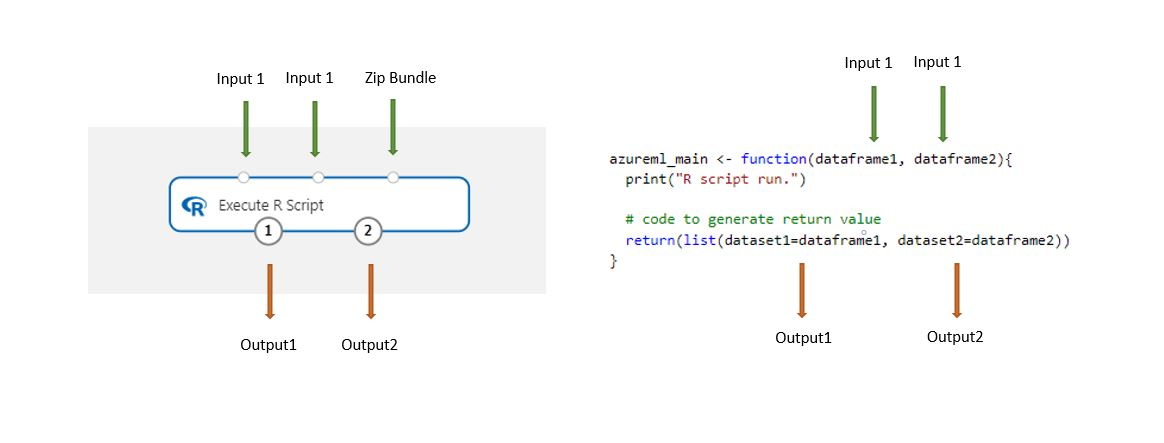
使用此元件載入儲存在設計工具中的資料集時,資料集會自動轉換成 R 資料框架。
將執行 R 指令碼元件新增至管線。
連線指令碼所需的任何輸入。 輸入為選用,可以包含資料和其他 R 程式碼。
Dataset1:以
dataframe1參考第一個輸入。 輸入資料集的格式必須為 CSV、TSV 或 ARFF 檔案。 或者,您也可以連線 Azure Machine Learning 資料集。Dataset2:以
dataframe2參考第二個輸入。 此資料集的格式也必須為 CSV、TSV 或 ARFF 檔案,或是 Azure Machine Learning 資料集。指令碼套件組合:第三個輸入接受 .zip 檔案。 一個 ZIP 壓縮檔案可以包含多個檔案和多個檔案類型。
在 [R 指令碼] 文字輸入框中,輸入或貼上有效的 R 指令碼。
注意
請小心撰寫指令碼。 請確定沒有語法錯誤,例如使用未宣告的變數或未匯入的元件或函式。 請特別注意本文結尾預先安裝的封裝清單。 若要使用未列出的封裝,請在指令碼中安裝。 例如
install.packages("zoo",repos = "https://cloud.r-project.org")。為了協助您開始使用,[R 指令碼] 文字輸入框已預先填入範例程式碼,供您編輯或取代。
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }即使進入點函式中不使用輸入引數
Param<dataframe1>和Param<dataframe2>,函式也必須有這些引數。注意
傳遞至「執行 R 指令碼」元件的資料是以
dataframe1和dataframe2來參考,這不同於 Azure Machine Learning 設計工具 (設計工具參考為dataset1、dataset2)。 請確定指令碼中正確參考輸入資料。注意
現有的 R 程式碼可能需要稍微變更,才能在設計工具管線中執行。 例如,您以 CSV 格式提供的輸入資料應該明確轉換成資料集,才能在程式碼中使用。 在 R 語言中使用的資料和資料行類型,在某些方面也不同於設計工具中使用的資料和資料行類型。
如果指令碼大於 16 KB,請使用指令碼套件組合連接埠,以避免像是「CommandLine 超過 16597 個字元的限制」的錯誤。
- 將指令碼和其他自訂資源組合成 ZIP 檔案。
- 將 ZIP 檔案當作檔案資料集上傳到工作室。
- 在設計工具撰寫頁面的左側元件窗格中,從 [資料集] 清單拖曳資料集元件。
- 將資料集元件連線至執行 R 指令碼元件的指令碼套件組合連接埠。
以下範例程式碼取用指令碼套件組合中的指令碼:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }在 [隨機種子] 中,輸入一個值作為 R 環境內的隨機種子值。 此參數等同於呼叫 R 程式碼中的
set.seed(value)。提交管線。
結果
「執行 R 指令碼」元件可以傳回多個輸出,但必須以 R 資料框架提供這些輸出。 設計工具會自動將資料框架轉換成資料集,以相容於其他元件。
R 的標準訊息和錯誤會傳回至元件的記錄。
如果您需要在 R 指令碼中列印結果,您可以在元件右面板的 [輸出+記錄] 索引標籤下,從 70_driver_log 中找到列印結果。
範例指令碼
使用自訂 R 指令碼來延伸管線有許多種方式。 本節提供一般工作的範例程式碼。
新增 R 指令碼做為輸入
「執行 R 指令碼」元件支援任意 R 指令碼檔案做為輸入。 若要使用這些檔案,則必須放入 .zip 檔案中上傳至工作區。
若要將包含 R 程式碼的 .zip 檔案上傳至工作區,請移至 [資料集] 資產頁面。 選取 [建立資料集],然後選取 [從本機檔案] 和 [檔案] 資料集類型選項。
確認 ZIP 壓縮檔案出現在左側元件樹狀的 [資料集] 類別下的 [我的資料集] 中。
將資料集連線至指令碼套件組合輸入連接埠。
.zip 檔案中的所有檔案可供管線執行階段使用。
如果指令碼套件組合檔案包含目錄結構,則會保留結構。 但您必須變更程式碼,在路徑前面加上 ./Script Bundle 目錄。
處理資料
下列範例示範如何調整和標準化輸入資料:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
讀取 .zip 檔案作為輸入
此範例示範如何使用 .zip 檔案中的資料集,作為「執行 R 指令碼」元件的輸入。
- 建立 CSV 格式的資料檔案,並命名為 mydatafile.csv。
- 建立 .zip 檔案,並將 CSV 檔案新增至封存層。
- 將 ZIP 壓縮檔案上傳至 Azure Machine Learning 工作區。
- 將產生的資料集連線至執行 R 指令碼元件的 ScriptBundle 輸入。
- 使用下列程式碼讀取 ZIP 壓縮檔案中的 CSV 資料。
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
複寫資料列
此範例示範如何複寫資料集中的陽性記錄以平衡樣本:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
在執行 R 指令碼元件之間傳遞 R 物件
您可以使用內部序列化機制,在「執行 R 指令碼」元件的執行個體之間傳遞 R 物件。 此範例假設您想要在兩個「執行 R 指令碼」元件之間移動名為 A 的 R 物件。
將第一個執行 R 指令碼元件新增至管線。 然後,在 [R 指令碼] 文字輸入框中輸入下列程式碼,以建立序列化物件
A,做為元件輸出資料表中的資料行:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }明確轉換成整數類型是因為序列化函式以 R
Raw格式輸出資料,但設計工具不支援此格式。新增執行 R 指令碼元件的第二個執行個體,並連線至前一個元件的輸出連接埠。
在 [R 指令碼] 文字輸入框中輸入下列程式碼,以從輸入資料表擷取物件
A。azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
預先安裝的 R 封裝
目前提供下列預先安裝的 R 封裝:
| 套件 | 版本 |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| caret | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| Class - 類別 | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| 叢集 | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| datasets | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| 泛型 | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| 方格 | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0.8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| 矩陣 | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0.8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
後續步驟
請參閱 Azure Machine Learning 可用的元件集。