從文字中擷取 N 元語法特徵元件參考
本文描述 Azure Machine Learning 設計工具中的一個元件。 使用「從文字擷取 N 元語法特徵」元件,將非結構化文字資料「特徵化」。
從文字擷取 N 元語法特徵元件的組態
此元件支援下列使用 n 元語法字典的案例:
從任意文字的資料行中建立新的 n 元語法字典。
使用一組現有的文字特徵,將任意文字資料行特徵化。
評分或部署一個使用 n 元語法的模型。
建立新的 n 元語法字典
將「從文字擷取 N 元語法特徵」元件新增至您的管線,並連接資料集,其中具有您想要處理的文字。
使用 [文字資料行],來選擇字串類型的資料行,其中包含您想要擷取的文字。 因為結果冗長,所以您一次只能處理一個資料行。
將 [詞彙模式] 設定為 [建立],表示您要建立新的 n 元語法特徵清單。
設定 [N 元語法大小],以指出要擷取和儲存的 n 元語法大小「上限」。
例如,如果您輸入 3,則會建立單字母組、雙字母組和三字母組。
加權函數會指定如何建置文件特徵向量,以及如何從文件中擷取詞彙。
二進位權重:將二進位保留值指派給擷取的 n 元語法。 當每個 n 元語法存在於文件中時,其值為 1,否則為 0。
TF 權重:將字彙頻率 (TF) 分數指派給擷取的 n 元語法。 每個 n 元語法的值是其在文件中出現的頻率。
IDF 權重:將反向文件頻率 (IDF) 分數指派給擷取的 n 元語法。 每個 n 語法的值是語料庫大小除以其在整個語料庫中出現頻率的記錄。
IDF = log of corpus_size / document_frequency權重:將字詞頻率/反向文件頻率 (TF/IDF) 分數指派給擷取的 n 元語法。 每個 n 元語法的值是其 TF 分數乘以其 IDF 分數。
將 [字組長度下限] 設定為可在 n 元語法中任何「單一字組」中使用的字母數目下限。
使用 [字組長度上限],設定可在 n 元語法中任何「單一字組」中使用的字母數目上限。
根據預設,每個字組或語彙基元最多可有 25 個字元。
使用 [最低 n 元語法文件絕對頻率],針對要併入 n 元語法字典中的任何 n 元語法設定所需的最低出現次數。
例如,如果您使用預設值 5,則任何 n 元語法必須在語料庫至少出現五次,才能併入 n 元語法字典中。
將 [最大的 n 元語法文件比例] 設定為包含特定 n 元語法的資料列數目與整體語料庫資料列數目的最大比例。
例如,比例 1 將指出,即使每個資料列中都有特定的 n 元語法,也可以將 n 元語法新增至 n 元語法字典。 一般來說,每個資料列中出現的字組都會被視為非搜尋字,而且會將其移除。 若要篩選出網域相依的非搜尋字,請嘗試減少這個比例。
重要事項
特定字組的出現率不一致。 其會隨著文件而異。 例如,如果您要分析有關特定產品的客戶評論,則產品名稱可能出現頻率非常高,且接近非搜尋字,但在其他內容中卻是很重要的字詞。
選取 [正規化 n 元語法特徵向量] 選項來正規化特徵向量。 如果已啟用此選項,則每個 n 元語法特徵向量會除以其 L2 標準。
提交管線。
使用現有的 n 元語法字典
將「從文字擷取 N 元語法特徵」元件新增至您的管線,並將資料集連線至資料集連接埠,而此資料集具有您想要處理的文字。
使用 [文字資料行],來選取文字資料行,其中包含您要特徵化的文字。 根據預設,元件會選取類型為 [字串] 的所有資料行。 如需最佳結果,請一次處理一個資料行。
新增儲存的資料集,其中包含先前產生的 n 元語法字典,並將該資料集連線至輸入詞彙連接埠。 您也可以連接「從文字擷取 N 元語法特徵」元件的上游執行個體的結果詞彙輸出。
針對 [詞彙模式],請從下拉式清單中選取 [唯讀] 更新選項。
[唯讀] 選項代表輸入詞彙的輸入語料庫。 來自輸入詞彙的 n 元語法權重會依原狀套用,而不會計算字詞來自新資料集 (在左側輸入上) 的頻率。
秘訣
當您要評分文字分類器時,請使用此選項。
如需所有其他選項,請參閱上一節中的屬性描述。
提交管線。
建置使用 n 元語法的推斷管線來部署即時端點
定型管線是以下列結構建置的,此管線包含 [從文字擷取 N 元語法特徵] 和 [分數模型],以對測試資料集進行預測:
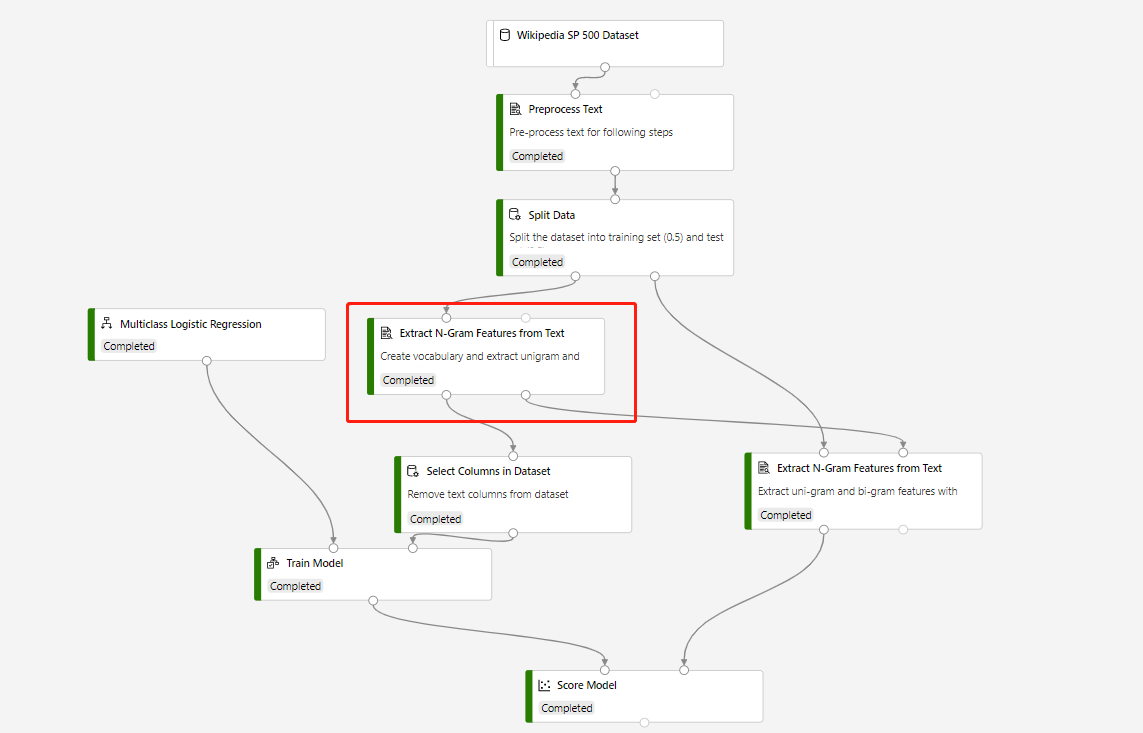
圓形 [從文件擷取 N 元語法特徵] 元件的 [詞彙模式] 為 [建立],而元件若件連線到 [評分模型] 元件,其 [詞彙模式] 為 [唯讀]。
在成功提交上述定型管線之後,您可以將圓形元件的輸出註冊為資料集。
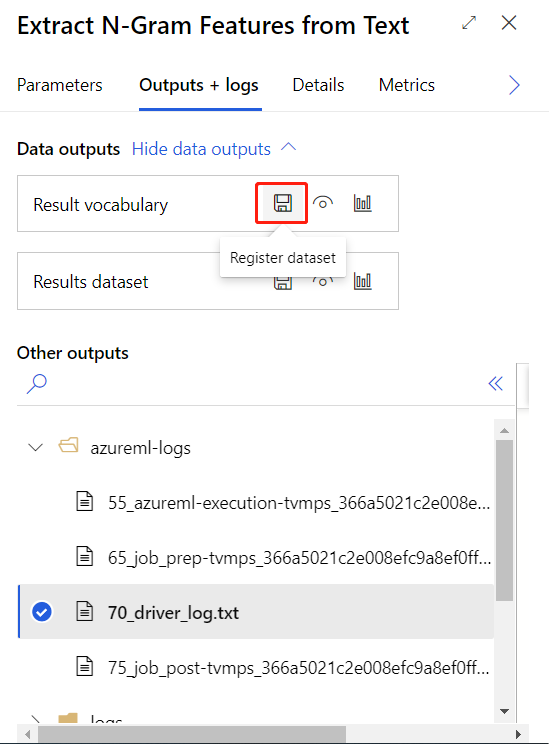
然後,您可以建立即時推斷管線。 在建立推斷管線之後,您需要手動調整您的推斷管線,如下所示:
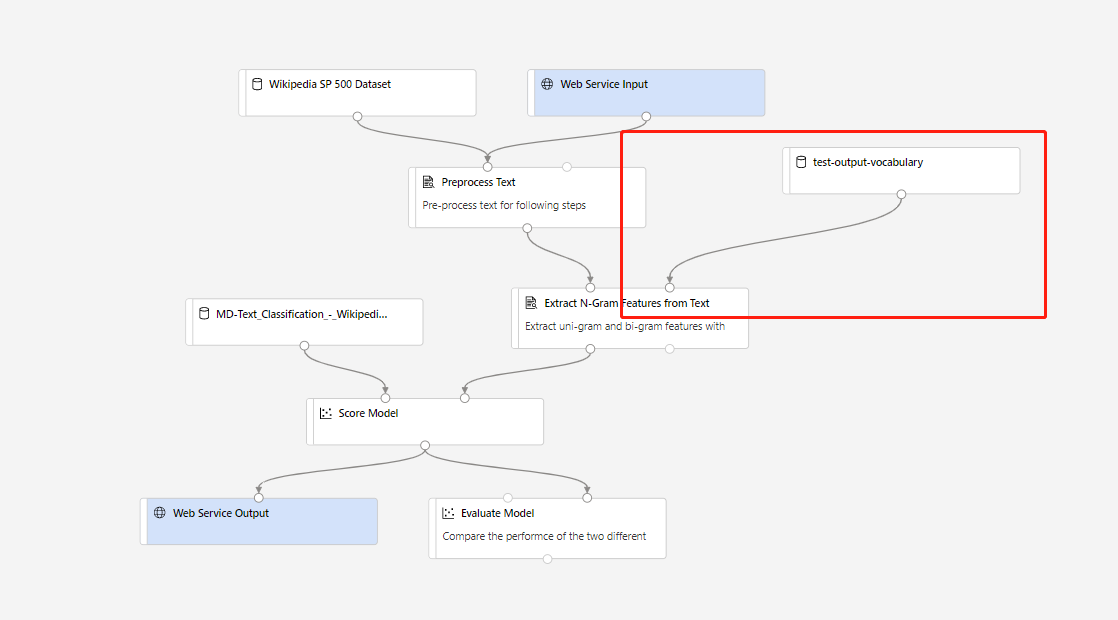
然後,提交推斷管線,並部署即時端點。
結果
「從文件擷取 N 語法特徵」文件會建立兩種類型的輸出:
結果資料集:此輸出是已分析文字的摘要,並結合了已擷取的 n 元語法。 您未在 [文字資料行] 選項中選取的資料行會傳遞至輸出。 針對每個您分析的文字資料行,元件都會產生下列資料行:
- n 元語法出現次數的矩陣:此元件會針對在整個語料庫中找到的每個 n 元語法產生一個資料行,並在每個資料行中新增分數,以指出該資料列的 n 元語法權重。
結果詞彙:詞彙包含實際的 n 元語法字典,以及在分析過程中產生的字詞頻率分數。 您可以儲存資料集,以重複使用一組不同的輸入或在稍後進行更新。 您也可以重複使用詞彙來進行模型化和評分。
結果詞彙
詞彙包含 n 元語法字典,其中包含在分析過程中產生的字詞頻率分數。 無論其他選項為何,都會產生 DF 和 IDF 分數。
- ID:針對每個唯一 n 元語法所產生的識別碼。
- NGram:n 元語法。 空格或其他字組分隔符號會被底線字元所取代。
- DF:原始語料庫中 n 元語法的字詞頻率分數。
- IDF:原始語料庫中 n 元語法的反向文件頻率分數。
您可以手動更新此資料集,但可能會引進錯誤。 例如:
- 如果元件在輸入詞彙中找到索引鍵相同的重複資料列,則會引發錯誤。 確定詞彙中沒有兩個資料列具有相同的字組。
- 詞彙資料集的輸入結構描述必須完全相符,包括資料行名稱和資料行類型。
- ID 資料行和 DF 資料行必須屬於整數類型。
- IDF 資料行必須屬於浮點數類型。
注意
請不要直接將資料輸出連線到定型模型元件。 您應該先移除任意文字資料行,然後再將它們饋送至定型模型。 否則,任意文字資料行將被視為類別特徵。
後續步驟
請參閱 Azure Machine Learning 可用的元件集。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應