分割和取樣元件
本文描述 Azure Machine Learning 設計工具中的一個元件。
使用「分割和取樣」元件在資料集上執行取樣,或從資料集建立分割區。
取樣是重要的工具,在機器學習,因為它可讓您同時維持相同值的比例減少資料集的大小。 此元件支援機器學習中幾個重要的相關工作:
將資料分割成多個相同大小的子區段。
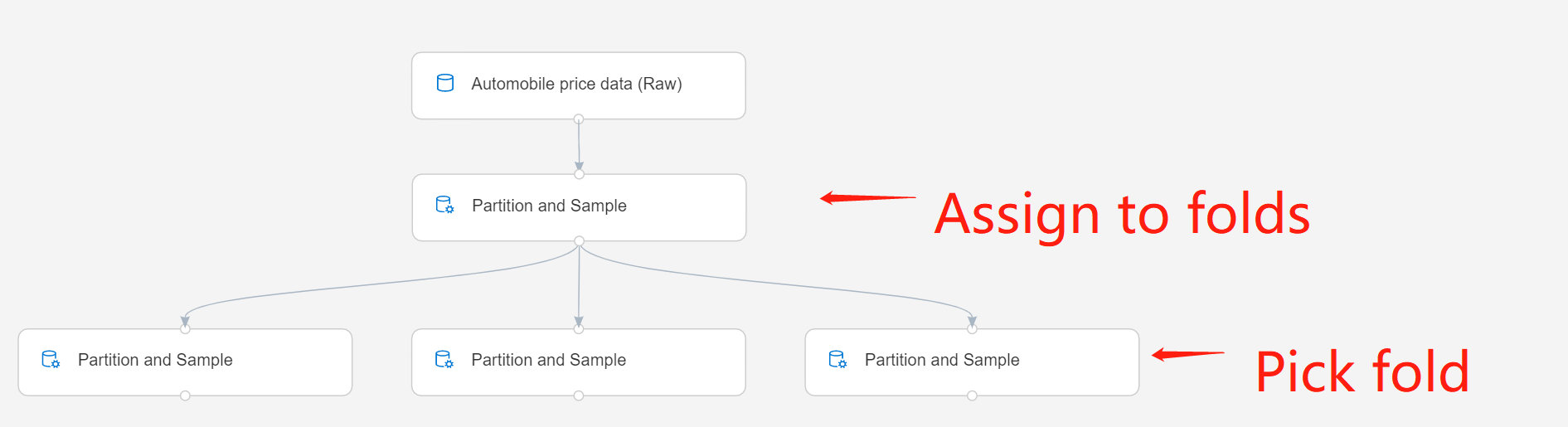
您可以使用分割區進行交叉驗證,或將案例指派給隨機群組。
將資料分隔成群組,然後使用特定群組中的資料。
將案例隨機指派給不同的群組之後,您可能需要修改只與一個群組相關聯的功能。
取樣。
您可以擷取一定百分比的資料、套用隨機取樣,或選擇資料行來用於平衡資料集並分層取樣其中的值。
建立較小的資料集來用於測試。
如果您有大量資料,則可以在設定管線時只使用前 n 個資料列,然後在建立模型時改用完整資料集。 您也可以使用取樣來建立較小的資料集,供開發中使用。
設定元件
此元件支援下列方法將資料分割成分割區或取樣。 請先選擇方法,然後設定方法所需的其他選項。
- Head
- 取樣
- 指派給摺疊
- 挑選摺疊
從資料集取得 TOP N 個資料列
使用此模式可取得的第一個n資料列。 如果要在少量資料列上測試管線,而完全不需要平衡或取樣資料,此選項很有用。
在介面中將分割和取樣元件新增至管線,然後連線資料集。
分割或取樣模式:將此選項設定為 [頭]。
要選取的資料列數目:輸入要傳回的資料列數目。
資料列數目必須為非負整數。 如果選取的資料列數目大於資料集的資料列數目,則會傳回整個資料集。
提交管線。
元件會輸出單一資料集,其中只包含指定的資料列數目。 永遠會從資料集的頂端讀取資料列。
建立資料樣本
此選項支援簡單隨機取樣或分層隨機取樣。 這有助於建立較小的代表性樣本資料集來測試。
將分割和取樣元件新增至管線,然後連線資料集。
分割或取樣模式:將此選項設定為 [取樣]。
取樣率:輸入介於 0 和 1 之間的值。 此值指定應該將來源資料集的多少百分比資料列納入輸出資料集。
例如,如果只想要原始資料集的一半,請輸入
0.5表示取樣率應該為 50%。輸入資料集的資料列經過洗牌,再根據指定的比例挑選放入輸出資料集。
取樣的隨機種子:選擇性輸入整數作為種子值。
如果每次都要以相同的方式分割資料列,此選項很重要。 預設值為 0,表示根據系統時鐘產生起始種子。 此值可能導致每次執行管線時的結果稍微不同。
取樣的分層分割:如果取樣之前必須以某個索引鍵資料行平均分割資料集的資料列,請選取此選項。
針對 [取樣的分層索引鍵資料行],選取要在分割資料集時使用的單一「分層資料行」。 然後,資料集的資料列會分割如下:
所有輸入資料列依指定分層資料行中的值分組 (分層)。
將每個群組內的資料列打散
選擇性地將每個群組加入至輸出資料集,以符合指定的比率。
提交管線。
使用此選項時,元件會輸出單一資料集,其中包含資料的代表性取樣。 資料集的其餘、未取樣的部分不會輸出。
將資料分割成分割區
想要將資料集分割成資料的子集時,請使用此選項。 想要建立自訂數目的摺疊來進行交叉驗證,或將資料列分割成多個群組時,此選項也很有用。
將分割和取樣元件新增至管線,然後連線資料集。
針對 [分割或取樣模式],請選取 [指派給摺疊]。
在資料分割中使用放回:如果想要將取樣的資料列放回資料列集區,以保留機會重複使用,請選取此選項。 因此,相同的資料列可能指派給數個摺疊。
如果您不使用放回 (預設選項),則取樣的資料列不會放回資料列集區,也就沒有機會重複使用。 因此,每個資料列只能指派給一個摺疊。
隨機化分割:如果想要將資料列隨機指派給摺疊,請選取此選項。
如果您未選取此選項,則會透過循環方法將資料列指派給摺疊。
隨機種子:選擇性輸入整數作為種子值。 如果每次都要以相同的方式分割資料列,此選項很重要。 否則,預設值 0 表示會使用隨機起始種子。
指定分割區方法:使用下列選項指出如何將資料分配至每個分割區:
平均分割:使用此選項將相等數目的資料列放入每個分割區。 若要指定輸出分割區數目,請在 [指定要平均分割的摺疊數目] 方塊中輸入。
以自訂比例分割:使用此選項以逗點分隔清單指定每個分割區的大小。
例如,假設您想要建立三個分割區。 第一個分割區包含 50% 的資料。 其餘兩個分割區各包含 25% 的資料。 在 [以逗號分隔的比例清單] 方塊中,輸入這些數字:.5, .25, .25。
所有分割區大小的總和必須剛好為 1。
如果您輸入的數字合計「小於 1」,則會建立額外分割區來保存剩餘資料列。 例如,如果您輸入值 .2 和 .3,則會建立第三個分割區來保存所有資料列的剩餘 50%。
如果您輸入的數字合計「大於 1」,則執行管線時會引發錯誤。
分層分割:如果想要在分割時將資料列分層,請選取此選項,然後選擇「分層資料行」。
提交管線。
使用此選項時,元件會輸出多個資料集。 資料集會根據您指定的規則來分割。
使用預先定義分割區中的資料
如果您已將資料集分割成多個分割區,而現在想要逐一載入每個分割區來進一步分析或處理,請使用此選項。
將分割和取樣元件新增至管線。
將元件連線至先前的分割和取樣執行個體的輸出。 該執行個體必須已使用 [指派給摺疊] 選項來產生一些分割區。
分割或取樣模式:選取 [挑選摺疊]。
指定要取樣的摺疊:輸入索引來選取要使用的分割區。 分割區索引是以 1 為基底。 例如,如果您將資料集分成三個部分,則分割區的索引為 1、2 和 3。
如果您輸入無效的索引值,則會引發設計階段錯誤:「錯誤0018:資料集包含無效資料」。
除了依摺疊來分組資料集,您還可以將資料集分成兩個群組:目標摺疊及其他一切。 作法是輸入單一摺疊的索引,然後選取 [挑選所選摺疊的補充] 選項,以取得指定摺疊中資料除外的一切。
如果您使用多個分割區,則必須新增更多分割和取樣元件的執行個體,以處理每個分割區。
例如,第二個資料列中的分割和取樣元件設定為 [指派給摺疊],而第三個資料列中的元件設定為 [挑選摺疊]。
提交管線。
使用此選項時,元件會輸出單一資料集,其中只包含指派給該摺疊的資料列。
注意
您無法直接檢視摺疊編號。 這只存在於中繼資料中。
後續步驟
請參閱 Azure Machine Learning 可用的元件集。