快速入門:在 Azure Machine Learning 中使用 Apache Spark 進行互動式資料整頓
為了處理互動式 Azure Machine Learning Notebook 資料整頓,Azure Machine Learning 與 Azure Synapse Analytics 整合可讓您輕鬆存取 Apache Spark 架構。 此存取可讓您進行 Azure Machine Learning Notebook 互動式資料整頓。
在本快速入門指南中,您將瞭解如何執行與 Azure 機器學習 無伺服器 Spark 計算、Azure Data Lake 儲存體 (ADLS) Gen 2 儲存器帳戶和使用者身分識別傳遞的互動式數據整頓。
必要條件
- Azure 訂用帳戶;如果您沒有 Azure 訂用帳戶,請在 開始之前建立免費帳戶 。
- Azure Machine Learning 工作區。 請流覽 建立工作區資源。
- Azure Data Lake Storage (ADLS) Gen 2 儲存體帳戶。 請流覽建立 Azure Data Lake 儲存體 (ADLS) Gen 2 儲存器帳戶。
將 Azure 儲存體帳戶認證儲存為 Azure Key Vault 中的秘密
若要使用 Azure 入口網站 使用者介面,將 Azure 記憶體帳戶認證儲存為 Azure 金鑰保存庫 中的秘密:
在 Azure 入口網站 中流覽至您的 Azure 金鑰保存庫
從左面板中選取 [秘密 ]
選取 [+ 產生/匯入]
![顯示 [Azure 金鑰保存庫 秘密產生或匯入] 索引卷標的螢幕快照。](media/apache-spark-environment-configuration/azure-key-vault-secrets-generate-import.png?view=azureml-api-2)
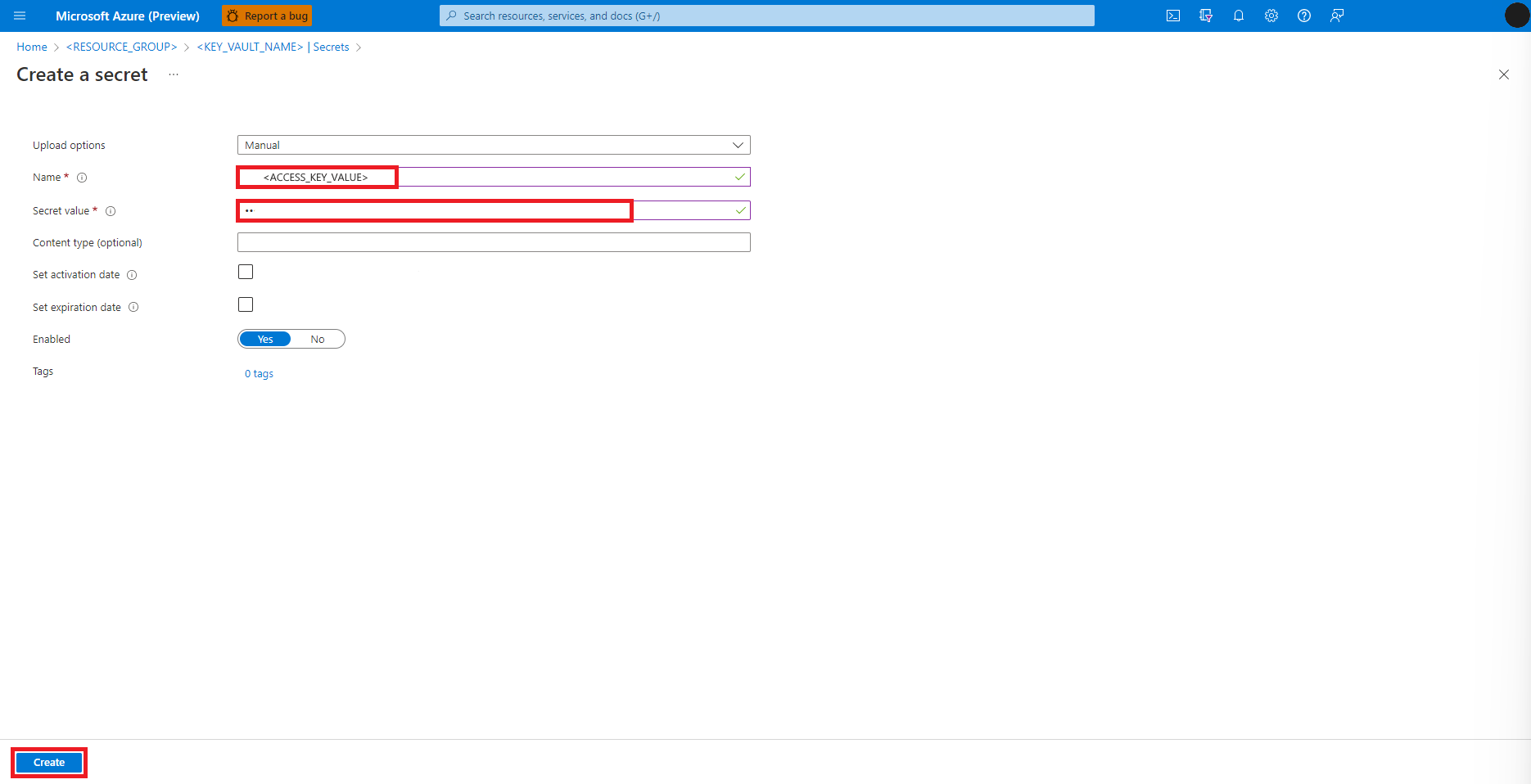
在 [建立秘密] 畫面上,輸入您要建立之秘密的名稱
流覽至 Azure Blob 儲存體 帳戶,在 Azure 入口網站 中,如下圖所示:
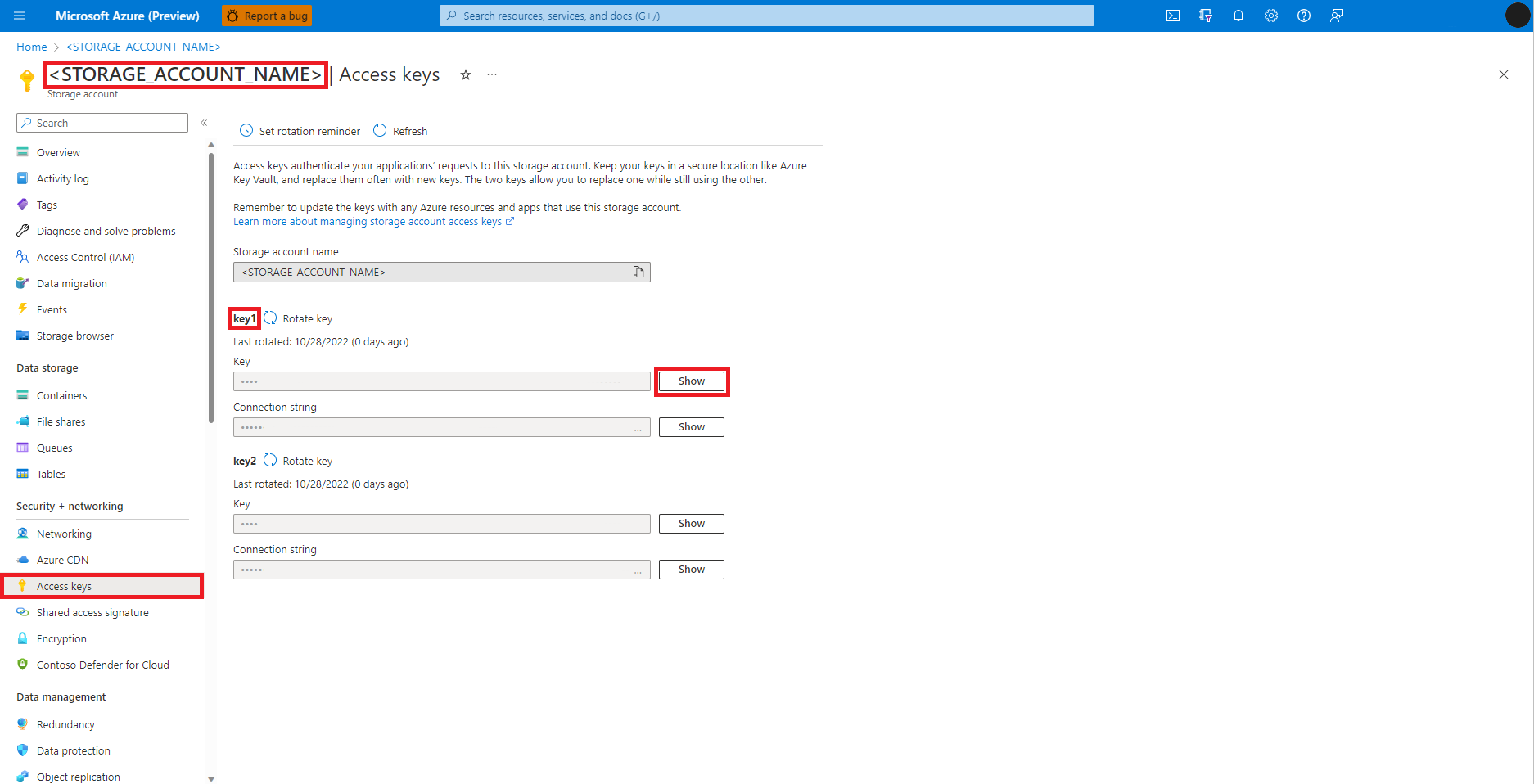
從 [Azure Blob 儲存體 帳戶] 頁面左側面板中選取 [存取密鑰]
選取 [金鑰 1] 旁的 [顯示],然後選取 [複製到剪貼簿] 以取得記憶體帳戶存取密鑰
注意
選取要複製的適當選項
- Azure Blob 儲存體容器共用存取簽章 (SAS) 權杖
- Azure Data Lake Storage (ADLS) Gen 2 儲存體帳戶服務主體認證
- 租用戶識別碼
- 用戶端識別碼和
- secret
在您為其建立 Azure 金鑰保存庫 秘密時,位於個別的使用者介面上
流覽回 [ 建立秘密 ] 畫面
在 [ 秘密值] 文本框中,輸入 Azure 記憶體帳戶的存取密鑰認證,該認證已複製到先前步驟中的剪貼簿
選取 [建立]
提示
Azure CLI 和適用於 Python 的 Azure Key Vault 祕密用戶端程式庫也可以建立 Azure Key Vault 秘密。
在 Azure 儲存體帳戶中新增角色指派
在開始進行互動式資料整頓之前,我們必須確保輸入和輸出資料路徑是可存取的。 首先,針對
已登入使用者的 Notebooks 會話使用者身分識別
或
服務主體
將讀者和儲存體 Blob 資料讀者角色指派給登入使用者的使用者身分識別。 不過,在某些情況下,我們可能會想要將整頓的資料寫入回 Azure 儲存體帳戶。 讀者和儲存體 Blob 資料讀者角色提供使用者身分識別或服務主體的唯讀存取權。 若要啟用讀取和寫入存取權,請將參與者和儲存體 Blob 資料參與者角色指派給使用者身分識別或服務主體。 若要將適當的角色指派給使用者身分識別:
搜尋並選取 儲存體 帳戶服務

在 [儲存體帳戶] 頁面上,從清單中選取 Azure Data Lake Storage (ADLS) Gen 2 儲存體帳戶。 顯示記憶體帳戶 概觀 的頁面隨即開啟

從左面板中選取 [存取控制 (IAM)]
選取 [新增角色指派]

尋找並選取 [儲存體 Blob 資料參與者] 角色
選取下一個

選取 [使用者、群組或服務主體]
選取 [+ 選取成員]
在 [選取] 的下方搜尋使用者身分識別
從清單中選取使用者身分識別,使其顯示在 [選取的成員] 底下
選取適當的使用者身分識別
選取下一個
![顯示 [Azure 新增角色指派] 畫面 [成員] 索引卷標的螢幕快照。](media/apache-spark-environment-configuration/add-role-assignment-choose-members.png?view=azureml-api-2)
選取 [檢閱 + 指派]
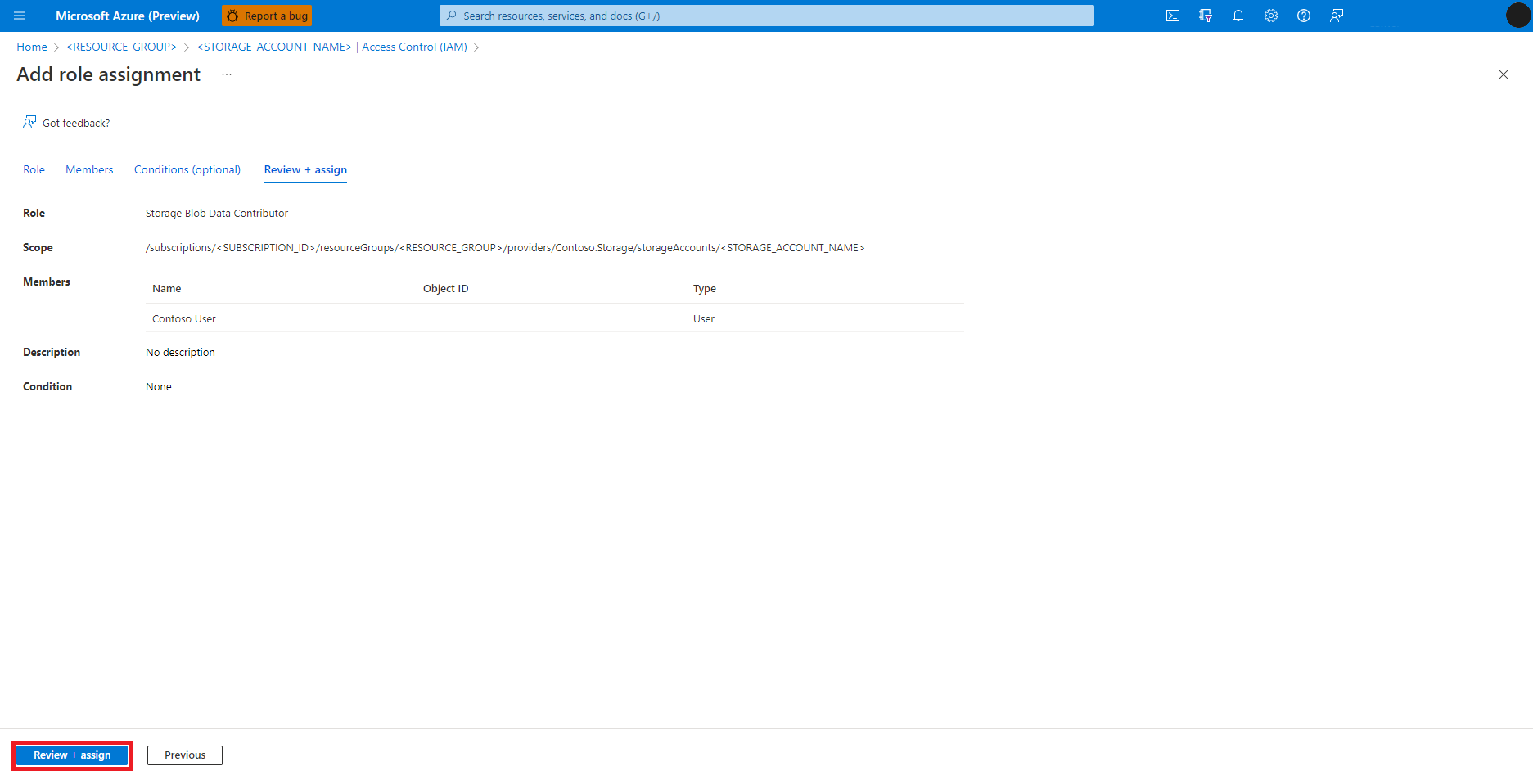
針對 參與者 角色指派重複步驟 2-13




![顯示 [Azure 新增角色指派] 畫面 [成員] 索引卷標的螢幕快照。](media/apache-spark-environment-configuration/add-role-assignment-choose-members.png?view=azureml-api-2#lightbox)

一旦為使用者身分識別已指派了適當的角色後,Azure 儲存體帳戶中的資料就應該可以存取。
注意
如果連結的 Synapse Spark 集區指向 Synapse Spark 集區,在 Azure Synapse 工作區中,具有與其相關聯的受控虛擬網路,您應該設定記憶體帳戶的受控私人端點以確保數據存取。
確保 Spark 作業的資源存取
若要存取資料和其他資源,Spark 作業可以使用受控識別或使用者身分識別傳遞。 下表摘要說明當您使用 Azure 機器學習 無伺服器 Spark 計算和連結的 Synapse Spark 集區時,資源存取的不同機制。
| Spark 集區 | 支援的身分識別 | 預設身分識別 |
|---|---|---|
| 無伺服器 Spark 計算 | 使用者身分識別、附加至工作區的使用者指派受控識別 | 使用者身分識別 |
| 連結的 Synapse Spark 集區 | 使用者身分識別、附加至附加 Synapse Spark 集區的使用者指派受控識別、附加 Synapse Spark 集區的系統指派受控識別 | 附加 Synapse Spark 集區的系統指派受控識別 |
如果 CLI 或 SDK 程式碼定義一個使用受控識別的選項,則 Azure Machine Learning 無伺服器 Spark 計算會依賴連結至工作區的使用者指派受控識別。 您可以使用 Azure 機器學習 CLI v2 或搭配 ARMClient,將使用者指派的受控識別附加至現有的 Azure 機器學習 工作區。
下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應