使用 Azure Data Factory 進行資料擷取
在本文中,您將了解可使用 Azure Data Factory 來建置資料擷取管線的可用選項。 這個 Azure Data Factory 管線可用來擷取資料以便與 Azure Machine Learning 搭配使用。 Data Factory 可讓您輕鬆地擷取、轉換和載入 (ETL) 資料。 資料經過轉換並載入到儲存體後,就可以在 Azure Machine Learning 中用來為機器學習模型定型。
您可以使用原生的 Data Factory 活動和檢測 (例如資料流程) 來處理簡單的資料轉換。 至於更複雜的案例,則可以使用一些自訂程式碼來處理資料。 例如,Python 或 R 程式碼。
比較 Azure Data Factory 資料擷取管線
在擷取期間使用 Data Factory 來轉換資料時,有幾個常見的技術。 每個技術各有優缺點,可助您判斷其是否適用於特定使用案例:
| 技術 | 優點 | 缺點 |
|---|---|---|
| Data Factory + Azure Functions | 僅適用於短時間執行的處理 | |
| Data Factory + 自訂元件 | ||
| Data Factory + Azure Databricks 筆記本 |
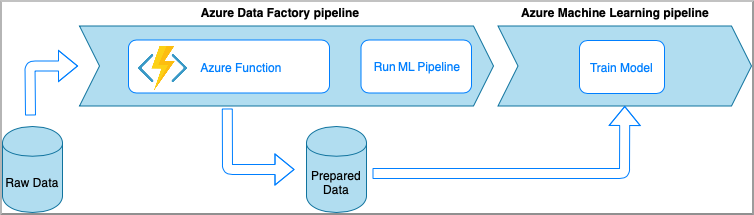
Azure Data Factory 搭配 Azure functions
Azure Functions 可讓您執行一小段程式碼 (函式),而無須顧慮應用程式基礎結構。 此選項會使用包裝到 Azure 函式內的自訂 Python 程式碼來處理資料。
會使用 Azure Data Factory Azure 函式活動來叫用函式。 這個方法適合用來轉換輕量資料。
- 優點:
- 資料會在無伺服器計算上進行處理,因此延遲相對較低
- Data Factory 管線可以叫用耐久性 Azure 函數而能夠實作複雜的資料轉換流程
- Azure 函式會抽取資料轉換詳細資料,以便能從其他位置重複使用和叫用
- 缺點:
- 必須先建立 Azure Functions,才能搭配 ADF 使用
- Azure Functions 只適用於短時間執行的資料處理
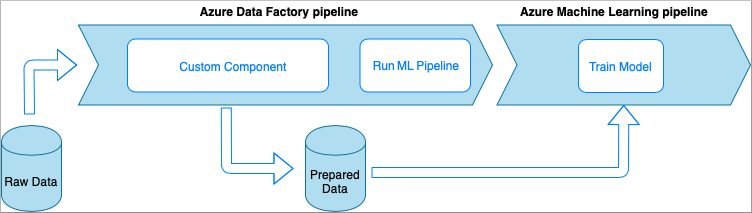
Azure Data Factory 搭配自訂元件活動
此選項會使用包裝到可執行檔內的自訂 Python 程式碼來處理資料。 會使用 Azure Data Factory 自訂元件活動來叫用。 這個方法比上一項技術更適合大型資料。
- 優點:
- 資料會在 Azure Batch 集區上進行處理,可提供大規模的平行和高效能計算
- 可用來執行大型演算法和處理大量資料
- 缺點:
- 必須先建立 Azure Batch 集區,才能搭配 Data Factory 使用
- 相較於將 Python 程式碼包裝到可執行檔內,這個方法的工程難度過大。 相依性和輸入/輸出參數的處理很複雜
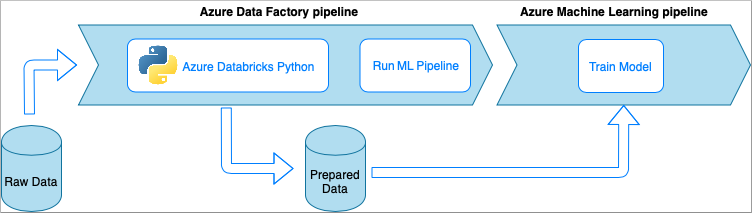
Azure Data Factory 搭配 Azure Databricks Python 筆記本
Azure Databricks 是 Microsoft Cloud 中的 Apache Spark 型分析平台。
在這項技術中,會由在 Azure Databricks 叢集上執行的 Python 筆記本執行資料轉換。 這可能是最常見的方法,可充分使用 Azure Databricks 服務的完整功能。 其專為大規模的分散式資料處理而設計。
- 優點:
- 資料會在功能最為強大的資料處理 Azure 服務 (由 Apache Spark 環境提供支援) 上進行轉換
- 原生支援 Python 以及資料科學架構和程式庫,包括 TensorFlow、PyTorch 和 scikit-learn
- 不需要將 Python 程式碼包裝到函式或可執行檔模組內。 程式碼會以原狀運作。
- 缺點:
- 必須先建立 Azure Databricks 基礎結構,才能搭配 Data Factory 使用
- 視 Azure Databricks 設定而定,成本可能會很高
- 從「冷」模式啟動計算叢集會花一些時間,因此解決方案的延遲很高
取用 Azure Machine Learning 中的資料
Data Factory 管線會將準備好的資料儲存到雲端儲存空間 (例如 Azure Blob 或 Azure Data Lake)。
透過以下方式即可取用 Azure Machine Learning 中已準備好的資料:
- 從 Data Factory 管線叫用 Azure Machine Learning 管線。
OR - 建立 Azure Machine Learning 資料存放區。
從 Data Factory 叫用 Azure Machine Learning 管線
機器學習作業 (MLOps) 工作流程建議使用這個方法。 如果您不想要設定 Azure Machine Learning 管線,請參閱直接從儲存體讀取資料。
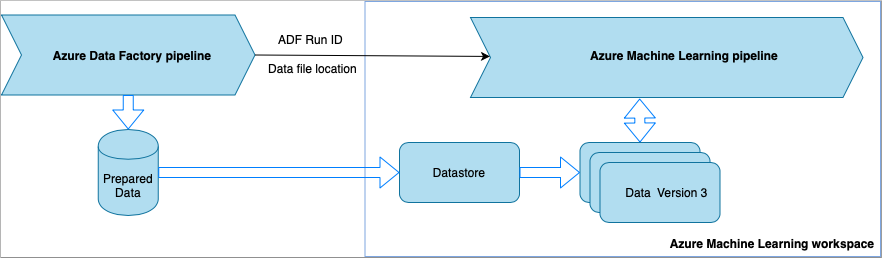
Data Factory 管線每次執行時,
- 資料會儲存到儲存體中的不同位置。
- 為了將位置傳遞給 Azure Machine Learning,Data Factory 管線會呼叫 Azure Machine Learning 管線。 在呼叫 ML 管線時,會以參數形式傳送資料位置和作業識別碼。
- 接著,ML 管線便可使用該資料位置建立 Azure Machine Learning 資料存放區和資料集。 若要深入了解,請參閱在 Data Factory 中執行 Azure Machine Learning 管線。
提示
資料集支援版本設定,因此 ML 管線可以註冊新版本的資料集,以指向 ADF 管線中的最新資料。
在能透過資料存放區或資料集存取資料後,便可使用資料來為 ML 模型定型。 定型程序可能是呼叫自 ADF 的相同 ML 管線一部分。 或者,也可能是不同程序,例如 Jupyter 筆記本中的實驗。
由於資料集支援版本設定,而且來自管線的每個作業都會建立新版本,因此很容易就能了解用來為模型定型的資料是哪個版本。
直接從儲存體讀取資料
如果您不想要建立 ML 管線,則可以直接從使用 Azure Machine Learning 資料存放區和資料集來儲存準備好的資料時所用的儲存體帳戶來存取資料。
下列 Python 程式碼會示範如何建立連線至 Azure DataLake 第 2 代儲存體的資料存放區。 深入了解資料存放區以及可以找到服務主體權限的位置。

ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
接下來,請建立資料集來參考您要在機器學習工作中使用的檔案。
下列程式碼會從 csv 檔案 prepared-data.csv 建立 TabularDataset。 深入了解資料集類型和可接受的檔案格式。
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
從這裡,使用 prepared_dataset 來參考您準備好的資料,就和在定型指令碼中一樣。 了解如何在 Azure Machine Learning 中使用資料集來為模型定型。