本文將深度學習與機器學習進行比較,並說明它們如何融入更廣泛的 AI 類別。 了解您可以在 Azure Machine Learning 上建置的深度學習解決方案,例如詐騙偵測、語音和臉部辨識、情感分析,以及時間序列預測。
如需有關如何為解決方案選擇演算法的指導,請參閱機器學習演算法速查表。
Azure Machine Learning 中的 Foundry 模型是預先定型的深度學習模型,可針對特定使用案例進行微調。 欲了解更多資訊,請參閱「 探索 Azure 機器學習中的 Microsoft Foundry 模型 」及 「如何使用 Azure Machine Learning 策劃的開源基礎模型」。
深度學習、機器學習和人工智慧
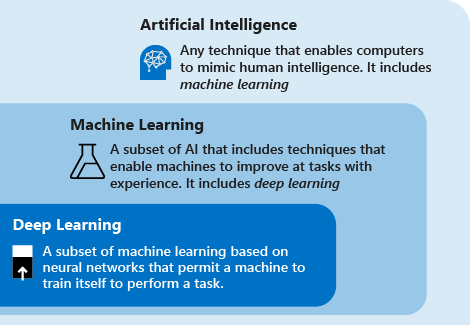
下列定義說明深度學習、機器學習、AI 之間的關係:
深度學習是以人工神經網路為基礎的機器學習子集。 此學習程序有很大的深度,因為人工神經網路結構包含了多個輸入層、輸出層和隱藏層。 每一層都包含轉換單位,可將輸入資料轉換成資訊,以供下一層用於特定預測工作。 由於這種結構,機器可以透過自己的資料處理來學習。
機器學習 是人工智慧的一個子集,它使用技術(例如深度學習),使機器能夠利用經驗來提高執行任務的能力。 學習過程由以下步驟組成:
- 將資料送入演算法。 (在此步驟中,您可以向模型提供其他資訊,例如,透過執行特徵擷取。
- 使用此資料來為模型定型。
- 測試及部署模型。
- 取用所部署的模型來自動進行預測工作。 (換句話說,就是呼叫並使用所部署的模型來接收模型所傳回的預測)。
人工智慧 是一種使電腦能夠模仿人類智慧的技術。 此技術包含了機器學習。
生成式 AI 是 AI 的一個子集,它使用技術(例如深度學習)來產生新內容。 例如,您可以使用生成式 AI 來建立影像、文字或音訊。 這些模型使用大量預先訓練的知識來產生這些內容。
藉由使用機器學習和深度學習技術,您可以建置電腦系統和應用程式,來進行通常會與人類智慧相關聯的工作。 這些工作包括影像辨識、語音辨識和語言翻譯。
深度學習和機器學習技術
現在您已經對機器學習與深度學習有何不同有了基本的了解,讓我們比較這兩種技術。 在機器學習中,需要告訴演算法如何透過消耗更多資訊來做出準確的預測。 (例如,透過執行特徵擷取。在深度學習中,演算法可以透過自己的資料處理來學習如何做出準確的預測,因為它使用了人工神經網路結構。
下表會更詳細地比較這兩種技術:
| 機器學習 | 深度學習 | |
|---|---|---|
| 資料點的數目 | 可以使用少量資料來進行預測。 | 需要使用大量定型資料才能進行預測。 |
| 硬體相依性 | 可以在低階機器上運作。 不需要大量計算能力。 | 依賴高階機器。 原本就會執行大量的矩陣乘法運算。 GPU 可以有效率地將這些作業最佳化。 |
| 特徵化程序 | 需要由使用者正確地識別並建立特徵。 | 透過資料學習高階特徵,並自行建立新特徵。 |
| 學習方法 | 將學習程序分割成許多較小的步驟。 然後,合併每個步驟的結果來形成單一輸出。 | 藉由以端對端方式解決問題,來逐步完成學習程序。 |
| 培訓時間 | 花相對較少的時間來定型,範圍從幾秒鐘到幾小時不等。 | 通常會花很長的時間來定型,因為深度學習演算法涉及眾多階層。 |
| 輸出 | 輸出通常是數值,例如分數或分類。 | 輸出可以有多種格式,例如文字、樂譜或聲音。 |
什麼是傳輸學習?
為深度學習模型定型通常需要大量的定型資料、高階計算資源 (GPU、TPU) 和較長的定型時間。 當您沒有可用的任何這些時,您可以使用稱為遷移學習的技術來縮短訓練過程。
傳輸學習是一種技術,可將從解決一個問題所獲得的知識運用到不同但相關的問題。
由於具有神經網路結構,第一組階層通常會包含較低層級的特徵,最後一組階層則會包含更接近所涉領域的較高層級特徵。 藉由重新訂定最後一組階層的用途,使其能夠應用在新領域或問題,便可大幅減少為新模型定型所需時間、資料和計算資源的數量。 例如,如果您已經有一個可辨識汽車的模型,您可以使用遷移學習來重新調整該模型的用途,以辨識卡車、摩托車和其他類型的車輛。
若要瞭解如何使用 Azure Machine Learning 中的開放原始碼架構,將轉移學習套用至影像分類,請參閱 使用轉移學習定型深度學習 PyTorch 模型。
深度學習使用案例
由於人工神經網路結構,深度學習擅長識別圖像、聲音、視訊和文字等非結構化資料中的模式。 因此,深度學習很快就讓許多產業發生轉變,範圍包括醫療保健、能源、財務和運輸。 這些產業現在都在重新思考傳統的商務程序。
後面幾個段落會說明一些最常見的深度學習應用。 在 Azure Machine Learning 中,您可以使用從開放原始碼架構建置的模型,或使用提供的工具來建置模型。
具名實體辨識
具名實體辨識是一種深度學習方法,此方法會取得一段文字來作為輸入,並將其轉換為預先指定的類別。 這些新資訊可以是郵遞區號、日期或產品 ID。 然後,您可以將這個資訊儲存在結構化結構描述中,以建置地址清單或作為身分識別驗證引擎的基準。
物件偵測
深度學習已運用到許多物件偵測使用案例。 物件偵測用於識別影像中的物件(例如汽車或人),並使用邊界框為每個物件提供特定位置。
物件偵測已用於遊戲、零售、觀光和自駕車等產業中。
產生影像標題
和影像辨識一樣,在為影像產生標題的作業中,系統必須為給定的影像產生標題以描述影像的內容。 當您可以偵測相片中的物件並為物件加上標籤時,下一步就是將這些標籤轉換成帶有描述性的句子。
為影像產生標題的應用程式通常會使用卷積神經網路來識別影像中的物件,然後使用週期性神經網路將標籤轉換成一致的句子。
機器翻譯
機器翻譯會接受某種語言的單字或句子,並自動將其翻譯為另一種語言。 機器翻譯的技術已出現很久,但深度學習在兩個特定領域實現了令人印象深刻的結果:自動翻譯文字 (以及將語音翻譯成文字) 和自動翻譯影像。
適當地轉換資料後,神經網路便可以了解文字、音訊和視覺信號。 機器翻譯可用來識別較大型音訊檔案中的聲音片段,並將說出口的話或影像謄寫為文字。
文字分析
基於深度學習方法的文字分析涉及分析大量文字資料(例如醫療文件或費用收據)、識別模式並從中建立有組織且簡潔的資訊。
組織使用深度學習來執行文本分析,以檢測內線交易並遵守政府法規。 另一個常見的例子是保險欺詐:文本分析通常用於分析大量文檔,以識別保險索賠欺詐的可能性。
人工神經網路
人工神經網路由數層的連線節點所組成。 深度學習模型會使用階層數龐大的神經網路。
以下各節描述了一些流行的人工神經網路拓撲。
前饋神經網路
前饋神經網路是最簡單的人工神經網路類型。 在前饋網路中,資訊只會從輸入層往輸出層單向移動。 前饋神經網路會藉由讓輸入通過一系列隱藏層來轉換輸入。 每一層都由一組神經元組成,每一層都與其前一層中的所有神經元完全相連。 最後一個完整連接的階層 (輸出層) 代表所產生的預測。
週期性神經網路 (RNN)
週期性神經網路是廣為使用的人工神經網路。 這些網路會儲存某一層的輸出,再將其饋送回輸入層,以協助預測該層的結果。 循環神經網路具有很強的學習能力。 其廣泛用於複雜的工作,例如時間序列預測、學習字跡和辨識語言。
卷積神經網路 (CNN)
卷積神經網路是特別有效的人工神經網路,會呈現獨特的架構。 其階層會組織為三個維度:寬度、高度和深度。 某一層的神經不會連接到下一層中的所有神經,而只會連接到該層神經的一小片區域。 最後的輸出會縮減為機率分數的向量,並沿著深度維度進行整理。
卷積神經網路用於視訊辨識、影像辨識和推薦系統等領域。
生成對抗網路 (GAN)
生成對抗網路是生成模型,經定型後可建立逼真的內容,例如影像。 它們由兩個稱為 生成器 和 鑑別器的網絡組成。 這兩個網路會同時進行定型作業。 在定型期間,生成器會使用隨機雜訊來建立與實際資料極為類似的新合成資料。 鑑別器會取得生成器的輸出來作為輸入,並使用實際資料來判斷所生成的內容是真實的還是合成的。 每個網絡都在相互競爭。 生成器試圖生成與真實內容無法區分的合成內容,而鑑別器則試圖將輸入正確分類為真實或合成。 然後,輸出便可用來更新這兩個網路的權數,讓這兩個網路更能實現其各自的目標。
生成對抗網路用於解決圖像到圖像的翻譯和年齡進展等問題。
轉換器
Transformer 是適合解決包含序列的問題的模型架構,例如文字或時間序列資料。 其由編碼器層和解碼器層組成。 編碼器會取得輸入,並將其對應至包含資訊 (例如內容) 的數值標記法。 解碼器會使用編碼器中的資訊來產生輸出,例如經過翻譯的文字。 轉換器與其他包含編碼器和解碼器的架構,彼此的差異在於關注子層。 注意力 是指根據輸入內容相對於序列中其他輸入的重要性來關注輸入的特定部分。 例如,當模型總結新聞文章時,並非所有句子都與描述主要思想相關。 藉由將焦點放在整篇內容中的關鍵字組,便能用一句話來完成概述,這句話就是標題。
Transformer 用於解決翻譯、文字產生、問答和文字摘要等自然語言處理問題。
以下是一些已實作的知名轉換器:
- Bidirectional Encoder Representations from Transformers (BERT)
- Generative Pre-trained Transformer 2 (GPT-2)
- Generative Pre-trained Transformer 3 (GPT-3)
後續步驟
下列文章說明在 Azure Machine Learning 中使用開放原始碼深度學習模型的更多選項: