設定 AutoML 以使用 SDK 和 CLI 定型時間序列預測模型
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
在本文中,您將瞭解如何在 Azure Machine Learning Python SDK 中使用 Azure Machine Learning 自動化 ML,來設定時間序列預測模型的 AutoML。
若要這樣做,您可以:
- 準備資料以進行定型。
- 在預測工作中設定特定的時間序列參數。
- 使用元件和管線協調定型、推斷和模型評估。
針對低程式碼體驗,請參閱教學課程:使用自動化機器學習來預測需求,以取得關於在 Azure Machine Learning 工作室中使用自動化 ML 的時間序列預測範例。
AutoML 會使用標準機器學習模型以及已知的時間序列模型來建立預測。 我們的方法包含目標變數的記錄資訊、輸入資料中使用者提供的功能,以及自動設計的功能。 然後,模型搜尋演算法會努力尋找具有最佳預測精確度的模型。 如需詳細資訊,請參閱我們關於預測方法和模型搜尋的文章。
必要條件
針對本文,您需要,
Azure Machine Learning 工作區。 若要建立工作區,請參閱建立工作區資源。
能夠啟動 AutoML 定型作業。 如需詳細資訊,請遵循設定 AutoML 的操作指南。
定型及驗證資料
AutoML 預測的輸入資料必須包含表格式格式的有效時間序列。 每個變數都必須在資料表中有自己的對應資料行。 AutoML 至少需要兩個資料行:時間資料行代表時間軸,目標資料行為要預測的數量。 其他資料行可以做為預測值。 如需詳細資訊,請參閱 AutoML 如何使用您的資料。
重要
將模型定型以預測未來值時,請確定在針對想要的範圍執行預測時,可使用定型中使用的所有特徵。
例如,目前股價的特徵可能會大幅增加定型準確度。 不過,如果想要預測較長範圍的情況,則可能無法精確地預測與未來時間序列點對應的未來股價值,且模型精確度可能會受到影響。
AutoML 預測工作會要求您的定型資料以 MLTable 物件表示。 MLTable 指定資料來源和載入資料的步驟。 如需詳細資訊和使用案例,請參閱 MLTable 操作指南。 例如,假設您的定型資料包含在本機目錄 ./train_data/timeseries_train.csv 中的 CSV 檔案中。
您可以使用 mltable Python SDK 建立 MLTable,如下列範例所示:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
此程式碼會建立新的檔案 ./train_data/MLTable,其中包含檔案格式和載入指示。
您現在使用 Azure Machine Learning Python SDK 來定義啟動定型作業所需的輸入資料物件,如下所示:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
您可以藉由建立 MLTable 並指定驗證資料輸入,以類似的方式指定驗證資料。 或者,如果您未提供驗證資料,AutoML 會自動從定型資料建立交叉驗證分割,以用於模型選取。 如需詳細資料,請參閱我們關於預測模型選取的文章。 另請參閱定型資料長度需求,以取得成功定型預測模型所需的定型資料量的詳細資料。
深入瞭解 AutoML 如何套用交叉驗證以防止過度調整。
計算要執行的實驗
AutoML 使用 Azure Machine Learning Compute,其為完全受控的計算資源,可用來執行定型作業。 在下列範例中,會建立名為 cpu-compute 的計算叢集:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()設定實驗
您可以使用 automl factory 函式,在 Python SDK 中設定預測作業。 下列範例示範如何藉由設定定型回合的主要計量和設定限制,以建立預測作業:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
訓練作業設定
預測工作有許多專屬於預測的設定。 這些設定中最基本的是定型資料和預測範圍中時間資料行的名稱。
使用 ForecastingJob 方法來設定這些設定:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
時間資料行名稱為必要設定,您通常應該根據預測案例來設定預測範圍。 如果您的資料包含多個時間序列,您可以指定時間序列識別碼資料行的名稱。 這些資料行在分組時會定義個別的序列。 例如,假設您有來自不同商店和品牌每小時銷售的資料。 下列範例示範如何設定假設資料包含名為「store」和「brand」的資料行的時間序列識別碼資料行:
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
如果未指定時間序列識別碼資料行,AutoML 會嘗試自動偵測資料中的時間序列識別碼資料行。
其他設定為選擇性的,將在下一節中檢閱。
選擇性預測作業設定
更多選擇性的設定可用於預測作業,例如啟用深度學習和指定目標移動時段彙總。 您可以在預測的參考文件中,取得參數的完整清單。
模型搜尋設定
有兩個選擇性設定可控制 AutoML 搜尋最佳模型的模型空間:allowed_training_algorithms 和 blocked_training_algorithms。 若要將搜尋空間限制為一組指定的模型類別,請使用 allowed_training_algorithms 參數,如下列範例所示:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
在此情況下,預測工作只會搜尋指數平滑法和彈性網路模型類別。 若要從搜尋空間中移除一組指定的模型類別,請使用 blocked_training_algorithms,如下列範例所示:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
現在,作業會搜尋除了 Prophet 以外的所有模型類別。 如需在 allowed_training_algorithms 和 blocked_training_algorithms中接受的預測模型名稱清單,請參閱定型屬性參考文件。 allowed_training_algorithms 和 blocked_training_algorithms 兩者其中之一 (無法同時) 可套用至定型執行。
啟用深度學習
AutoML 隨附稱為 TCNForecaster 的自訂深度神經網路 (DNN) 模型。 此模型是時態卷積網路 (TCN),可將常見的映像作業方法套用至時間序列模型化。 也就是說,一維的「原因」卷積形成網路的骨幹,讓模型在定型記錄中長期學習複雜的模式。 如需詳細資訊,請參閱我們的 TCNForecaster 文章。
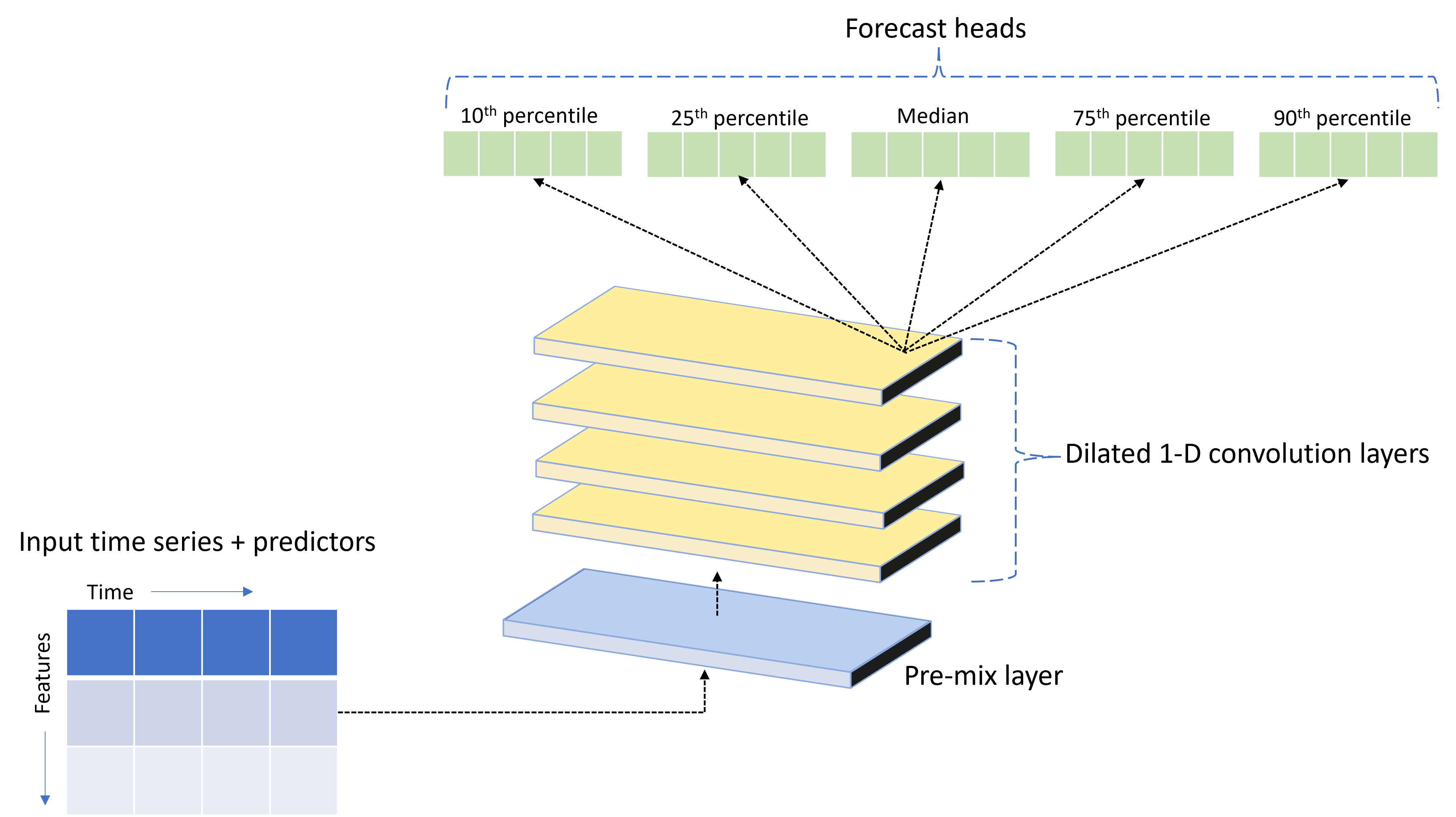
TCNForecaster 通常會在定型記錄中有數千個以上的觀察時,達到比標準時間序列模型更高的精確度。 不過,由於其容量較高,因此定型和掃掠 TCNForecaster 模型也需要更長的時間。
您可以在 AutoML 中啟用 TCNForecaster,方法是在定型設定中設定 enable_dnn_training 旗標,如下所示:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
根據預設,TCNForecaster 定型僅限於每個模型試用版單一計算節點和單一 GPU (如果有的話)。 針對大型資料案例,建議您將每個 TCNForecaster 試用版散發到多個核心/GPU 和節點。 如需詳細資訊和程式碼範例,請參閱我們的分散式定型文章一節。
如要啟用在 Azure Machine Learning 工作室中建立的 AutoML 實驗 DNN,請參閱工作室 UI 中工作類型設定的操作說明。
注意
- 當您針對以 SDK 建立的實驗啟用 DNN 時,系統會停用最佳模型說明。
- 自動化機器學習中對預測的 DNN 支援不支援在 Databricks 中啟動執行。
- 啟用 DNN 定型時,建議使用 GPU 計算類型
延隔和滾動時段功能
目標最近的值通常是預測模型中有影響力的特徵。 因此,AutoML 可以建立時間延隔和滾動時段彙總功能,因此可能改善模型精確度。
請考慮能源需求的預測案例,當中有天氣資料和歷史需求可用。 此資料表顯示最近三小時套用時段彙總時所發生的特徵工程。 根據定義設定中的三小時滾動時段,系統產生最小值、最大值和總和資料行。 例如,對於 2017 年 9 月 8 日上午 4:00 的觀察,會使用 2017 年 9 月 8 日上午 1:00 到上午 3:00 的需求值來計算最大值、最小值和總和。 這三小時時段會移位以在剩餘的資料列中填入資料。 如需詳細資料和範例,請參閱延隔功能一文。

您可以藉由設定上一個範例中的三小時滾動時段大小,以及您想要建立的延隔順序,來啟用目標的延隔和滾動時段彙總功能。 您也可以使用 feature_lags 設定來啟用功能的延隔時間。 在下列範例中,我們將所有這些設定都設定為 auto,讓 AutoML 藉由分析資料的相互關聯結構來自動判斷設定:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
短序列處理
若沒有足夠的資料點可執行模型開發的定型和驗證階段,自動化 ML 會將時間序列視為短序列。 如需長度需求的詳細資料,請參閱定型資料長度需求。
AutoML 有幾個可針對短序列進行的動作。 這些動作可使用 short_series_handling_config 設定來設定。 預設值為「自動」。下表描述了這些設定:
| 設定 | 描述 |
|---|---|
auto |
短序列處理的預設值。 - 若皆為短序列,請填補資料。 - 若並非所有序列皆為短序列,請將短序列卸除。 |
pad |
若 short_series_handling_config = pad,則自動化 ML 會新增隨機值至其所找到的每個短序列。 以下列出資料行類型及其填補方式:- 以 NaN 填補物件資料行 - 以 0 填補數值資料行 - 以 False 填補布林值/邏輯資料行 - 以白雜訊填補目標資料行。 |
drop |
若 short_series_handling_config = drop,則自動 ML 會捨棄短序列,不會將其用於定型或預測。 這些序列的預測將會傳回 NAN。 |
None |
未填補或卸除任何序列 |
在下列範例中,我們將設定短序列處理,讓所有短序列都填補至最小長度:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
警告
我們引入人工資料就是為了避免定型失敗,但填補卻可能會影響產出模型的正確性。 若有眾多短序列,可能也會對於可解釋性結果造成一些影響
頻率和目標資料彙總
使用頻率和資料彙總選項,可避免不規則資料所造成的失敗。 不規則的資料包含未遵循一組頻率的資料,例如每小時或每日資料。 銷售點資料是很好的不規則資料例子。 在這些情況下,AutoML 可以將您的資料彙總為所需的頻率,然後從彙總建置預測模型。
您需要設定 frequency 和 target_aggregate_function 設定來處理不規則的資料。 頻率設定接受 Pandas DateOffset 字串作為輸入。 彙總函式的支援值為:
| 函式 | 描述 |
|---|---|
sum |
目標值的總和 |
mean |
目標值的平均數或平均值 |
min |
目標的最小值 |
max |
目標的最大值 |
- 目標資料行值會根據指定的作業進行彙總。 一般而言,總和適用於大部分情節。
- 資料中的數值預測器資料行會依總和、平均值、最小值和最大值來彙總。 因此,自動化 ML 會產生後綴為聚合函數名稱的新資料行,並套用選取的彙總作業。
- 對於類別預測器資料行,資料會依模式彙總,也就是視窗中最突出的類別。
- 日期預測器資料行會依最小值、最大值和模式進行彙總。
下列範例會將頻率設定為每小時,並將彙總函數設定為加總:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
自訂交叉驗證設定
有兩個可自訂的設定可控制預測作業的交叉驗證:折疊數目 n_cross_validations,以及定義折疊之間時間位移的步驟大小 cv_step_size。 如需這些參數的意義詳細資訊,請參閱預測模型選取。 根據預設,AutoML 會根據資料的特性自動設定這兩個設定,但進階使用者可能想手動設定。 例如,假設您有每日銷售資料,而且您希望驗證設定包含五個折疊,相鄰折疊之間有七天的位移。 下列程式碼範例示範如何設定這些屬性:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
自訂特徵工程
根據預設,AutoML 會使用工程特徵來增強定型資料,以提高模型的精確度。 如需詳細資訊,請參閱自動化特徵工程。 您可以使用預測作業的特徵工程設定來自訂部分的前置處理步驟。
下表為支援的預測自訂:
| 自訂 | 描述 | 選項。 |
|---|---|---|
| 資料行用途更新 | 覆寫指定資料行的自動偵測特徵類型。 | "Categorical", "DateTime", "Numeric" |
| 轉換器參數更新 | 更新所指定插補程式的參數。 | {"strategy": "constant", "fill_value": <value>}、{"strategy": "median"}、{"strategy": "ffill"} |
例如,假設您有零售需求案例,其中資料包含價格、「特價」旗標和產品類型。 下列範例示範如何設定這些特徵的自訂類型和插補程式:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
若您在實驗中使用 Azure Machine Learning 工作室,請參閱如何在工作室中自訂特徵化。
提交預測作業
設定好所有設定之後,便會啟動預測作業,如下所示:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
提交作業之後,AutoML 會佈建計算資源、將特徵化和其他準備步驟套用至輸入資料,然後開始掃掠預測模型。 如需詳細資訊,請參閱我們關於預測方法和模型搜尋的文章。
使用元件和管線協調定型、推斷和評估
重要
此功能目前處於公開預覽。 此預覽版本沒有服務等級協定,不建議用於處理生產工作負載。 可能不支援特定功能,或可能已經限制功能。
如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
您的 ML 工作流程需要的可能不僅只是定型。 推斷或擷取較新資料的模型預測,以及評估具有已知目標值之測試集上的模型精確度,是您可以在 AzureML 中協調的其他常見工作,以及定型作業。 為了支援推斷和評估工作,AzureML 提供了元件,其為在 AzureML 管線中執行一個步驟的獨立式程式碼片段。
在下列範例中,我們會從用戶端登錄擷取元件程式碼:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
接下來,我們會定義 Factory 函式,以建立管線來協調定型、推斷和計量計算。 如需定型設定的詳細資訊,請參閱定型設定一節。
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
現在,我們將定義定型和測試資料輸入,假設它們包含在本機資料夾 ./train_data 和 ./test_data 中:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
最後,我們將建構管線、設定其預設計算並提交作業:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
提交之後,管線會依序執行 AutoML 定型、滾動評估推斷和計量計算。 您可以在 Studio UI 中監視並檢查執行。 執行完成時,滾動預測和評估計量可以下載到本機工作目錄:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
然後,您可以在 ./named-outputs/metrics_results/evaluationResult/metrics.json 中找到計量結果,並在 ./named-outputs/rolling_fcst_result/inference_output_file 中找到 JSON 行格式的預測。
如需滾動評估的詳細資訊,請參閱我們的預測模型評估文章。
大規模預測:許多模型
重要
此功能目前處於公開預覽。 此預覽版本沒有服務等級協定,不建議用於處理生產工作負載。 可能不支援特定功能,或可能已經限制功能。
如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
AutoML 中的許多模型元件可讓您平行定型及管理數百萬個模型。 如需許多模型概念的詳細資訊,請參閱許多模型一節。
許多模型定型設定
許多模型定型元件接受 AutoML 定型設定的 YAML 格式設定檔。 元件會將這些設定套用至其啟動的每個 AutoML 執行個體。 此 YAML 檔案的規格與預測作業加上其他 partition_column_names 和 allow_multi_partitions 參數相同。
| 參數 | 描述 |
|---|---|
| partition_column_names | 分組時,資料中的資料行名稱會定義資料分割。 許多模型定型元件會在每個分割區上啟動獨立的定型作業。 |
| allow_multi_partitions | 選擇性旗標,可在每個分割區包含一個以上的唯一時間序列時,為每個分割區定型一個模型。 預設值為 [False] 。 |
下列範例提供設定範本:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
在後續的範例中,我們假設設定儲存在路徑 ./automl_settings_mm.yml 上。
許多模型管線
接下來,我們會定義 Factory 函式,以建立管線來協調許多模型定型、推斷和計量計算。 下表詳述此 Factory 函式的參數:
| 參數 | 描述 |
|---|---|
| max_nodes | 定型作業中使用的計算節點數目 |
| max_concurrency_per_node | 要在每個節點上執行的 AutoML 處理序數目。 因此,許多模型作業的並行總數為 max_nodes * max_concurrency_per_node。 |
| parallel_step_timeout_in_seconds | 許多模型元件逾時,以秒數為單位。 |
| retrain_failed_models | 為失敗的模型啟用重新定型的旗標。 如果您先前執行了許多模型,導致某些資料分割的 AutoML 作業失敗,這會很有用。 啟用此旗標時,許多模型只會針對先前失敗的資料分割啟動定型作業。 |
| forecast_mode | 模型評估的推斷模式。 有效值為 "recursive" 和「rolling」。 如需詳細資訊,請參閱模型評估文章。 |
| forecast_step | 滾動預測的步驟大小。 如需詳細資訊,請參閱模型評估文章。 |
下列範例說明建構許多模型定型和模型評估管線的 Factory 方法:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
現在,我們將透過 Factory 函式建構管線,假設定型和測試資料分別位於本機資料夾 ./data/train 和 ./data/test。 最後,我們設定預設計算並提交作業,如下列範例所示:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
作業完成之後,可以使用與單一定型執行管線相同的程序在本機下載評估計量。
另請參閱許多模型需求預測筆記本,以取得更詳細的範例。
注意
許多模型定型和推斷元件會根據 partition_column_names 設定有條件地分割您的資料,讓每個分割區都位於自己的檔案中。 當資料非常大時,此程序可能會非常緩慢或失敗。 在此情況下,建議您先手動分割您的資料,再執行許多模型定型或推斷。
大規模預測:階層式時間序列
重要
此功能目前處於公開預覽。 此預覽版本沒有服務等級協定,不建議用於處理生產工作負載。 可能不支援特定功能,或可能已經限制功能。
如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
AutoML 中的階層式時間序列 (HTS) 元件可讓您在階層式結構的資料上定型大量模型。 如需詳細資訊,請參閱 HTS 文章小節。
HTS 定型設定
HTS 定型元件接受 AutoML 定型設定的 YAML 格式設定檔。 元件會將這些設定套用至其啟動的每個 AutoML 執行個體。 此 YAML 檔案的規格與預測作業加上其他階層式資訊相關參數相同:
| 參數 | 描述 |
|---|---|
| hierarchy_column_names | 資料中的資料行名稱清單,定義資料的階層式結構。 此清單中的資料行順序會決定階層層級;彙總的程度會隨著清單索引而減少。 也就是說,清單中的最後一個資料行將定義階層的分葉 (最分類式) 層級。 |
| hierarchy_training_level | 用於預測模型定型的階層層級。 |
以下顯示的是範例設定:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
在後續的範例中,我們假設設定儲存在路徑 ./automl_settings_hts.yml 上。
HTS 管線
接下來,我們會定義 Factory 函式,以建立管線來協調 HTS 定型、推斷和計量計算。 下表詳述此 Factory 函式的參數:
| 參數 | 描述 |
|---|---|
| forecast_level | 要擷取預測的階層層級 |
| allocation_method | 當預測為分類式時要使用的配置方法。 有效值為 "proportions_of_historical_average" 和 "average_historical_proportions"。 |
| max_nodes | 定型作業中使用的計算節點數目 |
| max_concurrency_per_node | 要在每個節點上執行的 AutoML 處理序數目。 因此,HTS 作業的並行總數為 max_nodes * max_concurrency_per_node。 |
| parallel_step_timeout_in_seconds | 許多模型元件逾時,以秒數為單位。 |
| forecast_mode | 模型評估的推斷模式。 有效值為 "recursive" 和「rolling」。 如需詳細資訊,請參閱模型評估文章。 |
| forecast_step | 滾動預測的步驟大小。 如需詳細資訊,請參閱模型評估文章。 |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
現在,我們將透過 Factory 函式建構管線,假設定型和測試資料分別位於本機資料夾 ./data/train 和 ./data/test。 最後,我們設定預設計算並提交作業,如下列範例所示:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
作業完成之後,可以使用與單一定型執行管線相同的程序在本機下載評估計量。
另請參閱階層式時間序列需求預測筆記本,以取得更詳細的範例。
注意
HTS 定型和推斷元件會根據 hierarchy_column_names 設定有條件地分割您的資料,讓每個分割區都位於自己的檔案中。 當資料非常大時,此程序可能會非常緩慢或失敗。 在此情況下,建議您先手動分割您的資料,再執行 HTS 定型或推斷。
大規模預測:分散式 DNN 定型
- 若要了解分散式定型如何針對預測工作運作,請參閱我們的大規模預測一文。
- 如需程式碼範例,請參閱我們的設定表格式資料的分散式定型文章一節。
Notebook 範例
如需進階預測設定的詳細程式碼範例,請參閱預測範例筆記本,包括:
下一步
- 深入了解如何將 AutoML 模型部署到線上端點。
- 瞭解關於可解釋性:自動化機器學習中的模型說明 (預覽)的資訊。
- 了解 AutoML 如何組建預測模型。
- 了解大規模預測。
- 了解如何針對各種預測案例設定 AutoML。
- 了解預測模型的推斷和評估。