設定 AutoML 以使用 Python (SDKv1) 定型時間序列預測模型

在本文中,您將瞭解如何在 Azure Machine Learning Python SDK 中使用 Azure Machine Learning 自動化 ML,來設定時間序列預測模型的 AutoML 定型。
若要這樣做,您可以:
- 準備資料以進行時間序列模型化。
- 在
AutoMLConfig物件中設定特定的時間序列參數。 - 使用時間序列資料執行預測。
針對低程式碼體驗,請參閱教學課程:使用自動化機器學習來預測需求,以取得關於在 Azure Machine Learning 工作室中使用自動化 ML 的時間序列預測範例。
不同於傳統的時間序列方法,在自動化 ML 中,過去的時間序列值會進行「樞紐處理」,以與其他預測變量一起成為迴歸輸入變數的附加維度。 這個方法會在定型期間結合多個內容變數及其相互關聯性。 由於有多個因素可能會影響預測,因此此方法非常吻合真實世界的預測案例。 例如在預測銷售時,歷程記錄趨勢、匯率和價格的相互作用全都會共同推動銷售結果。
必要條件
針對本文,您需要,
Azure Machine Learning 工作區。 若要建立工作區,請參閱建立工作區資源。
本文假設您大致上已熟悉如何設定自動化機器學習實驗。 請遵循操作說明,以查看主要的自動化機器學習實驗設計模式。
重要
本文中的 Python 命令需要最新的
azureml-train-automl套件版本。- 將最新的
azureml-train-automl套件安裝到您的本機環境。 - 如需最新
azureml-train-automl套件的詳細資訊,請參閱版本資訊。
- 將最新的
定型及驗證資料
自動化機器學習中預測迴歸工作類型與迴歸工作類型之間最重要的差異,就是在定型資料中包含代表有效時間序列的特徵。 一般時間序列具有妥善定義且一致的頻率,且在連續時間範圍內的每個取樣點都有一個值。
重要
將模型定型以預測未來值時,請確定在針對想要的範圍執行預測時,可使用定型中使用的所有特徵。 例如,建立需求預測時,包括目前股價的特徵可能會大幅增加定型準確度。 不過,如果想要預測較長範圍的情況,則可能無法精確地預測與未來時間序列點對應的未來股價值,且模型精確度可能會受到影響。
您可直接在 AutoMLConfig 物件中,指定個別的定型資料和驗證資料。 深入了解 AutoMLConfig。
針對時間序列預測,系統依預設僅會使用移動原點交叉驗證 (ROCV) 來執行驗證。 ROCV 會使用原始時間點來將序列分割成定型和驗證資料。 滑動時間原點即會產生交叉驗證摺疊。 此策略會保留時間序列資料完整性,並消除資料外洩的風險。
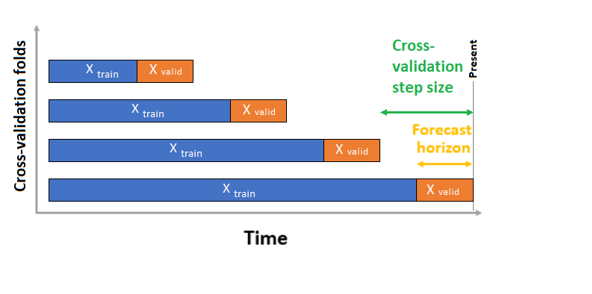
將定型和驗證資料當作一個資料集傳遞至參數 training_data。 使用參數 n_cross_validations 設定交叉驗證摺疊的數目,並使用 cv_step_size 設定兩個連續交叉驗證摺疊之間的期間數。 您也可以將任一或兩個參數保留空白,而 AutoML 會自動加以設定。
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
您也可以帶入自己的驗證資料,如需深入瞭解,請參閱〈在 AutoML 中設定資料分割和交叉驗證〉。
深入瞭解 AutoML 如何套用交叉驗證以防止過度調整模型。
設定實驗
AutoMLConfig 物件會定義自動化機器學習工作所需的設定和資料。 預測模型的設定類似於設定標準迴歸模型,但特定的模型、設定選項和特徵化步驟則特別存在於時間序列資料中。
支援的模型
自動化機器學習會在建立和微調程序的過程中,自動嘗試不同的模型和演算法。 身為使用者,您不需要指定演算法。 針對預測實驗,原生時間序列和深度學習模型都屬於建議系統的一部分。
提示
傳統的迴歸模型也會做為建議系統的一部分進行測試,以執行預測實驗。 請參閱 SDK 參考文件中的支援模型完整清單。
組態設定
類似於迴歸問題,您可定義標準定型參數,例如工作類型、反覆項目數目、定型資料,以及交叉驗證的數目。 預測工作需要 time_column_name 和 forecast_horizon 參數來設定實驗。 如果資料包含多個時間序列,例如多個商店的銷售資料或不同州省的能源資料,自動化 ML 會自動偵測到此情況,並為您設定 time_series_id_column_names 參數 (預覽)。 您也將其他參數包含在內,更完善地設定執行,如需關於可包含哪些內容的詳細資訊,請參閱選用設定一節。
重要
自動時間序列識別目前為公開預覽狀態。 在此提供的這個預覽版本並無服務等級協定。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
| 參數名稱 | 描述 |
|---|---|
time_column_name |
用來指定輸入資料中用來建置時間序列並推斷其頻率的日期時間資料行。 |
forecast_horizon |
定義您想向前預測的期間數。 範圍是以時間序列頻率為單位。 單位是以預測器應預測出的定型資料時間間隔為基礎,例如,每月、每週。 |
下列程式碼,
- 使用
ForecastingParameters類別來定義實驗定型的預測參數 - 將
time_column_name設定為資料集內的day_datetime欄位。 - 將
forecast_horizon設定為 50,以預測整個測試集。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
這些 forecasting_parameters 隨後會與 forecasting 工作類型、主要計量、允出準則和定型資料,一同傳遞至您的標準 AutoMLConfig 物件。
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
使用自動化 ML 成功定型預測模型所需的資料量,會受到您設定 AutoMLConfig 時所指定的 forecast_horizon、n_cross_validations 和 target_lags 或 target_rolling_window_size 值所影響。
下列公式會計算用來建構時間序列特徵所需的歷程資料量。
所需的最少歷程資料量:(2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
若資料集內的任何序列皆不符合所指定相關設定的所需歷程資料量,則會引發 Error exception。
特徵化步驟
在每個自動化機器學習實驗中,系統預設會將自動調整和正規化技術套用至您的資料。 這些技術屬於特徵化的類型,可協助對不同規模的特徵較為敏感的「特定」演算法。 深入瞭解 在 AutoML 中特徵化的預設特徵化步驟
不過,下列步驟只會針對 forecasting 工作類型執行:
- 偵測時間序列取樣頻率 (例如,每小時、每天、每週),並為不存在的時間點建立新記錄,使序列連續不斷。
- 插補目標中的遺漏值 (透過向前填滿),以及插補特徵資料行中的遺漏值 (使用中位數的資料行值)
- 建立以時間序列識別碼為基礎的特徵,以維持跨不同序列的固定效果
- 建立時間型特徵,以協助學習季節性模式
- 將類別變數編碼為數值數量
- 偵測非固定時間序列並自動加以區別,以減輕單位根目錄的影響。
若要檢視從時間序列資料產生的可能工程功能完整清單,請參閱 TimeIndexFeaturizer 類別。
注意
自動化機器學習特徵化步驟 (功能標準化、處理遺漏的資料、將文字轉換為數值等等) 會成為基礎模型的一部分。 使用模型進行預測時,定型期間所套用的相同特徵化步驟會自動套用至您的輸入資料。
自訂特徵化
您也可以選擇自訂特徵化設定,以確保用來定型 ML 模型的資料和特徵會產生相關的預測。
支援的 forecasting 工作自訂項目包含:
| 自訂 | 定義 |
|---|---|
| 資料行用途更新 | 覆寫所指定資料行的自動偵測特徵類型。 |
| 轉換器參數更新 | 更新所指定轉換器的參數。 系統目前支援 Imputer (fill_value 和中位數)。 |
| 卸除資料行 | 指定不進行特徵化的資料行。 |
如要使用 SDK 自訂特徵化,請在您的 AutoMLConfig 物件中指定 "featurization": FeaturizationConfig。 深入瞭解自訂特徵化。
注意
從 SDK 1.19 版起,卸除資料行功能已遭取代。 在您的自動化 ML 實驗中取用資料行之前,請先在資料清除過程中將這些資料行自資料集卸除。
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
若您在實驗中使用 Azure Machine Learning 工作室,請參閱如何在工作室中自訂特徵化。
選擇性設定
更多選擇性的設定可用於預測工作,例如啟用深度學習和指定目標移動時段彙總。 您可以在ForecastingParameters SDK 參考文件中,取得更多參數的完整清單。
頻率和目標資料彙總
使用頻率 (freq) 參數來協助避免因不規則資料所造成的失敗。 不規則的資料包含未遵循一組頻率的資料,例如每小時或每日資料。
針對高度異常的資料或不同的商務需求,使用者可選擇性地設定所需的預測頻率 (freq) 並指定 target_aggregation_function 來彙總時間序列的目標資料行。 使用 AutoMLConfig 物件中的這兩個設定,有助於節省資料準備的時間。
針對目標資料行值支援的彙總作業包括:
| 函式 | 描述 |
|---|---|
sum |
目標值的總和 |
mean |
目標值的平均數或平均值 |
min |
目標的最小值 |
max |
目標的最大值 |
啟用深度學習
注意
自動化機器學習中對預測的 DNN 支援處於預覽階段,且不支援本機執行或在 Databricks 中啟動。
您也可以運用深度神經網路 (DNN) 來套用深度學習,以改善模型的分數。 自動化 ML 的深度學習可供預測單一變量和多變量時間序列資料。
深度學習模型有三種內建功能:
- 可從輸入到輸出的任意對應中學習
- 支援多個輸入和輸出
- 可從跨越長序列的輸入資料中自動擷取模式。
如要啟用深度學習,請在 AutoMLConfig 物件中設定 enable_dnn=True。
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
警告
當您針對以 SDK 建立的實驗啟用 DNN 時,系統會停用最佳模型說明。
如要啟用在 Azure Machine Learning 工作室中建立的 AutoML 實驗 DNN,請參閱工作室 UI 中工作類型設定的操作說明。
目標移動時段彙總
預測工具的最佳資訊通常是目標最新的值。 目標移動時段彙總可讓您新增資料值的移動彙總做為特徵。 產生和使用這些特徵做為額外的內容資料,可協助提高定型模型的正確性。
例如,假設您想要預測能源需求。 您可能想要新增三天的移動時段特徵,將加熱空間的熱變化納入考量。 在此範例中,請在 AutoMLConfig 建構函式中設定 target_rolling_window_size= 3,以建立此時段。
此資料表顯示套用時段彙總時所發生的特徵工程。 根據定義設定中的三個滑動視窗,系統產生最小值、最大值和總和資料行。 每個資料列都有新的計算特徵,如果是 2017 年 9 月 8 日上午 4:00 的時間戳記,則會使用 2017 年 9 月 8 日上午 1:00 到上午 3:00 的需求值來計算最大值、最小值和總和。 這三個時段會移位以在剩餘的資料列中填入資料。

請檢視套用目標移動時段彙總特徵的 Python 程式碼範例。
短序列處理
若沒有足夠的資料點可執行模型開發的定型和驗證階段,自動化 ML 會將時間序列視為短序列。 每個實驗的資料點數目各不相同,且取決於 max_horizon、交叉驗證分割的數目和模型回顧的長度,也就是建構時間序列功能所需的最大歷程記錄。
自動化 ML 預設會使用 ForecastingParameters 物件中的 short_series_handling_configuration 參數,來提供簡短序列處理。
如要啟用短序列處理,也必須定義 freq 參數。 如要定義每小時頻率,我們會設定 freq='H'。 瀏覽 pandas 時間序列頁面的 DataOffset 物件一節,以檢視頻率字串選項。 如要變更預設行為 short_series_handling_configuration = 'auto',請在 ForecastingParameter 物件中更新 short_series_handling_configuration 參數。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
下表會摘要說明 short_series_handling_config 的可用設定。
| 設定 | 描述 |
|---|---|
auto |
簡短序列處理的預設值。 - 若皆為短序列,請填補資料。 - 若並非所有序列皆為短序列,請將短序列卸除。 |
pad |
若 short_series_handling_config = pad,則自動化 ML 會新增隨機值至其所找到的每個短序列。 以下列出資料行類型及其填補方式:- 以 NaN 填補物件資料行 - 以 0 填補數值資料行 - 以 False 填補布林值/邏輯資料行 - 目標資料行則是以零平均值和標準差 1 的隨機值填補。 |
drop |
若 short_series_handling_config = drop,則自動 ML 會捨棄短序列,不會將其用於定型或預測。 這些序列的預測會傳回 NaN。 |
None |
未填補或卸除任何序列 |
警告
我們引入人工資料的目的就在於讓定型免於發生失敗,但填補卻可能會影響產出模型的正確性。 若有眾多短序列,可能也會對於可解釋性結果造成一些影響
非恆定時間序列偵測與處理
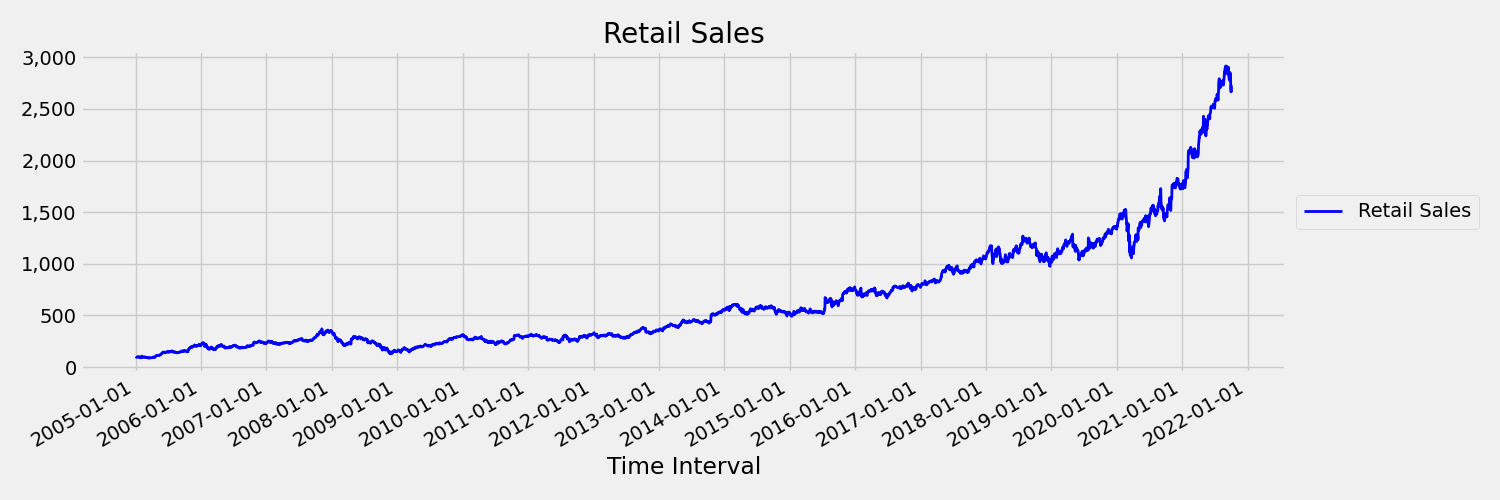
時間序列其時間 (平均值和變異數) 隨著時間的變化稱為非恆定。 例如,表現出隨機趨勢的時間序列本質上不是恆定的。 為了將此視覺化,下圖繪製一般向上趨勢的數列。 現在,計算和比較數列第一個和下半部的平均值 (平均)。 兩者相同嗎? 在這裡,繪圖前半部序列的平均值小於後半部序列的平均值。 序列的平均值取決於所查看的時間間隔,也就是時間變化動差的範例。 在這裡,序列的平均值是一級動差。
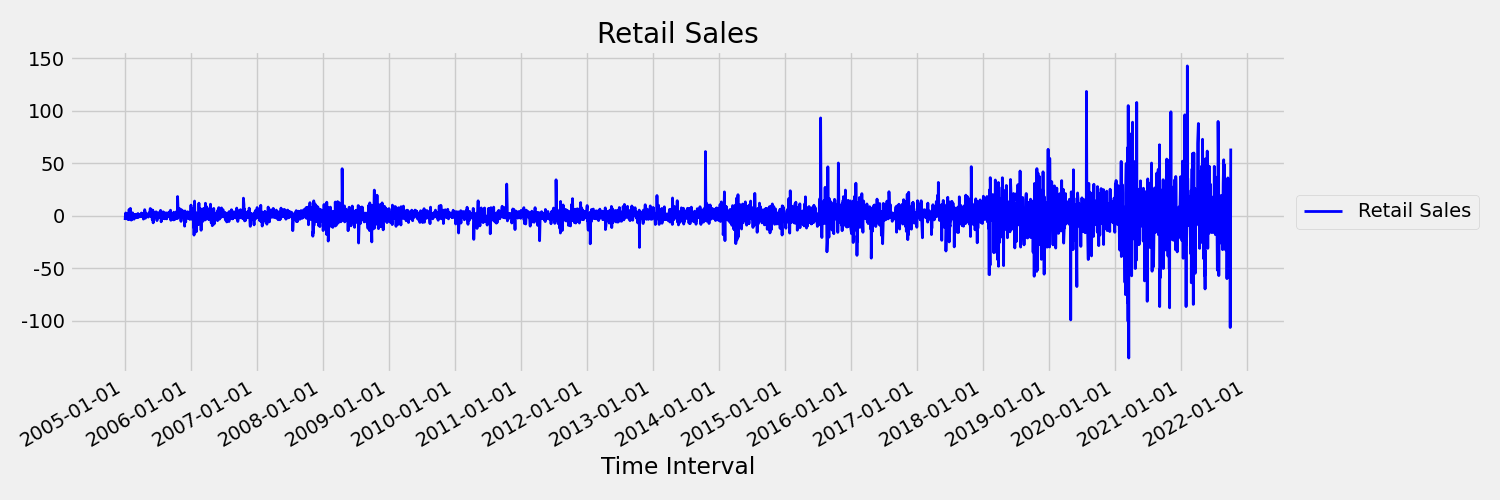
接下來,讓我們檢查以第一個差異繪製原始序列的映像,$x_t = y_t - y_{t-1}$,其中 $x_t$ 是零售銷售額的變化,$y_t$ 和 $y_{t-1}$ 分別代表原始數列及其第一個延遲。 無論查看的時間範圍為何,序列的平均值大致是常數。 這是一階恆定時間序列的範例。 我們新增一階字詞的原因是因為一級 (平均值)不會隨著時間間隔而改變,因此無法求出變異數,這是二級動差。
AutoML 機器學習模型原本就無法處理隨機趨勢,或與非恆定時間序列相關的其他已知問題。 因此,如果存在這類趨勢,其樣本預測精確度就會「不佳」。
AutoML 會自動分析時間序列資料集,以檢查其是否恆定。 偵測到非恆定時間序列時,AutoML 會自動套用差異轉換,以減輕非恆定時間序列的影響。
執行實驗
當 AutoMLConfig 物件就緒時,即可提交實驗。 在模型完成之後,請擷取最佳的執行反覆項目。
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
使用最佳模型進行預測
使用最佳模型反覆運算,預測未用來定型模型的資料值。
使用滾動式預測評估模型精確度
將模型放入生產環境之前,您應該在定型資料中保留的測試集上評估其精確度。 最佳做法程序是所謂的滾動式評估,其針對測試集將訓練的預測工具時間向前滾動,將錯誤計量平均於數個預測時段,以取得某組所選計量的統計健全估計值。 在理想情況下,評估的測試集相對於模型的預測時間範圍很長。 預測錯誤的估計值可能是統計上的雜訊,因此比較不可靠。
例如,假設您對於每日銷售定型模型,以預測未來最多兩週 (14 天) 的需求。 如果有足夠的歷史資料可用,您可保留最後數個月的資料,甚至是測試集的一年資料。 滾動式評估從產生測試集前兩週的提前 14 天預測開始。 然後,預測工具會在測試集內提前一些天數,而您從新位置產生另一個提前 14 天的預測。 此程序會繼續執行,直到您到達測試集的結尾為止。
若要進行滾動式評估,您可以呼叫 fitted_model 的 rolling_forecast 方法,然後在結果上計算所需的計量。 例如,假設您在名為 test_features_df 的 pandas DataFrame 中具有測試集功能,並在名為 test_target 的 numpy 陣列中有目標的設定集實際值。 使用平均平方誤差的滾動式評估會顯示在下列程式碼範例中:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
在上述範例中,滾動式預測的步驟大小設定為 1,這表示每次反覆運算時,預測工具會在我們的需求預測範例中提前 1 個週期或 1 天。 因此 rolling_forecast 傳回的預測總數取決於測試集的長度和此步驟大小。 如需詳細資訊和範例,請參閱 rolling_forecast() 文件及從訓練資料筆記本預測。
預測未來
forecast_quantiles() 函式可指定預測的啟動時機,與通常用於分類和迴歸工作的 predict() 方法有所不同。 依預設,forecast_quantiles () 方法會產生點預測或平均值/中位數預測,而這種預測沒有不確定性範圍。 請參閱不使用定型資料來執行預測筆記本 (英文) 以進一步瞭解。
在下列範例中,您會先將 y_pred 中的所有值取代為 NaN。 在此案例中,預測來源位於定型資料的結尾。 不過,如果只以 NaN 取代 y_pred 的後半部分,則此函式不會修改前半部分的數值,但會預測後半部分的 NaN 值。 此函式會傳回預測的值和調整後的特徵。
您也可以使用 forecast_quantiles() 函式中的 forecast_destination 參數,預測直到指定日期為止的值。
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
客戶時常會想瞭解分佈特定分位數的預測。 例如,當您使用預測來控制雜貨商品或雲端服務虛擬機器等庫存時。 在這種情況下,控制點通常會像是「我們希望商品的庫存在 99% 的時間中都不會有耗盡的時候」。 下列範例將示範如何指定您想要查看的預測分位數,例如第 50 個或第 95 個百分位數。 若您未指定分位數 (如上述程式碼範例所示),則只會產生第 50 個百分位數的預測。
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
您可以計算模型計量,例如均方根誤差 (RMSE) 或平均絕對百分比誤差 (MAPE),以協助您評估模型效能。 如需範例,請參閱自行車共用需求筆記本的〈評估〉一節。
決定整體模型正確性後,最實際的下一步即是使用模型來預測未知的未來值。
如果使用與測試集 test_dataset 相同的格式來提供資料集,但具有未來的日期時間,則所產生預測集是每個時間序列步驟的預測值。 假設資料集內的最後一個時間序列記錄是 2018 年 12 月 31 日。 如要預測隔天的需求 (或需要預測的週期數,<= forecast_horizon),請為每間商店建立 2019 年 1 月 1 日的單一時間序列記錄。
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
重複必要的步驟,將此未來資料載入至資料框架,然後執行 best_run.forecast_quantiles(test_dataset) 來預測未來值。
注意
啟用 target_lags 和/或 target_rolling_window_size 時,在範例預測中不支援使用自動化 ML 進行預測。
大規模預測
在某些情況下單一機器學習模型不足,而需要多個機器學習模型。 例如,預測品牌的每間個別商店銷售額,或量身打造個別使用者的體驗。 為每個執行個體建立模型,可能會改善許多機器學習問題的結果。
群組是時間序列預測的概念,可將時間序列合併以針對每個群組定型個別模型。 若您的時間序列需要平滑化、填滿,或群組中的實體可從其他實體的歷程記錄或趨勢中獲益,則這種方法會特別有用。 許多模型和階層式時間序列預測,都是由自動化機器學習為這些大規模預測案例提供的解決方案。
許多模型
使用自動化機器學習的 Azure Machine Learning 許多模型方案,可讓使用者同時定型和管理數百萬個模型。 許多模型解決方案加速器會使用 Azure Machine Learning 管線來訓練模型。 具體而言,系統會使用 [管線] 物件和 ParalleRunStep,並需要透過 ParallelRunConfig 設定的特定設定參數。
下圖顯示許多模型解決方案的工作流程。

下列程式碼示範使用者設定許多模型執行所需的金鑰參數。 查看許多模型 - 自動化 ML 筆記本 (英文),以取得許多模型預測範例
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
階層式時間序列預測
在大部分的應用程式中,客戶必須瞭解其在業務宏觀和微觀層級的預測。 Forcasts 可以預測不同地理位置的產品銷售,或瞭解公司不同組織預期員工的需求。 將機器學習模型定型,並有智慧地預測階層資料,是不可或缺的能力。
階層式時間序列是一種結構,在其中每個唯一序列都會依據維度 (例如地理位置或產品類型) 排列為階層。 下列範例會顯示具有形成階層唯一屬性的資料。 在這裡階層的定義方式如下:產品類型,例如耳機或平板電腦、將產品類型分割為配件和裝置的產品類別,以及產品的銷售區域。

為了進一步將其視覺化,階層的分葉層級包含所有時間序列,並具有屬性值的唯一組合。 在階層中的層級每高一層,就會少考慮一個定義時間序列的維度,並將來自較低層級的每組子節點彙總至父節點。

階層式時間序列解決方案是以「許多模型解決方案」為建置基礎,並共用類似的組態設定。
下列程式碼示範用來設定階層式時間序列預測執行的金鑰參數。 如需端對端範例,請參閱階層式時間序列 - 自動化 ML 筆記本 (英文)。
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Notebook 範例
如需進階預測設定的詳細程式碼範例,請參閱預測範例筆記本,包括:
下一步
- 深入了解如何將 AutoML 模型部署到線上端點。
- 瞭解關於可解釋性:自動化機器學習中的模型說明 (預覽)的資訊。
- 瞭解 AutoML 如何組建預測模型。