
在本文中,您會了解如何使用 Azure CLI 和元件來建立及執行機器學習管線。 您可以建立管線而不使用元件,但元件可提供彈性並啟用重複使用。 Azure Machine Learning 管線可以在 YAML 中定義,並從 CLI 執行、以 Python 撰寫,或透過拖放 UI 在 Azure Machine Learning Studio 設計工具中撰寫。 本文著重於 CLI。
必要條件
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
範例存放庫的複本。 您可以使用下列命令來複製存放庫:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
建議的預讀
使用元件建立您的第一個管線
首先,您將使用範例建立具有元件的管線。 這麼做可讓您初步瞭解 Azure Machine Learning 中的管線和元件外觀。
在cli/jobs/pipelines-with-components/basics存放庫的azureml-examples目錄中,移至3b_pipeline_with_data子目錄。 此目錄中有三種類型的檔案。 這些是您在建置自己的管線時需要建立的檔案。
pipeline.yml。 此 YAML 檔案會定義機器學習管線。 它描述如何將完整機器學習工作分成多步驟工作流程。 例如,請考慮使用歷程記錄數據來定型銷售預測模型的簡單機器學習工作。 您可能想要建置包含數據處理、模型定型和模型評估步驟的循序工作流程。 每個步驟都是一個元件,具有定義完善的介面,而且可以獨立開發、測試及優化。 管線 YAML 也會定義子步驟如何連線到管線中的其他步驟。 例如,模型定型步驟會產生模型檔案,並將模型檔案傳遞至模型評估步驟。
component.yml。 這些 YAML 檔案會定義元件。 它們包含下列資訊:
- 元數據:名稱、顯示名稱、版本、描述、類型等等。 元數據有助於描述和管理元件。
- 介面:輸入和輸出。 例如,模型定型元件會將定型數據和 Epoch 數目當做輸入,併產生定型的模型檔案作為輸出。 定義介面之後,不同的小組可以獨立開發和測試元件。
- 命令、程式代碼和環境:要執行元件的命令、程式代碼和環境。 命令列指令用於執行元件。 程式代碼通常是指原始程式碼目錄。 此環境可以是 Azure Machine Learning 環境(策劃或客戶建立)、Docker 映射或 conda 環境。
component_src。 這些是特定元件的原始程式碼目錄。 它們包含元件中執行的原始程式碼。 您可以使用慣用的語言,包括 Python、R 和其他語言。 程式碼必須通過指令碼命令執行。 原始程式碼可以從殼層命令行取得一些輸入,以控制此步驟的執行方式。 例如,訓練步驟可能會采用訓練數據、學習速率以及 Epoch 數目來控制訓練過程。 殼層命令的引數可用來將輸入和輸出傳遞至程式碼。
您現在會使用 3b_pipeline_with_data 範例來建立管線。 下列各節會進一步說明每個檔案。
首先,使用下列命令列出可用的計算資源:
az ml compute list
如果您沒有叢集,請執行此指令來建立名為 cpu-cluster 的叢集:
注意
略過此步驟以使用無伺服器計算。
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
現在,執行下列命令,以建立pipeline.yml檔案中定義的管線作業。 計算目標會在 pipeline.yml 檔案中參考為 azureml:cpu-cluster。 如果您的計算目標使用不同的名稱,請記得在 pipeline.yml 檔案中更新。
az ml job create --file pipeline.yml
您應該會收到 JSON 字典,其中包含管線作業的相關信息,包括:
| 關鍵 | 描述 |
|---|---|
name |
以 GUID 為基礎的工作名稱。 |
experiment_name |
在工作室中用來組織作業的名稱。 |
services.Studio.endpoint |
用於監視和檢閱管線工作的 URL。 |
status |
工作的狀態。 這也許在這一點上為Preparing。 |
移至 services.Studio.endpoint URL 以檢視管線的視覺效果:
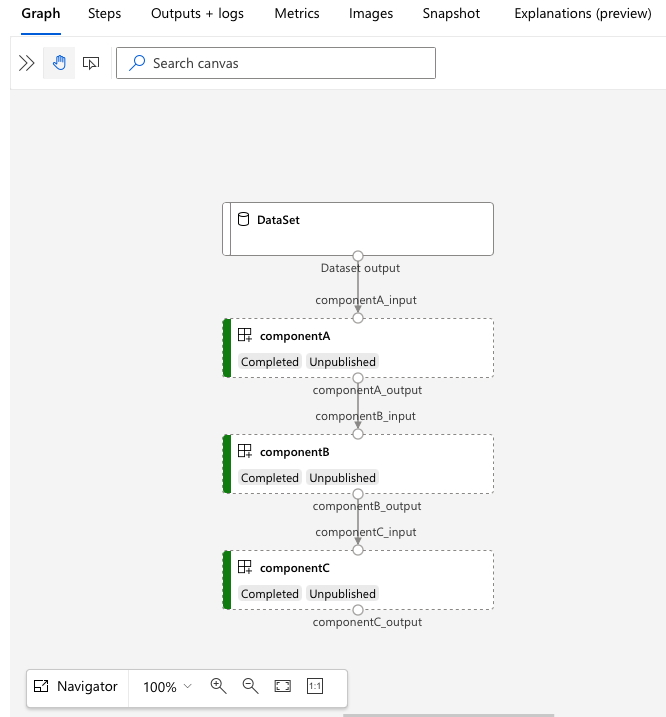
了解管線定義 YAML
您現在會在 3b_pipeline_with_data/pipeline.yml 檔案中查看管線定義。
注意
若要使用無伺服器計算,請將 default_compute: azureml:cpu-cluster 取代為此檔案中的 default_compute: azureml:serverless。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
下表描述管線 YAML 架構最常使用的欄位。 若要深入了解,請參閱完整管線 YAML 結構描述。
| 關鍵 | 描述 |
|---|---|
type |
必要。 作業類型。 在管線作業中,必須是 pipeline。 |
display_name |
Studio UI 中管線作業的顯示名稱。 可在 Studio UI 中編輯。 它不需要在工作區中的所有作業中是唯一的。 |
jobs |
必要。 要當做管線內步驟執行之個別作業集合的字典。 這些作業可視為父管線作業的子作業。 在目前版本中,管線中支援的作業類型為 command 和 sweep。 |
inputs |
管線作業的輸入參數表。 鍵是作業中輸入的名稱,而值是輸入的值。 您可以使用 ${{ parent.inputs.<input_name> }} 表達式,藉由管線中個別步驟作業的輸入來參考這些管線輸入。 |
outputs |
管線作業之輸出組態的字典。 索引鍵是作業內容中輸出的名稱,而值是輸出組態。 您可以使用 ${{ parents.outputs.<output_name> }} 表達式,藉由管線中個別步驟作業的輸出來參考這些管線輸出。 |
3b_pipeline_with_data範例包含三步驟管線。
- 三個步驟定義於
jobs底下。 三個步驟的類型都是command。 每個步驟的定義都位於對應的component*.yml檔案中。 您可以在 3b_pipeline_with_data 目錄中看到元件 YAML 檔案。componentA.yml在下一節中會說明。 - 此管線具有數據相依性,這在真實世界的管線中很常見。 元件 A 從位於
./data的本機資料夾中接收數據輸入(第 18-21 行),並將其輸出傳遞到元件 B(第 29 行)。 元件 A 的輸出可以參考為${{parent.jobs.component_a.outputs.component_a_output}}。 -
default_compute定義管線的預設計算。 如果底下的jobs元件定義不同的計算,則會遵守元件特定的設定。

在管線中讀取和寫入數據
其中一個常見案例是在管線中讀取和寫入數據。 在 Azure Machine Learning 中,您會使用相同的架構來 讀取和寫入 所有類型的作業資料(管線作業、命令作業和掃掠作業)。 以下是針對常見案例在管線中使用數據的範例:
了解元件定義 YAML
以下是 componentA.yml 檔案,這是定義元件的 YAML 範例:
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
此數據表會定義元件 YAML 最常使用的欄位。 若要深入了解,請參閱完整元件 YAML 結構描述。
| 關鍵 | 描述 |
|---|---|
name |
必要。 元件的名稱。 它在整個 Azure Machine Learning 工作區中必須是唯一的。 它必須以小寫字母開頭。 允許小寫字母、數位和底線 (_) 。 長度上限是 255 個字元。 |
display_name |
Studio UI 中元件的顯示名稱。 它不需要在工作區內是唯一的。 |
command |
必要。 要執行的命令。 |
code |
上傳及用於元件的原始程式碼目錄的本機路徑。 |
environment |
必要。 用來執行元件的環境。 |
inputs |
元件輸入的字典。 鍵是在元件中輸入的名稱,值則表示元件輸入定義。 您可以使用 表示式來參考命令 ${{ inputs.<input_name> }} 中的輸入。 |
outputs |
元件輸出的辭典。 索引鍵是元件內容內輸出的名稱,而值是元件輸出定義。 您可以使用 表示式來參考命令 ${{ outputs.<output_name> }} 中的輸出。 |
is_deterministic |
如果元件輸入未變更,是否要重複使用先前作業的結果。 預設值是 true。 此設定也稱為 預設重複使用。 設定為 false 的常見案例是強制從雲端記憶體或 URL 重載數據。 |
在 3b_pipeline_with_data/componentA.yml的範例中,元件 A 有一個數據輸入和一個數據輸出,可以連接到父管線中的其他步驟。 提交管線作業時,元件 YAML 區 code 段中的所有檔案都會上傳至 Azure Machine Learning。 在此範例中,將會上傳底下的 ./componentA_src 檔案。 (componentA.yml的第16行)您可以在 Studio UI 中看到上傳的原始程式碼:在圖形中按兩下 componentA 步驟,然後前往 代碼 索引標籤,如下圖所示。 您可以看到這是一個 hello-world 腳本,用來進行一些簡單的打印,並將目前的日期和時間寫入 componentA_output 路徑。 元件會接受輸入,並透過命令行提供輸出。 它在hello.py中通過argparse進行處理。

輸入和輸出
輸入和輸出會定義元件的介面。 輸入和輸出可以是 string、number、integer或boolean類型的常值,或是包含輸入架構的物件。
物件輸入 (類型 uri_file為 、 uri_folder、 mltable、 mlflow_model或 custom_model)可以連接到父管線作業中的其他步驟,以將數據/模型傳遞至其他步驟。 在管線圖形中,物件類型輸入會轉譯為連接點。
常值輸入 (string、 、 numberintegerboolean、 ) 是您可以在執行時間傳遞至元件的參數。 您可以在 default 欄位中新增字面值輸入的預設值。 針對 number 和 integer 類型,您也可以使用 min 和 max 字段來新增最小值和最大值。 如果輸入值小於最小值或大於最大值,管線會在驗證時失敗。 驗證會在您提交管線作業之前發生,這可以節省時間。 驗證適用於 CLI、Python SDK 和設計工具 UI。 下列螢幕快照顯示設計工具 UI 中的驗證範例。 同樣地,您可以在欄位中定義允許的值 enum 。

如果您要將輸入新增至元件,您必須在三個位置進行編輯:
-
inputs元件 YAML 中的欄位。 -
command元件 YAML 中的欄位。 - 在元件原始碼中,用來處理命令行輸入。
上述螢幕快照中會以綠色方塊標示這些位置。
若要深入瞭解輸入和輸出,請參閱 管理元件和管線的輸入和輸出。
環境
環境是元件執行所在的環境。 它可以是 Azure Machine Learning 環境(精心策劃的或自定義註冊的)、Docker 映像或 conda 環境。 請參閱下列範例:
-
已註冊的 Azure Machine Learning 環境資產。 環境在元件中使用
azureml:<environment-name>:<environment-version>語法進行參考。 - 公用 Docker 映像。
- Conda 檔案。 conda 檔案必須與基底映像搭配使用。
註冊元件以重複使用和共用
雖然某些元件是特定管線特有的,但元件的實際優點來自於重複使用和共用。 您可以在 Machine Learning 工作區中註冊元件,使其可供重複使用。 已註冊的元件支援自動版本控制,因此您可以更新元件,但請確定需要較舊版本的管線將繼續運作。
在 azureml-examples 存放庫中,移至 cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components 目錄。
若要註冊元件,請使用 az ml component create 命令:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
執行這些命令以完成之後,您可以在 Studio 的 [資產>元件] 底下看到元件:

選取元件。 您會看到每個元件版本的詳細資訊。
[ 詳細數據] 索引標籤會顯示基本資訊,例如元件名稱、建立者,以及版本。 標籤和描述有可編輯的欄位。 您可以使用標籤來新增搜尋關鍵字。 描述欄位支援 Markdown 格式設定。 您應該使用它來描述元件的功能和基本用途。
在 [ 作業] 索引標籤上,您會看到所有使用元件之作業的歷程記錄。
在管線作業 YAML 檔案中使用已註冊元件
您現在會使用 1b_e2e_registered_components 作為如何在管線 YAML 中使用已註冊元件的範例。 移至 1b_e2e_registered_components 目錄並開啟 pipeline.yml 檔案。
inputs 和 outputs 欄位中的索引鍵和值與我們所討論過的索引鍵和值類似。 唯一顯著的差異在於 component 項目中 jobs.<job_name>.component 欄位的值。
component 的值格式為 azureml:<component_name>:<component_version>。 例如,定義 train-job 會指定應該使用最新版本的已註冊元件 my_train :
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
管理元件
您可以使用 CLI v2 來檢查元件詳細資料及管理元件。 使用 az ml component -h 取得元件命令的詳細指示。 下表列出所有可用的命令。 如需更多範例,請參閱 Azure CLI 參考。
| 指令 | 描述 |
|---|---|
az ml component create |
建立元件。 |
az ml component list |
列出工作區中的元件。 |
az ml component show |
顯示元件的詳細數據。 |
az ml component update |
更新元件。 只有少數欄位(描述、display_name)支援更新。 |
az ml component archive |
封存一個元件容器。 |
az ml component restore |
還原封存的元件。 |
後續步驟
- 試用 CLI v2 元件範例