APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
在 Azure Machine Learning 中,您可以使用自訂容器將模型部署至在線端點。 自定義容器部署可以使用 Azure Machine Learning 使用的預設 Python Flask 伺服器以外的網頁伺服器。
當您使用自訂部署時,您可以:
- 使用各種工具和技術,例如 TensorFlow 服務(TF 服務)、TorchServe、Triton 推斷伺服器、Plumber R 套件,以及 Azure Machine Learning 推斷最小映像。
- 仍會利用 Azure Machine Learning 所提供的內建監視、調整、警示和驗證。
本文說明如何使用 TF 服務影像來提供 TensorFlow 模型。
Prerequisites
Azure Machine Learning 工作區。 如需建立工作區的指示,請參閱 建立工作區。
Azure CLI 和
ml擴充功能或 Azure Machine Learning Python SDK v2:若要安裝 Azure CLI 和
ml擴充功能,請參閱 安裝和設定 CLI (v2) 。本文中的範例假設您使用 Bash Shell 或相容的 Shell。 例如,您可以在 Linux 系統上使用命令行界面,或使用 Windows 的 Linux 子系統。
包含工作區的 Azure 資源群組,且您或服務主體具有參與者存取權。 如果您使用 建立工作區 來設定工作區中的步驟,請符合此需求。
Docker Engine, installed and running locally. This prerequisite is highly recommended. 您需要它才能在本機部署模型,而且有助於偵錯。
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Azure CLI 腳本 | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | 藉由擴充 Azure Machine Learning 推斷最小映射,將多個模型部署到單一部署。 |
| minimal/single-model | deploy-custom-container-minimal-single-model | 藉由擴充 Azure Machine Learning 推斷最小映像來部署單一模型。 |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | 將兩個具有不同 Python 需求的 MLFlow 模型部署到單一端點後方的兩個不同的部署。 使用 Azure Machine Learning 推斷最小映射。 |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | 將三個回歸模型部署到一個端點。 使用 Plumber R 套件。 |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | 使用 TF 服務自定義容器來部署半加二模型。 使用標準模型註冊程式。 |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | 使用 TF 服務自定義容器與整合至映像的模型,來部署半加二模型。 |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | 使用 TorchServe 自定義容器部署單一模型。 |
| triton/single-model | deploy-custom-container-triton-single-model | 使用自定義容器部署 Triton 模型。 |
本文說明如何使用 tfserving/half-plus-two 範例。
Warning
Microsoft支援小組可能無法協助針對自定義映像所造成的問題進行疑難解答。 如果您遇到問題,系統可能會要求您使用預設影像或其中一個Microsoft提供的影像,以查看問題是否專屬於您的影像。
下載原始碼
The steps in this article use code samples from the azureml-examples repository. 使用下列命令來複製存放庫:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
初始化環境變數
若要使用 TensorFlow 模型,您需要數個環境變數。 執行下列命令來定義這些變數:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
下載 TensorFlow 模型
下載並解壓縮模型,將輸入值除以兩個,並將兩個新增至結果:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
在本機測試 TF Serving 映像檔
使用 Docker 在本機執行映射以進行測試:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
將即時性和評分要求傳送至影像
傳送活動性請求,以檢查容器內的程序是否正在運行。 您應該會收到 200 OK 的響應狀態代碼。
curl -v http://localhost:8501/v1/models/$MODEL_NAME
傳送評分要求來檢查您是否可以取得未標記數據的預測:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
停止映像
當您在本機完成測試時,請停止映像:
docker stop tfserving-test
將線上端點部署至 Azure
若要將在線端點部署至 Azure,請執行下列各節中的步驟。
為您的端點和部署建立 YAML 檔案
您可以使用 YAML 來設定雲端部署。 例如,若要設定端點,您可以建立名為 tfserving-endpoint.yml 的 YAML 檔案,其中包含下列幾行:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
若要設定部署,您可以建立名為 tfserving-deployment.yml 的 YAML 檔案,其中包含下列幾行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
下列各節將討論 YAML 和 Python 參數的重要概念。
Base image
在 YAML 的 environment 區段中,或 Python 的 Environment 建構函式中,您會將基底映像作為參數指定。 這個範例會使用 docker.io/tensorflow/serving:latest 作為 image 值。
如果您檢查容器,您可以看到此伺服器使用 ENTRYPOINT 命令來啟動進入點腳本。 該腳本會採用環境變數,例如MODEL_BASE_PATH和MODEL_NAME,並公開埠,例如8501。 這些詳細數據全都與這部伺服器有關,您可以使用這項資訊來判斷如何定義您的部署。 例如,如果您在部署定義中設定 MODEL_BASE_PATH 和 MODEL_NAME 環境變數,TF 服務會使用這些值來起始伺服器。 同樣地,如果您在部署定義中將每個路由 8501 的埠設定為 ,則對這些路由的使用者要求會正確地路由至 TF 服務伺服器。
此範例是以 TF 服務案例為基礎。 但是,您可以使用任何保持運作並可響應存活性、準備就緒和評分路由要求的容器。 若要查看如何形成 Dockerfile 來建立容器,您可以參考其他範例。 某些伺服器會使用 CMD 指示,而不是使用 ENTRYPOINT 指示。
inference_config 的參數
在 environment 區段或 類別中 Environment , inference_config 是參數。 它會指定三種路由類型的埠和路徑:存活路由、準備路由和成績計算路由。
inference_config 參數是必需的,如果您想要使用受控的在線端點來執行自己的容器。
就緒路由與運行路由
某些 API 伺服器提供檢查伺服器狀態的方式。 您可以指定兩種類型的路由來檢查狀態:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
在機器學習推斷的內容中,伺服器可能會在載入模型之前,以 200 OK 的狀態代碼回應即時性要求。 只有在將模型載入記憶體之後,伺服器才會以 200 OK 的狀態代碼回應整備要求。
如需存活性、就緒性和啟動探查的詳細資訊,請參閱 設定 Liveness、Readiness 和 Startup Probes。
您選擇的 API 伺服器會決定即時性和整備路由。 您在本機測試容器時,會在先前的步驟中識別該伺服器。 在本文中,範例部署會針對即時和整備路由使用相同的路徑,因為 TF 服務只會定義即時性路由。 如需定義路由的其他方式,請參閱其他範例。
Scoring routes
您使用的 API 伺服器提供接收要處理之承載的方法。 在機器學習推斷的內容中,伺服器會透過特定路由接收輸入數據。 當您在先前步驟中於本機測試容器時,確認 API 伺服器的路由。 當您定義要建立的部署時,請將該路由指定為評分路由。
成功建立部署後,也會更新端點的scoring_uri 參數。 您可以執行下列命令來驗證此事實: az ml online-endpoint show -n <endpoint-name> --query scoring_uri。
找出掛接的模型
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. 掛接模型時,您可以部署新版本的模型,而不需要建立新的 Docker 映像。 By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
例如,請考慮下列設定:
- 在本機計算機上的目錄結構是 /azureml-examples/cli/endpoints/online/custom-container
- 的模型名稱
half_plus_two
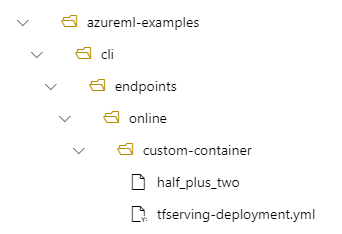
假設您的tfserving-deployment.yml檔案在其 model 區段中包含下列幾行。 在本節中 name ,值會參考您用來在 Azure Machine Learning 中註冊模型的名稱。
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
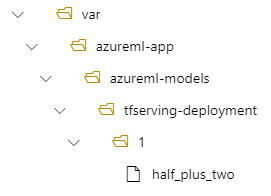
在此情況下,當您建立部署時,您的模型位於下列資料夾之下:/var/azureml-app/azureml-models/tfserving-mounted/1。
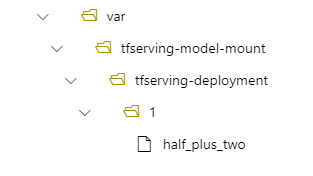
您可以選擇性地設定您的 model_mount_path 值。 藉由調整此設定,您可以變更掛接模型的路徑。
Important
此值 model_mount_path 必須是Linux中有效的絕對路徑(在容器映像的客體OS中)。
Important
model_mount_path 只能在 BYOC(攜帶您自己的容器)案例中使用。 在 BYOC 案例中,在線部署所使用的環境必須已設定 inference_config 參數 。 您可以使用 Azure ML CLI 或 Python SDK 在建立環境時指定 inference_config 參數。 Studio UI 目前不支援指定此參數。
當您變更 的值 model_mount_path時,您也需要更新 MODEL_BASE_PATH 環境變數。 設定 MODEL_BASE_PATH 為 與 相同的值 model_mount_path ,以避免因為找不到基底路徑的錯誤而造成部署失敗。
例如,您可以將 model_mount_path 參數新增至 tfserving-deployment.yml 檔案。 您也可以更新 MODEL_BASE_PATH 該檔案中的值:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
在您的部署中,您的模型會位於 /var/tfserving-model-mount/tfserving-mounted/1。 它不再位於 azureml-app/azureml-models 目錄下,而是位於您指定的掛載路徑下。
建立端點和部署
建構 YAML 檔案之後,請使用下列命令來建立端點:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
使用下列命令來建立您的部署。 此步驟可能會執行幾分鐘。
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
叫用端點
當您的部署完成時,請對已部署的端點提出評分要求。
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
刪除端點
如果您不再需要端點,請執行下列命令來刪除它:
az ml online-endpoint delete --name tfserving-endpoint