使用 Azure Machine Learning 搭配 Fairlearn 開放原始碼套件以評估 ML 模型的公平性 (預覽)

在本操作指南中,您將瞭解如何使用 Fairlearn 的開放原始碼 Python 套件搭配 Azure Machine Learning 來執行下列工作:
- 評估模型預測的公平性。 若要深入瞭解機器學習服務的公平性,請參閱機器學習文章中的公平性。
- 從 Azure Machine Learning 工作室列出和下載公平性評量見解,或將見解上傳至工作室。
- 請參閱 Azure Machine Learning 工作室中的公平評量儀表板,與您模型的公平性見解進行互動。
注意
公平性評估並非純粹的技術練習。 此套件可協助您評估機器學習模型的公平性,但只有您可以設定和決定模型的執行方式。 雖然此套件有助於透過量化計量來評估公平性,但機器學習模型的開發人員也必須執行質化分析以評估自身模型的公平性。
重要
此功能目前處於公開預覽。 此預覽版本沒有服務等級協定,不建議用於處理生產工作負載。 可能不支援特定功能,或可能已經限制功能。
如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
Azure Machine Learning 公平性 SDK
Azure Machine Learning 公平性 SDK (azureml-contrib-fairness) 會在 Azure Machine Learning 中整合開放原始碼 Python 套件 Fairlearn。 若要深入瞭解 Azure Machine Learning 內的 Fairlearn 整合,請參閱這些範例筆記本。 如需 Fairlearn 的詳細資訊,請參閱範例指南和範例筆記本。
使用下列命令來安裝 azureml-contrib-fairness 和 fairlearn 套件:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
較新版本的 Fairlearn 應該也能在下列範例程式碼中運作。
上傳單一模型的公平性見解
下列範例會示範如何使用公平性套件。 我們會將模型公平性見解上傳至 Azure Machine Learning,並查看 Azure Machine Learning 工作室中的公平性評量儀表板。
在 Jupyter Notebook 中訓練範例模型。
在資料集方面,我們會使用廣為人知的成人人口普查資料集,這是我們從 OpenML 提取的資料集。 我們假設有一個貸款決策問題,而標籤指出某個人是否償還了先前的貸款。 我們會訓練模型以預測先前未見過的個人是否會償還貸款。 這類模型可能用於評估貸款決策。
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})登入 Azure Machine Learning 並註冊您的模型。
公平性儀表板可以整合已註冊或未註冊的模型。 透過下列步驟,在 Azure Machine Learning 中註冊您的模型:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)預先計算公平性計量。
使用 Fairlearn 的
metrics套件建立儀表板字典。_create_group_metric_set方法的引數類似於儀表板的函式,差異在於敏感性特徵會以字典的形式傳遞 (以確保名稱可用)。 在呼叫這個方法時,我們也必須指定預測的類型 (此處為二元分類)。# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')上傳預先計算的公平性計量。
現在,匯入
azureml.contrib.fairness套件以執行上傳:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_id建立實驗,然後執行並上傳儀表板:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()檢查 Azure Machine Learning 工作室中的公平性儀表板
如果您完成上述步驟 (將產生的公平性見解上傳至 Azure Machine Learning),您可以在 Azure Machine Learning 工作室中查看公平性儀表板。 此儀表板與 Fairlearn 中提供的視覺化儀表板相同,可讓您分析敏感性特徵子群組 (例如男性與女性) 之間的差異。 透過下列其中一個路徑存取 Azure Machine Learning 工作室中的視覺化儀表板:
- 作業窗格 (預覽)
- 在左窗格中選取 [作業],以查看您在 Azure Machine Learning 上執行的實驗清單。
- 選取特定實驗,即可檢視該實驗中的所有執行。
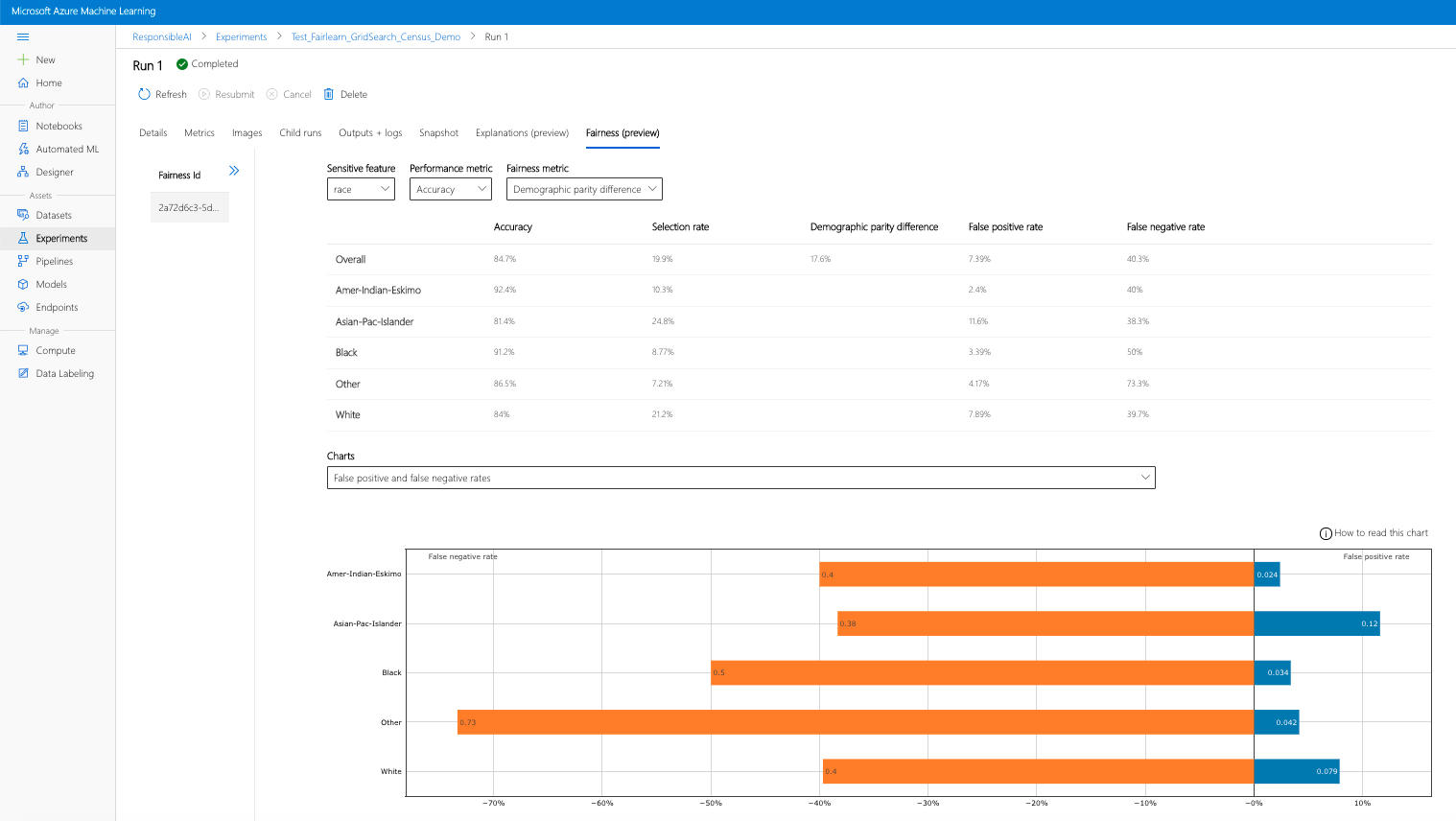
- 選取某次執行,然後選取 [公平性] 索引標籤,以檢視說明視覺化儀表板。
- 到達 [公平性] 索引標籤後,按一下右側功能表的公平性 ID。
- 在公平性評估頁面上,選取感興趣的敏感性屬性、效能計量和公平性計量以設定您的儀表板。
- 切換不同的圖表類型,以觀察配置損害和服務品質損害。

- 模型窗格
- 如果您遵循先前的步驟註冊原始模型,則可以在左窗格中選取 [模型] 來加以查看。
- 選取模型,然後選取 [公平性] 索引標籤,以檢視說明視覺化儀表板。
若要深入瞭解視覺化儀表板以及其中的內容,請參閱 Fairlearn 的使用者指南。


上傳多個模型的公平性見解
若要比較多個模型,並查看其公平性評量有何不同,您可以將多個模型傳送至視覺效果儀表板,並比較其效能與公平性的取捨。
訓練您的模型:
我們現在會根據支援向量機器估算器建立第二個分類器,並使用 Fairlearn 的
metrics套件上傳公平性儀表板字典。 我們假設先前訓練的模型仍可供使用。# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)註冊您的模型
接下來,在 Azure Machine Learning 中註冊兩個模型。 為了方便起見,請將結果儲存在字典中,這會將已註冊模型的
id(name:version格式的字串) 對應至預測項本身:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictor在本機載入公平性儀表板
將公平性見解上傳至 Azure Machine Learning 之前,您可以在本機叫用的公平性儀表板中檢查這些預測。
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)預先計算公平性計量。
使用 Fairlearn 的
metrics套件建立儀表板字典。sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')上傳預先計算的公平性計量。
現在,匯入
azureml.contrib.fairness套件以執行上傳:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_id建立實驗,然後執行並上傳儀表板:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()與上一節類似,您可以在 Azure Machine Learning 工作室中透過上述的其中一個路徑 (實驗或模型) 來存取視覺化儀表板,並根據公平性和效能來比較這兩個模型。
上傳未改善和已改善的公平性見解
您可以使用 Fairlearn 的緩解演算法,將產生的緩和模型與原始未緩解的模型進行比較,並在比較的模型之間瀏覽效能/公平性取捨。
若要查看示範如何使用方格搜尋緩和演算法的範例 (使用不同的公平性和效能取捨來建立緩和模型的集合),請參閱此範例筆記本。
在一次執行中上傳多個模型的公平性見解,可以比較模型的公平性和效能。 您可以按一下模型比較圖中顯示的任何模型,以查看特定模型的詳細公平性見解。

下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應