追蹤是儲存實驗相關資訊的流程。 在本文中,您將了解如何在 Azure Machine Learning 工作區中使用 MLflow 來追蹤實驗與執行。
當您使用 Azure Machine Learning 時,MLflow API 中可用的某些方法可能無法使用。 如需支援和不支援作業的詳細資訊,請參閱查詢執行和實驗的支援矩陣。 您也可以從 MLflow 和 Azure Machine Learning 一文中瞭解 Azure Machine Learning 中支援的 MLflow 功能。
附註
- 若要追蹤在 Azure Databricks 上執行的實驗,請參閱 使用 MLflow 和 Azure Machine Learning 追蹤 Azure Databricks 機器學習實驗。
- 若要追蹤在 Azure Synapse Analytics 上執行的實驗,請參閱使用 MLflow 和 Azure Machine Learning 追蹤 Azure Synapse Analytics ML 實驗 (部分機器翻譯)。
先決條件
擁有 Azure 訂用帳戶和 免費或付費版本的 Azure Machine Learning。
若要執行 Azure CLI 和 Python 命令,請安裝 Azure CLI v2 和適用於 Python 的 Azure Machine Learning SDK v2。 Azure CLI 的
ml延伸模組會在您第一次執行 Azure Machine Learning CLI 命令時自動安裝。
安裝 MLflow SDK
mlflow套件和適用於 MLflow 的 Azure Machine Learningazureml-mlflow外掛程式:pip install mlflow azureml-mlflow秘訣
您可使用
mlflow-skinny套件,這是輕量型 MLflow 套件,沒有 SQL 儲存體、伺服器、UI 或資料科學相依性。 我們建議主要需要 MLflow 追蹤和記錄功能,但不需要完整功能套件的使用者使用此套件,包括部署。建立 Azure Machine Learning 工作區。 若要建立工作區,請參閱建立開始使用所需的資源。 檢閱您在工作區中執行 MLflow 作業所需的 存取權限 。
若要執行遠端追蹤,或追蹤在 Azure Machine Learning 外部執行的實驗,請將 MLflow 設定為指向 Azure Machine Learning 工作區的追蹤 URI。 如需如何將 MLflow 連線至工作區的詳細資訊,請參閱設定適用於 Azure Machine Learning 的 MLflow。
設定實驗
MLflow 會在實驗和執行中組織資訊。 執行 (run) 在 Azure Machine Learning 中稱為作業 (job)。 根據預設,執行會記錄到一個名為 Default 的自動建立實驗,但您可以設定要追蹤的實驗。
如需互動式定型,例如在 Jupyter 筆記本中,請使用 MLflow 命令 mlflow.set_experiment()。 例如,下列程式碼片段會設定實驗:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
設定執行
Azure Machine Learning 會在 MLflow 所稱的執行中追蹤訓練作業。 使用執行來擷取作業執行的所有處理。
當您以互動方式工作時,一旦您記錄了需要作用中執行的資訊,MLflow 就會立即開始追蹤您的訓練常式。 例如,如果已啟用 MLflow 的自動記錄功能,則當您記錄計量或參數或啟動定型週期時,MLflow 追蹤就會開始。
不過,通常明確地啟動執行會很有幫助,特別是當您想在 [持續時間] 欄位中記錄您的實驗的總時間時。 若要明確啟動執行,請使用 mlflow.start_run()。
無論您是否手動啟動執行,您最終都需要停止執行,讓 MLflow 知道您的實驗執行已完成,而且可以將執行的狀態標示為 [已完成]。 若要停止執行,請使用 mlflow.end_run()。
以下程式碼能以手動的方式來啟動執行,並在筆記本結尾結束它:
mlflow.start_run()
# Your code
mlflow.end_run()
最好以手動的方式來啟動執行,以免忘記結束它們。 您可以使用內容管理員範式來協助您記得結束執行。
with mlflow.start_run() as run:
# Your code
當您使用 mlflow.start_run()啟動新的執行時,指定 run_name 參數會很有用,稍後會轉譯為 Azure Machine Learning 使用者介面中的執行名稱。 這種做法有助於您更快地識別執行。
with mlflow.start_run(run_name="hello-world-example") as run:
# Your code
啟用 MLflow 自動記錄
您可以手動使用 MLflow 記錄計量、參數和檔案,也可以依賴 MLflow 的自動記錄功能。 MLflow 支援的每個機器學習架構都會決定要自動追蹤的內容。
若要啟用自動記錄功能,請在您的定型程式碼前面插入下列程式碼:
mlflow.autolog()
在您的工作區中檢視計量和成品
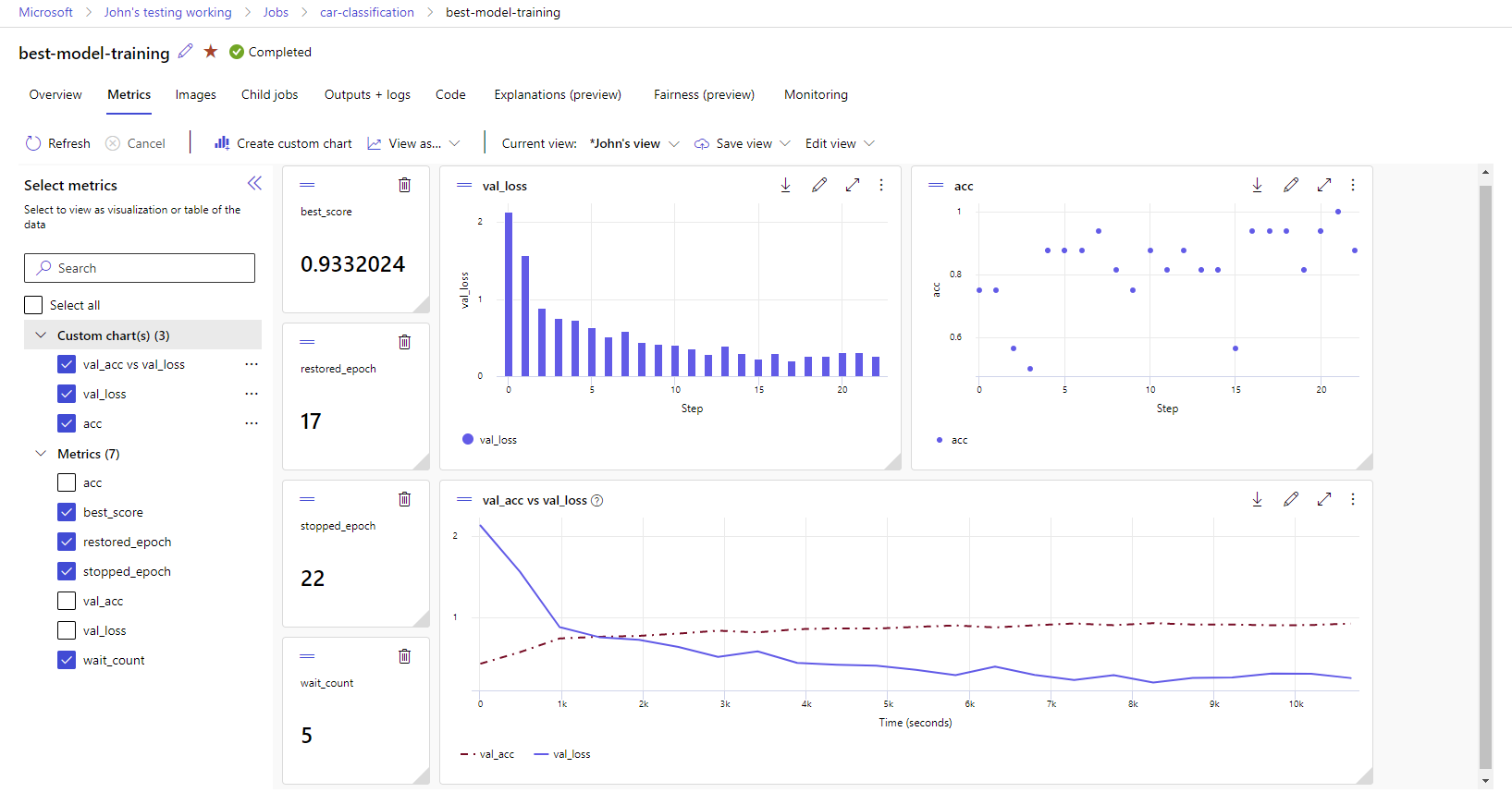
您的工作區中會追蹤 MLflow 記錄中的計量和成品。 您可以在 Azure Machine Learning 工作室中檢視和存取它們,或使用 MLflow SDK 以程式設計方式存取它們。
若要在工作室中檢視計量和成品:
在您的工作區的 [作業] 頁面上,選取實驗名稱。
在實驗詳細資料頁面上,選取 [計量] 索引標籤。
選取記錄的度量以在頁面右側顯示圖表。 您可以藉由套用平滑、變更色彩或繪製單一圖表上的多個計量來自訂圖表。 您也可以調整大小並重新排列配置。
建立您想要的檢視之後,請儲存它以供將來使用,並使用直接連結與您的團隊成員共用。

若要使用 MLflow SDK 以程式設計方式存取或查詢計量、參數和成品,請使用 mlflow.get_run()。
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
秘訣
前面的範例只會傳回指定計量的最後一個值。 若要擷取指定計量的所有值,請使用 mlflow.get_metric_history 方法。 如需擷取計量值的詳細資訊,請參閱從執行中取得參數和計量。
若要下載您所記錄的成品 (例如檔案和模型),請使用 mlflow.artifacts.download_artifacts()。
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
如需如何使用 MLflow 從 Azure Machine Learning 中的實驗和執行擷取或比較資訊的詳細資訊,請參閱 使用 MLflow 查詢和比較實驗和執行。