疑難排解指引
此文章說明關於提示流程使用方式的常見問題。
流程製作相關問題
當您更新程式碼優先體驗的流程時,會發生「找不到封裝工具」錯誤
當您更新程式碼優先體驗的流程時,如果流程使用 Faiss 索引查閱、向量索引查閱、向量資料庫查閱或內容安全性 (文字) 工具,您可能會遇到下列錯誤訊息:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
若要解決問題,您有兩個選擇:
選項 1
將您的計算工作階段更新為最新的基礎映像版本。
選取 [原始檔案模式] 以切換至原始程式碼檢視。 然後開啟 flow.dag.yaml 檔案。

更新工具名稱。
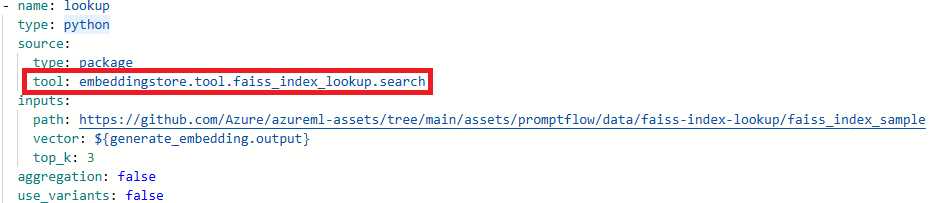
工具 新工具名稱 Faiss 索引查閱 promptflow_vectordb.tool.faiss_index_lookup.FaissIndexLookup.search 向量索引查閱 promptflow_vectordb.tool.vector_index_lookup.VectorIndexLookup.search 向量資料庫查閱 promptflow_vectordb.tool.vector_db_lookup.VectorDBLookup.search 內容安全 (文字) content_safety_text.tools.content_safety_text_tool.analyze_text 儲存 flow.dag.yaml 檔案。
選項 2
- 將您的計算工作階段更新為最新的基礎映像版本
- 移除舊的工具,然後重新建立新的工具。
「沒有這類檔案或目錄」錯誤
提示流程依靠檔案共享儲存體來儲存流程的快照集。 如果檔案共用儲存體發生問題,您可能會遇到下列問題。 以下是您可以嘗試的一些因應措施:
如果您使用私人儲存體帳戶,請參閱提示流程中的網路隔離,以確定您的工作區可以存取儲存體帳戶。
如果儲存體帳戶已啟用公用存取,請檢查工作區中是否有名為
workspaceworkingdirectory的資料存放區。 該存放區應為檔案共享類型。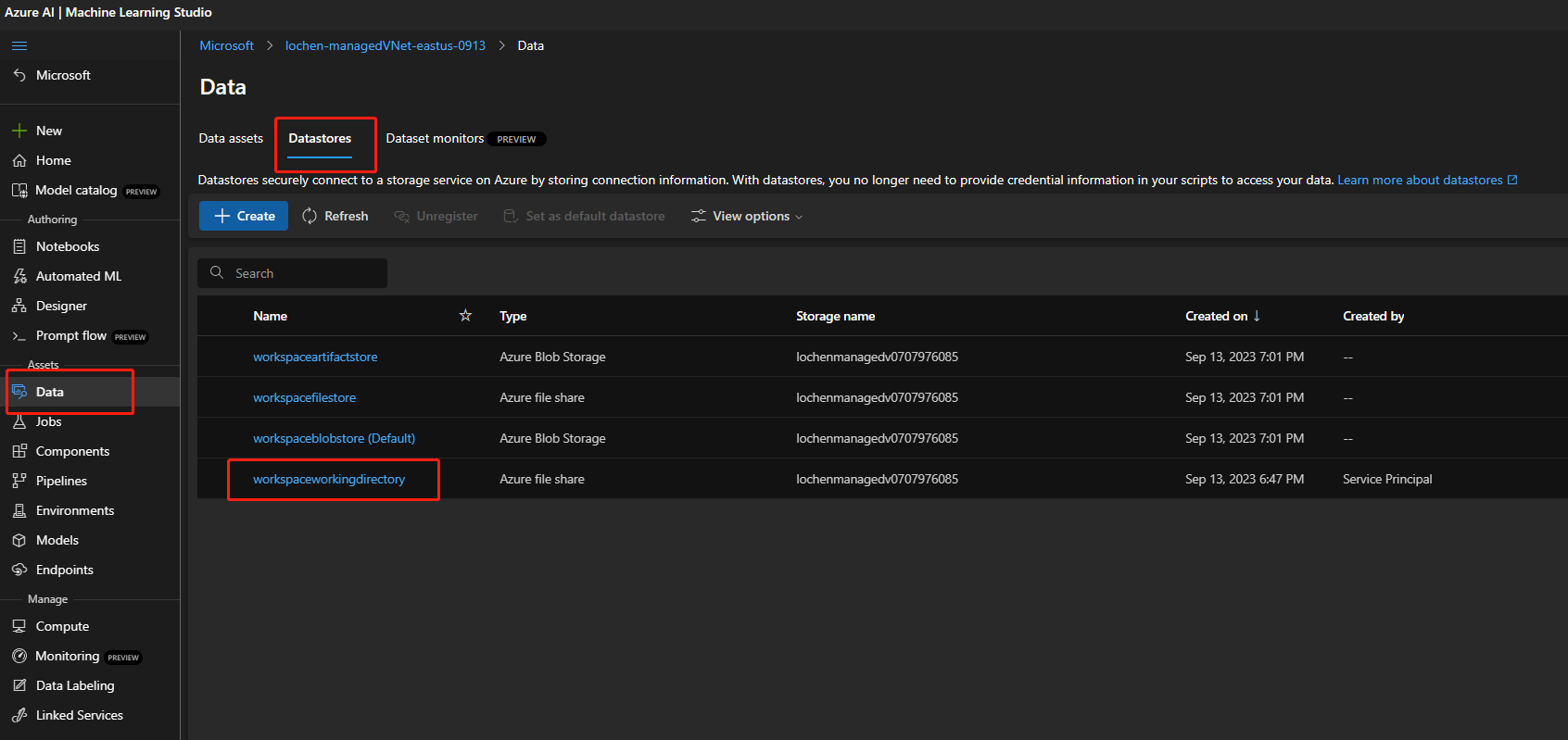

流程遺失

此問題的可能原因有幾個:
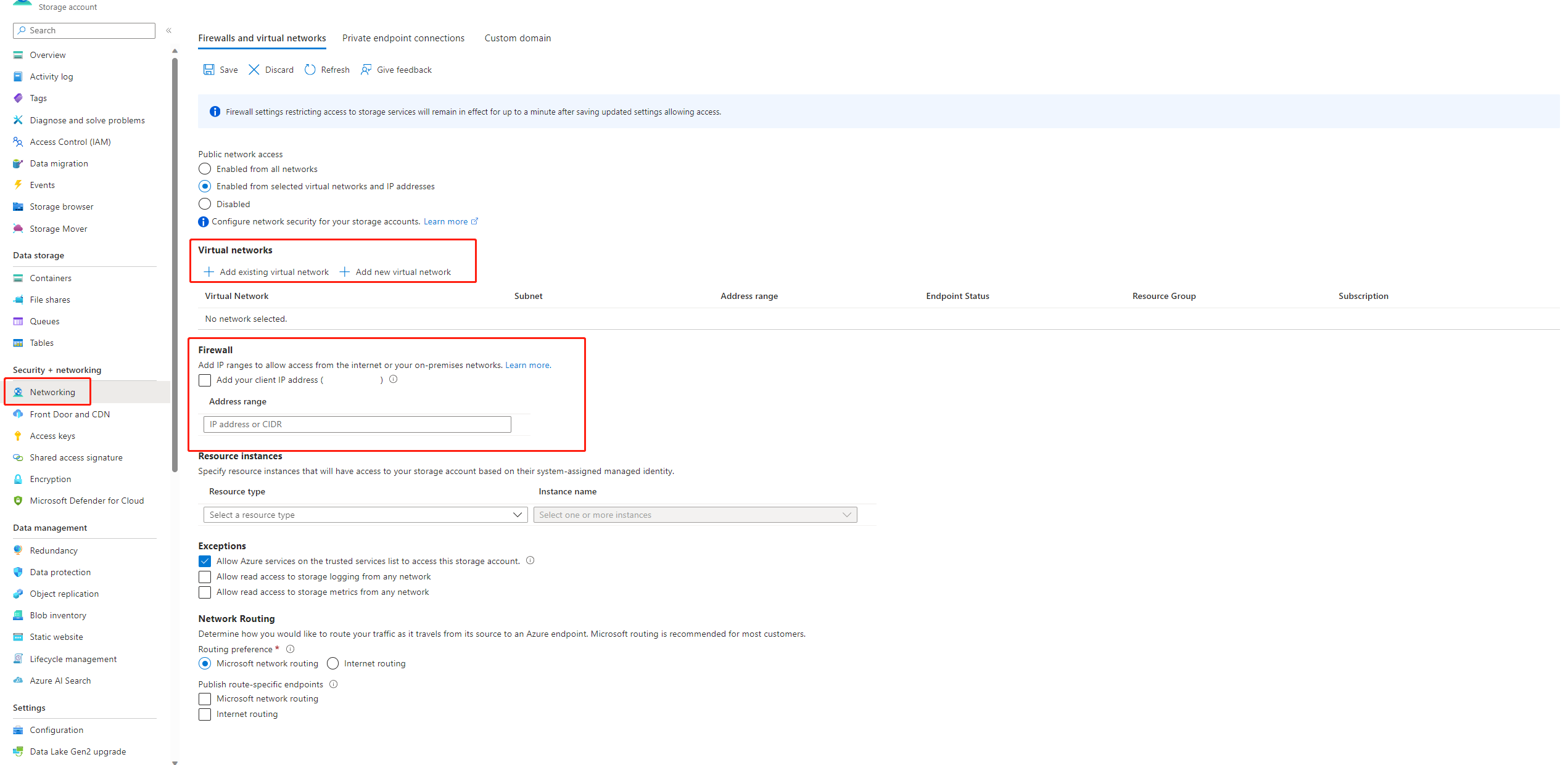
如果儲存體帳戶的公用存取權已停用,您必須將 IP 新增至儲存體防火牆以確保存取權,或透過已有私人端點連線至儲存體帳戶的虛擬網路啟用存取。
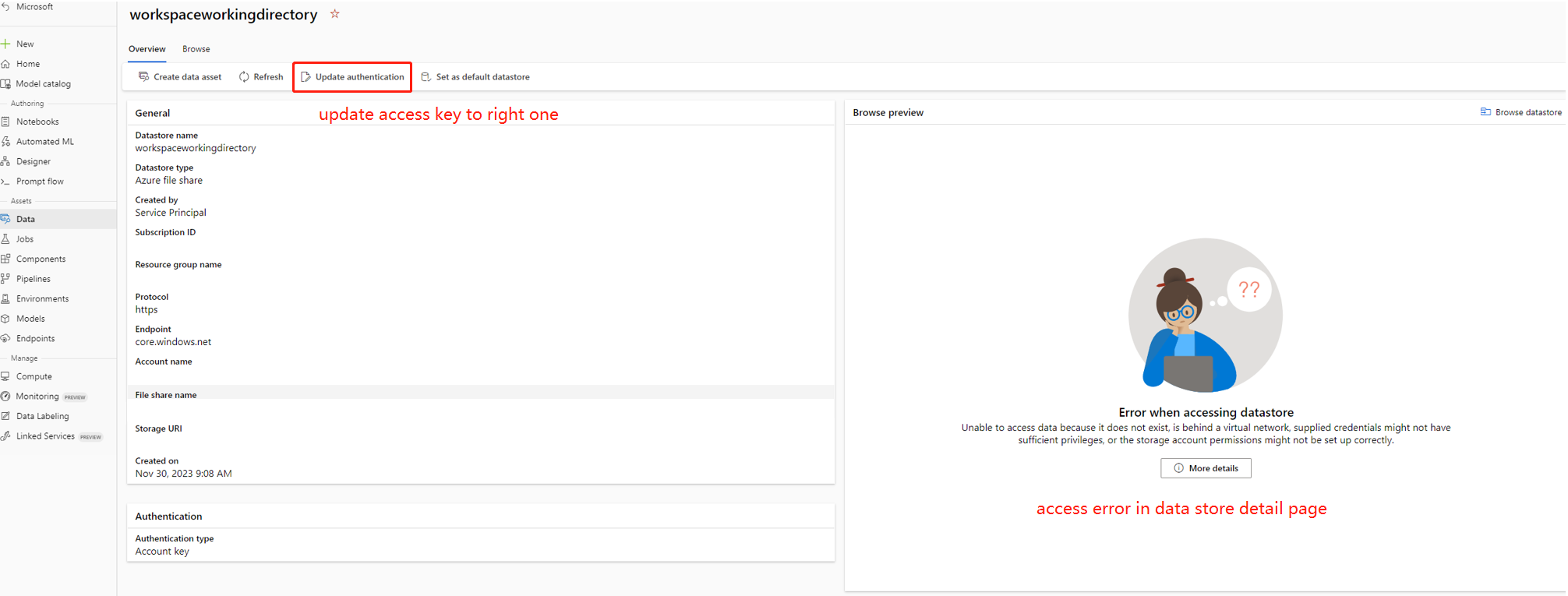
在某些情況下,數據存放區中的帳戶密鑰與記憶體帳戶不同步,您可以嘗試更新數據存放區詳細數據頁面中的帳戶金鑰,以修正此問題。
如果您使用 AI Studio,儲存體帳戶必須設定 CORS 以允許 AI Studio 存取儲存體帳戶,否則您會看到流程遺失問題。 您可以將下列 CORS 設定新增至儲存體帳戶以修正此問題。
- 移至儲存體帳戶頁面,選取
settings下方的Resource sharing (CORS),然後選取索引標籤File service。 - 允許的原始來源:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - 允許的方法:
DELETE, GET, HEAD, POST, OPTIONS, PUT
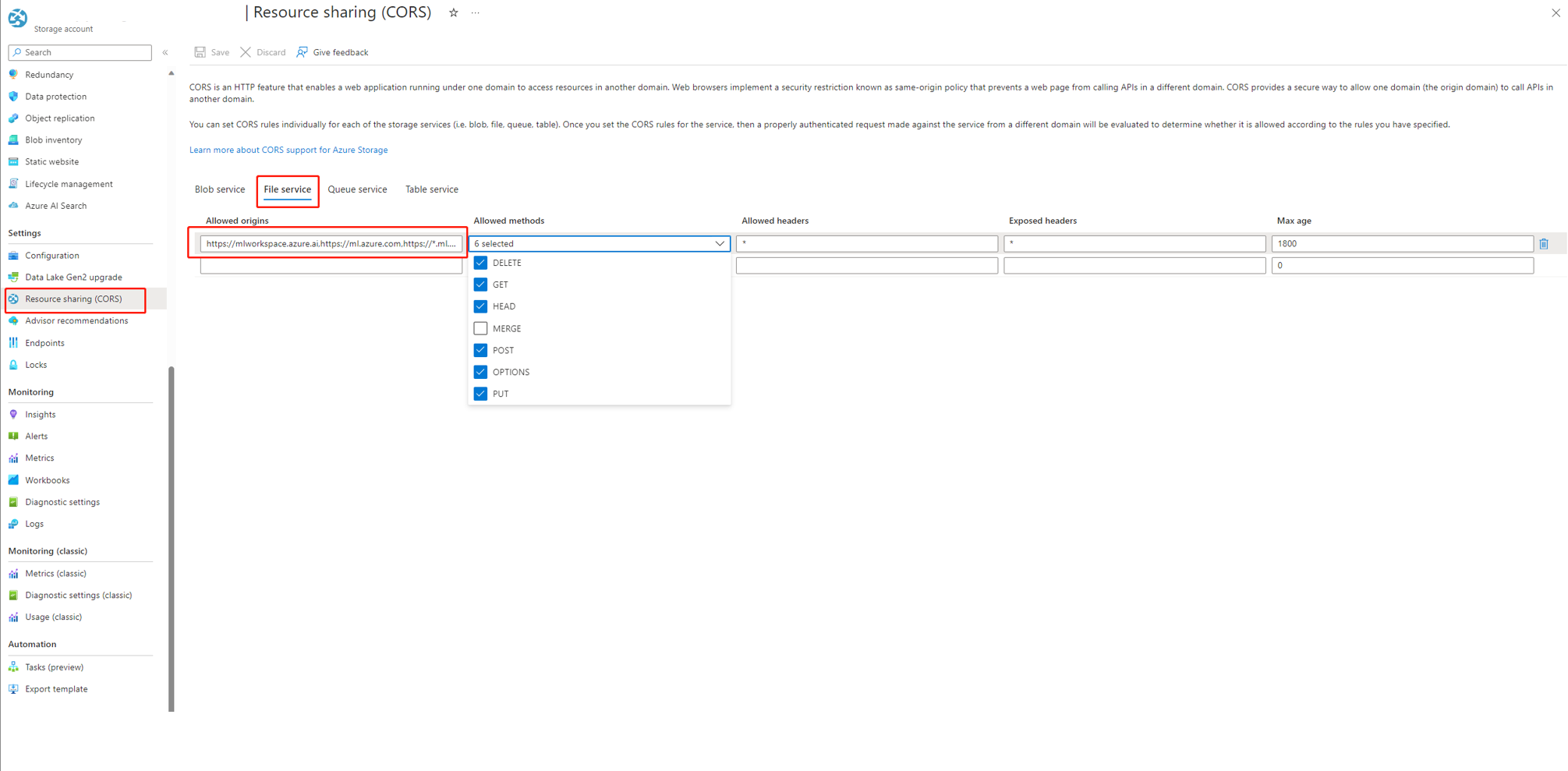
- 移至儲存體帳戶頁面,選取



計算工作階段相關問題
執行失敗,因為「沒有名為 XXX 的模組」
這類錯誤與計算工作階段缺少必要的套件有關。 如果您使用預設環境,請確定計算工作階段使用的映像為最新版本。 如果您使用自訂基礎映像,請務必在 Docker 內容中安裝所有必要的套件。 如需詳細資訊,請參閱自訂計算工作階段的基礎映像。
如何查看計算工作階段所使用的無伺服器執行個體?
您可以在計算頁面下的計算工作階段清單索引標籤中,檢視計算工作階段所使用的無伺服器執行個體。 深入了解如何管理無伺服器執行個體。
計算工作階段使用自訂基礎映像失敗
計算工作階段使用 requirements.txt 或自訂基礎映像開始失敗
計算工作階段支援在 flow.dag.yaml 中使用 requirements.txt 或自訂基礎映像來自訂映射。 建議您在多數情況下使用 requirements.txt,該檔案會使用 pip install -r requirements.txt 安裝套件。 如果您有 Python 套件以外相依項目,必須遵循自訂基礎映像指示以在提示流程基底映射之上建立新的映像基底。 接著請在 flow.dag.yaml 中使用該映像基底。 深入了解如何在計算工作階段中指定基礎映像。
- 您無法使用任意基底映像來建立計算會話,您必須使用提示流程提供的基底映像。
- 請勿在
requirements.txt中釘選promptflow和promptflow-tools的版本,因為我們已將其包含在基礎映像中。 使用舊版promptflow和promptflow-tools可能會導致非預期的行為。
流程執行相關問題
如何在 LLM 工具中尋找原始輸入和輸出,以進行進一步調查?
在提示流程中,從成功執行和執行詳細資料頁面的流程頁面上,您可以在輸出區段中找到 LLM 工具的原始輸入和輸出。 選取 view full output 按鈕以檢視完整輸出。

Trace 區段包含 LLM 工具的每個要求和回應。 您可以檢查傳送至 LLM 模型的原始訊息,以及 LLM 模型的原始回應。

如何修正 Azure OpenAI 的 409 錯誤?
如果遇到 Azure OpenAI 的 409 錯誤,這表示您已達到 Azure OpenAI 的速率上限。 您可以在 LLM 節點的輸出區段中檢查錯誤訊息。 深入了解 Azure OpenAI 速率限制。

識別哪一個節點耗用最多時間
檢查計算工作階段記錄。
試著尋找下列警告記錄格式:
{node_name} 已執行 {duration} 秒。
例如:
案例 1:Python 指令碼節點執行過久。

在此情況下,您會發現
PythonScriptNode的執行時間很長 (將近 300 秒)。 接著,您可以檢查節點詳細資料以找出問題所在。案例 2:LLM 節點執行過久。
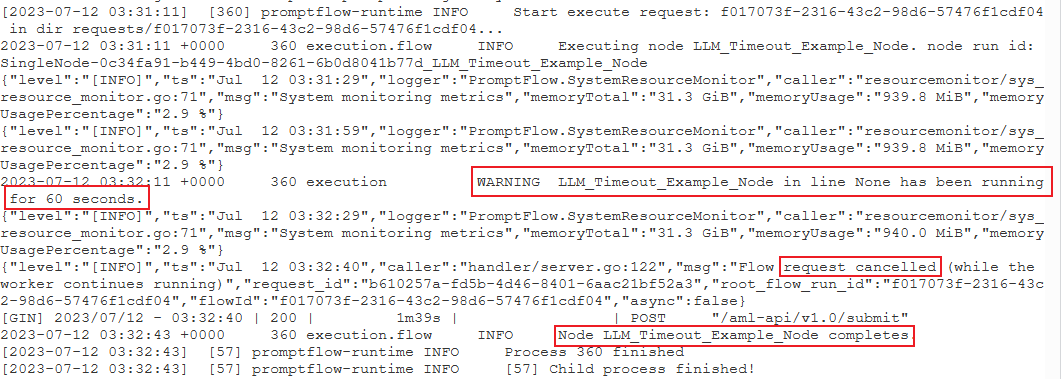
在此情況下,如果您在記錄中看到訊息
request canceled,可能是因為 OpenAI API 呼叫花費的時間太長,且超過逾時限制。OpenAI API 逾時可能是因為網路問題,或需要更多處理時間的複雜要求所造成。 如需詳細資訊,請參閱 OpenAI API 逾時。
請等候幾秒鐘,然後重試您的要求。 此動作通常可解決任何網路問題。
如果重試沒有效果,請檢查您是否使用長內容模型 (例如
gpt-4-32k),且將max_tokens設定為較大的值。 若是如此,則該行為是正常情況,因為您的提示可能會產生較長的回應,導致時間超出互動式模式的上限。 在此情況下,建議您嘗試採用Bulk test,因為此模式沒有逾時設定。
如果您在記錄中找不到任何項目,表示這是特定節點的問題:
- 請連絡提示流程小組 (promptflow-eng) 並提供記錄。 我們會嘗試識別根本原因。


流程部署的相關問題
缺少執行「Microsoft.MachineLearningService/workspaces/datastores/read」動作的授權
如果您的流程包含索引查閱工具,在部署流程之後,端點必須存取工作區資料存放區才能讀取 MLIndex yaml 檔案,或是包含區塊和內嵌的 FAISS 資料夾。 因此,您必須手動授與端點身分識別執行此動作的權限。
您可以為端點身分識別授與工作區範圍的 AzureML 資料科學家,或包含「MachineLearningService/workspace/datastore/reader」動作的自訂角色。
取用端點時的上游要求逾時問題
如果您使用 CLI 或 SDK 來部署流程,可能會遇到逾時錯誤。 根據預設,request_timeout_ms 是 5000。 您可以指定最多 5 分鐘,也就是 300,000 毫秒。 下列範例示範如何在部署 yaml 檔案中指定要求逾時。 若要深入了解,請參閱部署結構描述。
request_settings:
request_timeout_ms: 300000
OpenAI API 叫用驗證錯誤
如果您重新產生 Azure OpenAI 金鑰並手動更新提示流程中使用的連線,若在金鑰重新產生之前叫用建立的現有端點時,可能會遇到這類錯誤: 「未經授權。存取權杖遺失、無效、受眾不正確或已過期。」
這是因為端點/部署中使用的連線不會自動更新。 部署中金鑰或秘密的任何變更都應該透過手動更新來完成,目的是避免因為意外的離線作業而影響線上生產部署。
- 如果端點部署在 Studio UI 中,您可以直接使用相同的部署名稱,將流程重新部署到現有的端點。
- 如果使用 SDK 或 CLI 部署端點,您必須對部署定義進行一些修改,例如新增虛擬環境變數,然後使用
az ml online-deployment update來更新您的部署。
提示流程部署中的弱點問題
針對提示流程執行階段的相關弱點,以下是可協助緩解的方法:
- 更新流程資料夾中 requirements.txt 的相依性套件。
- 如果您的流程採用自訂基礎映射,則必須將提示流程執行階段更新為最新版本,並重建您的基礎映射,然後重新部署流程。
針對受控線上部署的任何其他弱點,Azure Machine Learning 會每月修正問題。
「MissingDriverProgram 錯誤」或「在要求中找不到驅動程式」
如果您在部署流程時遇到下列錯誤,則可能與部署環境相關。
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
修正此問題的方式有兩種。
(建議使用) 您可以在自訂環境詳細資料頁面中找到容器映像 URI,並將其設定為 flow.dag.yaml 檔案中的流程基礎映像。 在 UI 中部署流程時,只要選取 [使用目前流程定義的環境],後端服務就會根據此基礎映像和
requirement.txt建立自訂環境以進行部署。 深入了解流程定義中指定的環境。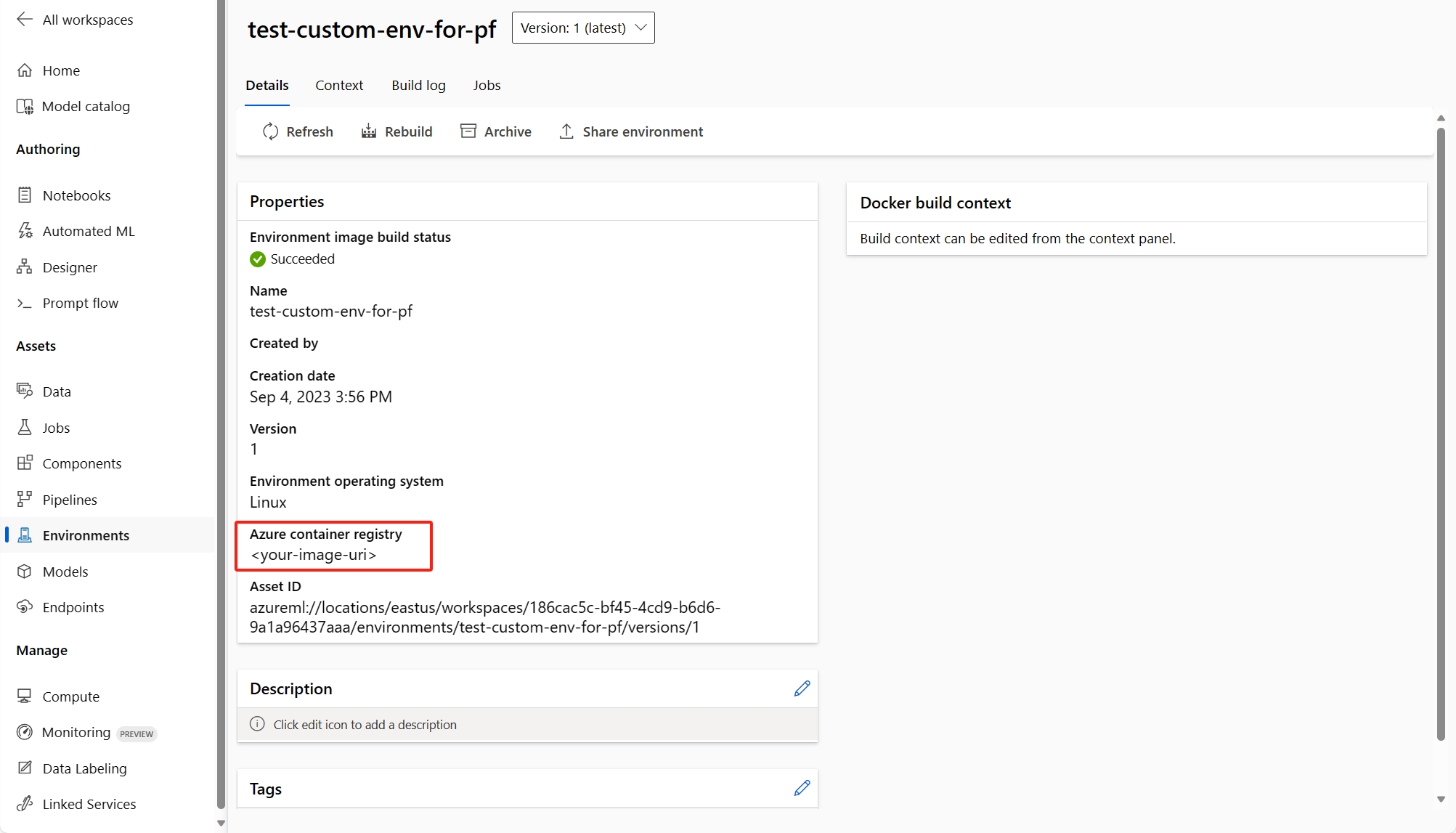
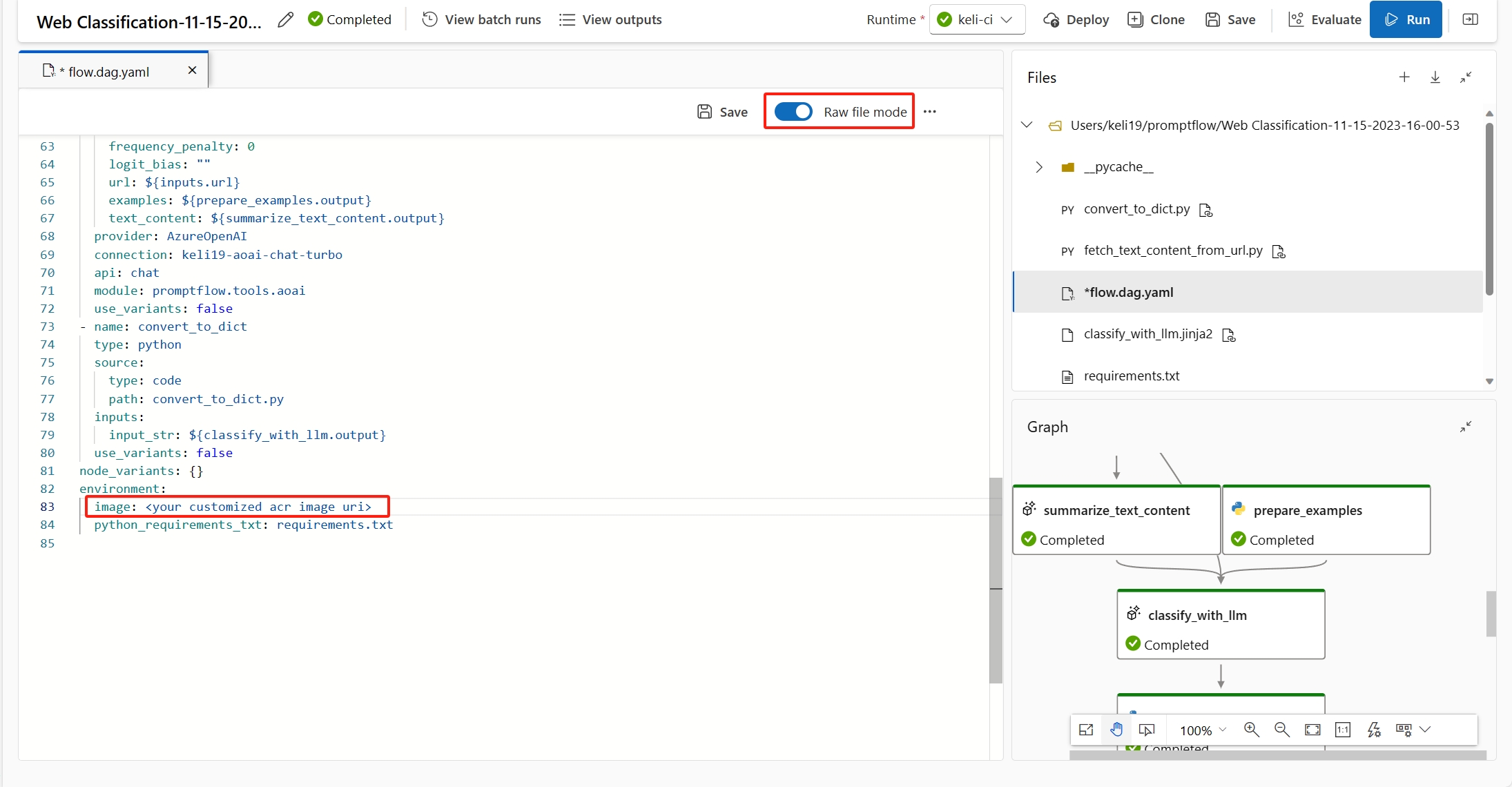
您可以在自訂環境定義中新增
inference_config,以修正此錯誤。以下是自訂環境定義的範例。


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
模型回覆花費太長的時間
有時候,您可能會注意到部署花費的時間太長而無法回應。 發生這種情況有幾個潛在因素。
- 流程中使用的模型效能不足 (例如:使用 GPT 3.5 而不是 text-ada)
- 索引查詢未最佳化且花費太長的時間
- 流程有許多要處理的步驟
請考慮上述考量事項將端點最佳化,以改善模型的效能。
無法擷取部署結構描述
部署端點後想要在端點詳細資料頁面的 [測試] 索引標籤中測試它,如果 [測試] 索引標籤顯示無法擷取部署結構描述,您可以嘗試下列兩種方法來減輕此問題:
![螢幕擷取畫面:端點詳細資料頁面的 [測試] 索引標籤中顯示無法擷取部署結構描述的錯誤。](media/how-to-deploy-for-real-time-inference/unable-to-fetch-deployment-schema.png?view=azureml-api-2#lightbox)
- 請確定您已將正確的權限授與端點身分識別。 深入了解如何將權限授與端點身分識別。
- 這可能是因為您在舊版執行階段中執行流程,然後部署流程,所以部署也使用了舊版中執行階段的環境。 若要更新執行階段,請遵循在 UI 上建立執行階段,並在最新的執行階段重新執行流程,然後再次部署流程。
拒絕存取以列出工作區秘密
如果您遇到「拒絕列出工作區祕密的存取」之類的錯誤,請檢查您是否已將正確權限授與端點身分識別。 深入了解如何將權限授與端點身分識別。
驗證和身分識別相關問題
如何在提示流程使用無認證資料存放區?
在 Azure AI Studio 中使用無認證記憶體。 您基本上需要執行下列動作:
- 將數據存放區驗證類型變更為 [無]。
- 將記憶體的專案 MSI 和使用者 Blob/檔案數據參與者許可權授與。
變更資料存放區驗證類型為無
您可以遵循 此部分的身分識別型數據驗證 ,讓您的數據存放區認證減少。
您必須將數據存放區的驗證類型變更為 None,代表meid_token型驗證。您可以從資料存放區詳細資料頁面或 CLI/SDK 進行變更: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

針對 Blob 型資料存放區,您可以變更驗證類型,並啟用工作區 MSI 來存取記憶體帳戶。

針對以檔案共享為基礎的數據存放區,您只能變更驗證類型。

授與權限給使用者識別或受控識別
若要在提示流程中使用無認證數據存放區,您必須將足夠的許可權授與使用者身分識別或受控識別,才能存取數據存放區。
- 請確定指派受控識別的工作區系統具有
Storage Blob Data Contributor記憶體帳戶的 和Storage File Data Privileged Contributor,至少需要讀取/寫入 (最好也包括刪除) 許可權。 - 如果您在提示流程中使用使用者身分識別這個預設選項,您必須確定使用者身分識別在記憶體帳戶上具有下列角色:
Storage Blob Data Contributor在記憶體帳戶上,至少需要讀取/寫入(最好也包含刪除)許可權。Storage File Data Privileged Contributor在記憶體帳戶上,至少需要讀取/寫入(最好也包含刪除)許可權。
- 如果您使用使用者指派的受控識別,您必須確定受控識別在記憶體帳戶上具有下列角色:
Storage Blob Data Contributor在記憶體帳戶上,至少需要讀取/寫入(最好也包含刪除)許可權。Storage File Data Privileged Contributor在記憶體帳戶上,至少需要讀取/寫入(最好也包含刪除)許可權。- 同時,如果您想要使用提示流程撰寫和測試流程,您至少必須將使用者身分
Storage Blob Data Read識別角色指派給記憶體帳戶。
- 如果您仍然無法檢視流程詳細數據頁面,且第一次使用提示流程的時間早於 2024-01-01,您必須將工作區 MSI
Storage Table Data Contributor授與工作區連結的記憶體帳戶。