本文說明如何在 Azure Machine Learning 雲端工作站上使用筆記本來開發定型腳本。 本教學課程涵蓋您開始使用所需的基本步驟:
- 設定和設定雲端工作站。 您的雲端工作站是由 Azure Machine Learning 計算執行個體提供支援,該執行個體已預先設定環境,以支援您的模型開發需求。
- 使用雲端式開發環境。
- 使用 MLflow 來追蹤您的模型計量。
先決條件
若要使用 Azure Machine Learning,您需要工作區。 如果您沒有工作區,請完成建立要開始使用所需要的資源以建立工作區,並深入了解其使用方式。
重要事項
如果您的 Azure Machine Learning 工作區已設定有受控虛擬網路,您可能需要新增輸出規則,以允許存取公用 Python 套件存放庫。 如需詳細資訊,請參閱案例:存取公用機器學習套件。
建立或啟動計算
您可以在工作區的 [計算] 區段中建立運算資源。 計算執行個體是雲端式工作站,完全由 Azure Machine Learning 管理。 本教學課程系列使用計算執行個體。 您也可以使用它來執行自己的程式碼,以及開發和測試模型。
- 登入 Azure Machine Learning Studio。
- 選取您的工作區 (如果尚未開啟)。
- 在左窗格中,選取 [計算]。
- 如果您沒有計算實例,您會在頁面中間看到 新增 。 選取 [新增],然後填妥表單。 您可以使用所有預設值。
- 如果您有計算執行個體,請從清單中選取它。 若已停止,請選取 [開始]。
開啟 Visual Studio Code (VS Code)
當您有一個正在運行的計算實例後,您可以透過各種方式存取它。 本教學課程說明如何使用 Visual Studio Code 中的計算執行個體。 Visual Studio Code 提供完整的整合式開發環境 (IDE) 來建立運算執行個體。
在計算執行個體清單中,針對您想使用的計算執行個體選取 [VS Code (Wed)] 或 [VS Code (桌面)] 連結。 如果您選擇 VS Code (桌面),可能會看到一則訊息,詢問您是否要開啟應用程式。

這個 Visual Studio Code 執行個體會連結至計算執行個體和工作區檔案系統。 即使您在桌面上開啟它,您看到的檔案是工作區中的檔案。
設定新的原型設計環境
為了讓您的腳本運行,您需要在設定了程式碼預期的相依性和程式庫的環境中工作。 本節可協助您建立針對程式碼量身打造的環境。 若要建立筆記本連線到的新 Jupyter 核心,您可以使用定義相依性的 YAML 檔案。
上傳檔案。
您上傳的檔案會儲存在 Azure 檔案共用中,而這些檔案會掛接至每個計算執行個體,並在工作區內共用。
移至 azureml-examples/tutorials/get-started-notebooks/workstation_env.yml。
選取頁面右上角的省略符號按鈕 (...),然後選取 [下載],將 Conda 環境檔案workstation_env.yml下載到您的電腦。
將檔案從電腦拖曳至 Visual Studio Code 視窗。 此檔案會上傳至您的工作區。
將檔案移至您的使用者名稱資料夾中。
選取檔案以預覽。 檢查所指定的相依性。 您應該會看到類似如下的內容:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlib建立核心。
現在使用終端機建立基於 workstation_env.yml 檔案的新 Jupyter 核心。
- 在 Visual Studio Code 頂端的功能表中,選取 [終端機 > ] [新增終端機]。
檢視您目前的 Conda 環境。 作用中的環境以星號【*】表示。
conda env list用於
cd導覽至您上傳 workstation_env.yml 檔案的資料夾。 例如,如果您已將它上傳至使用者資料夾,請使用下列命令:cd Users/myusername請確定workstation_env.yml在資料夾中。
ls根據提供的 Conda 檔案建立環境。 建置此環境需要幾分鐘的時間。
conda env create -f workstation_env.yml啟動新環境。
conda activate workstation_env附註
如果您看到 CommandNotFoundError,請依照指示執行
conda init bash,關閉終端機,然後開啟新的終端機。 然後再試一次命令conda activate workstation_env。確認正確的環境處於作用中狀態,再次尋找標示為 * 的環境。
conda env list建立以當前環境為基礎的新 Jupyter 內核。
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"關閉終端機視窗。
您現在有新的核心。 接下來,您將打開一個筆記本並使用此內核。
建立 Notebook
- 在 Visual Studio Code 頂端的功能表中,選取 [ 檔案 > 新增檔案]。
- 將新檔案命名為 develop-tutorial.ipynb (或使用其他名稱)。 請務必使用 .ipynb 副檔名。
設定核心
- 在新檔案的右上角,選取 [選取核心]。
- 選取 [Azure ML 計算執行個體 (computeinstance-name)]。
- 選取您建立的核心組: 教學工作站環境。 如果您沒有看到核心,請選取清單上方的 [重新整理] 按鈕。
開發定型指令碼
在本節中,您將開發 Python 訓練指令碼,以使用 UCI 資料集中準備好的測試和訓練資料集來預測信用卡預設付款。
此程式碼使用 sklearn 進行訓練,並使用 MLflow 來記錄指標。
從匯入您將在訓練指令碼中使用的套件和程式庫的程式碼開始。
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split接下來,載入並處理實驗的資料。 在本教學課程中,您會從網際網路上的檔案讀取資料。
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )準備訓練用的資料。
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.values新增程式碼以開始使用 MLflow 自動記錄,以便追蹤計量和結果。 憑藉模型開發的反覆性質,MLflow 可協助您記錄模型參數和結果。 請參閱不同的執行,以比較並瞭解模型的執行方式。 當您準備好從開發階段移至 Azure Machine Learning 內工作流程的定型階段時,這些記錄也會提供內容。
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()將模型定型。
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()附註
您可以忽略 MLflow 警告。 你需要的結果仍將被追蹤。
選取程式碼上方的 [全部執行]。
逐一查看
現在您已經有了模型結果,請變更某些內容並再次執行模型。 例如,嘗試不同的分類技術:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()附註
您可以忽略 MLflow 警告。 你需要的結果仍將被追蹤。
選取 [全部執行] 以執行模型。
檢查結果
現在您已經嘗試了兩種不同的模型,請使用 MLFfow 追蹤的結果來決定哪個模型更好。 您可以參考準確度等指標,或對您的案例最重要的其他指標。 您可以透過查看 MLflow 所創建的工作,更詳細地檢閱這些結果。
回到 Azure Machine Learning 工作室中您的工作區。
在左窗格中,選取 [作業]。
![螢幕擷取畫面,顯示左窗格中的 [工作] 項目。](media/tutorial-cloud-workstation/jobs.png?view=azureml-api-2)
選取 [在雲端開發教學課程]。
顯示了兩個任務,分別對應您嘗試的每個模型。 名稱是自動產生的。 如果您想要重新命名工作,請將滑鼠停留在名稱上,然後選取旁邊的鉛筆按鈕。
選取第一個作業的連結。 名稱會顯示在頁面頂端。 您也可以使用鉛筆按鈕在此處重新命名它。
此頁面會顯示作業詳細資料,例如屬性、輸出、標籤和參數。 在 標籤下,您會看到描述模型類型的 estimator_name。
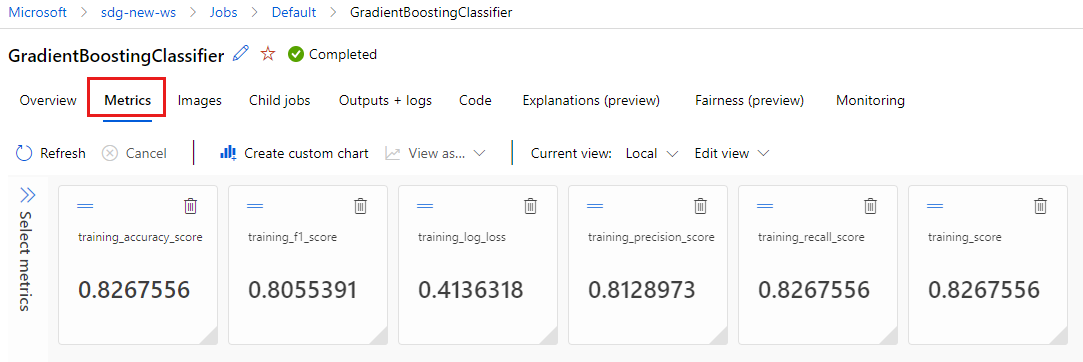
選取 [計量] 索引標籤,以檢視 MLflow 所記錄的計量。 (您的結果會有所不同,因為您有不同的訓練集。
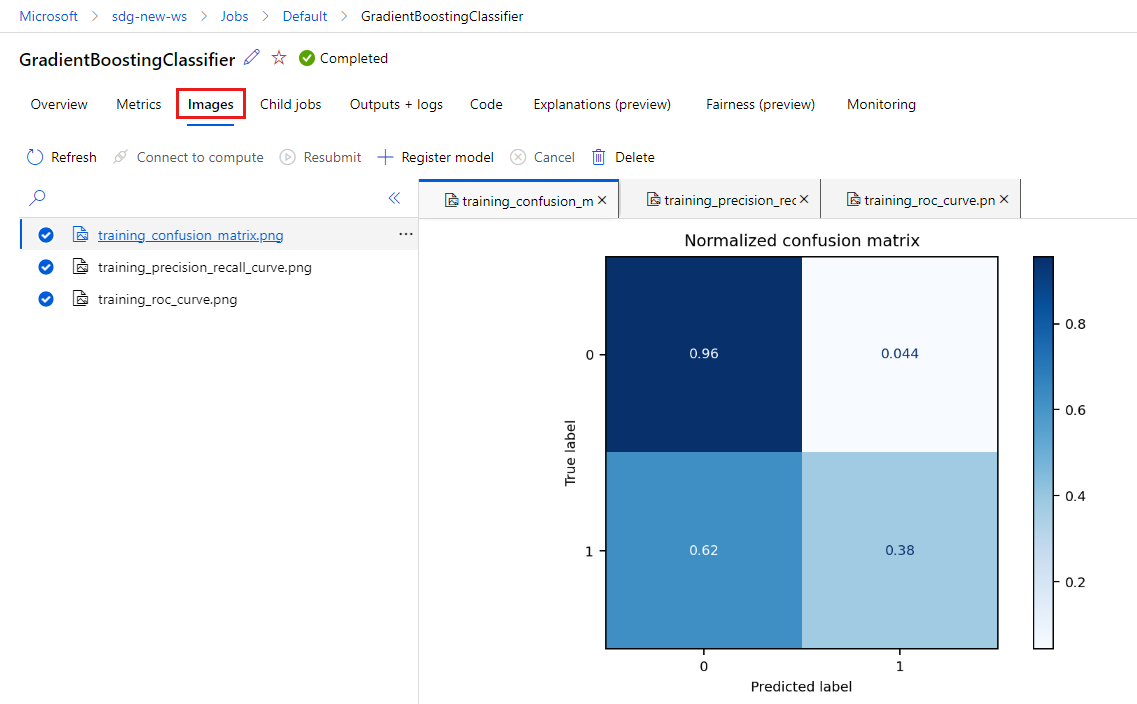
選取 [影像] 索引標籤以檢視 MLflow 所產生的影像。
返回並檢閱其他模型的計量和映像。

建立 Python 指令碼
您現在將從筆記本建立 Python 指令碼以進行模型訓練。
在 Visual Studio Code 中,以滑鼠右鍵按一下筆記本檔案名稱,然後選取 [將筆記本匯入腳本]。
選取 [檔案 > 儲存 ] 以儲存新的指令碼檔案。 將它稱為 train.py。
查看檔案並刪除訓練腳本中不需要的程式碼。 例如,保留您要使用的模型的程式碼,並刪除您不想使用的模型的程式碼。
- 請務必保留開始自動記錄的程式碼 (
mlflow.sklearn.autolog())。 - 當您以互動方式執行 Python 指令碼 (正如您在此所為) 時,您可以保留定義實驗名稱的行 (
mlflow.set_experiment("Develop on cloud tutorial"))。 或者,您可以為其指定不同的名稱,以將其視為「 工作」 區段中的不同條目。 但是,當您準備訓練作業的指令碼時,該行不適用,應該省略:作業定義包含實驗名稱。 - 當您訓練單一模型時,不需要加入開始和結束執行的行(
mlflow.start_run()和mlflow.end_run()),因為它們沒有影響,但您可以保留它們。
- 請務必保留開始自動記錄的程式碼 (
在完成編輯後,儲存檔案。
您現在有 Python 指令碼可用來定型您慣用的模型。
執行 Python 指令碼
現在,您正在計算執行個體上執行此程式碼,也就是您的 Azure Machine Learning 開發環境。 教學課程:訓練模型 示範如何在更強大的計算資源上以更具可擴展性的方式運行訓練腳本。
選取您稍早在本教學課程中建立的環境作為 Python 版本 (workstations_env)。 在筆記本的右下角,您會看到環境名稱。 選擇要設定的項目,然後在 Visual Studio Code 頂端選擇環境設定。
選取程式碼上方的 [全部執行] 按鈕來執行 Python 指令碼。
![顯示 [執行] 按鈕的螢幕擷取畫面。](media/tutorial-cloud-workstation/run-python.png?view=azureml-api-2)

![顯示 [執行] 按鈕的螢幕擷取畫面。](media/tutorial-cloud-workstation/run-python.png?view=azureml-api-2#lightbox)
附註
您可以忽略 MLflow 警告。 您仍然可以從自動記錄取得所有計量和映像。
檢查指令碼結果
回到 Azure Machine Learning 工作室中您的工作區中的 [作業],查看定型指令碼的結果。 請記住,訓練資料會隨著每次分割而變更,因此執行之間的結果會有所不同。
清除資源
如果您打算繼續學習其他教學課程,請跳至 後續步驟。
停止計算執行個體
如果現在不打算使用,請停止計算執行個體:
- 在 Studio 的左窗格中,選取 [計算]。
- 在頁面頂端,選取 計算實例。
- 在清單中,選取計算實例。
- 在頁面頂端,選取 [停止]。
刪除所有資源
重要事項
您所建立的資源可用來作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
如果不打算使用您建立的任何資源,請刪除以免產生任何費用:
在 Azure 入口網站的搜尋方塊中,輸入 [資源群組],然後從結果中選取它。
從清單中,選取您所建立的資源群組。
在 [概觀] 頁面上,選取 [刪除資源群組]。
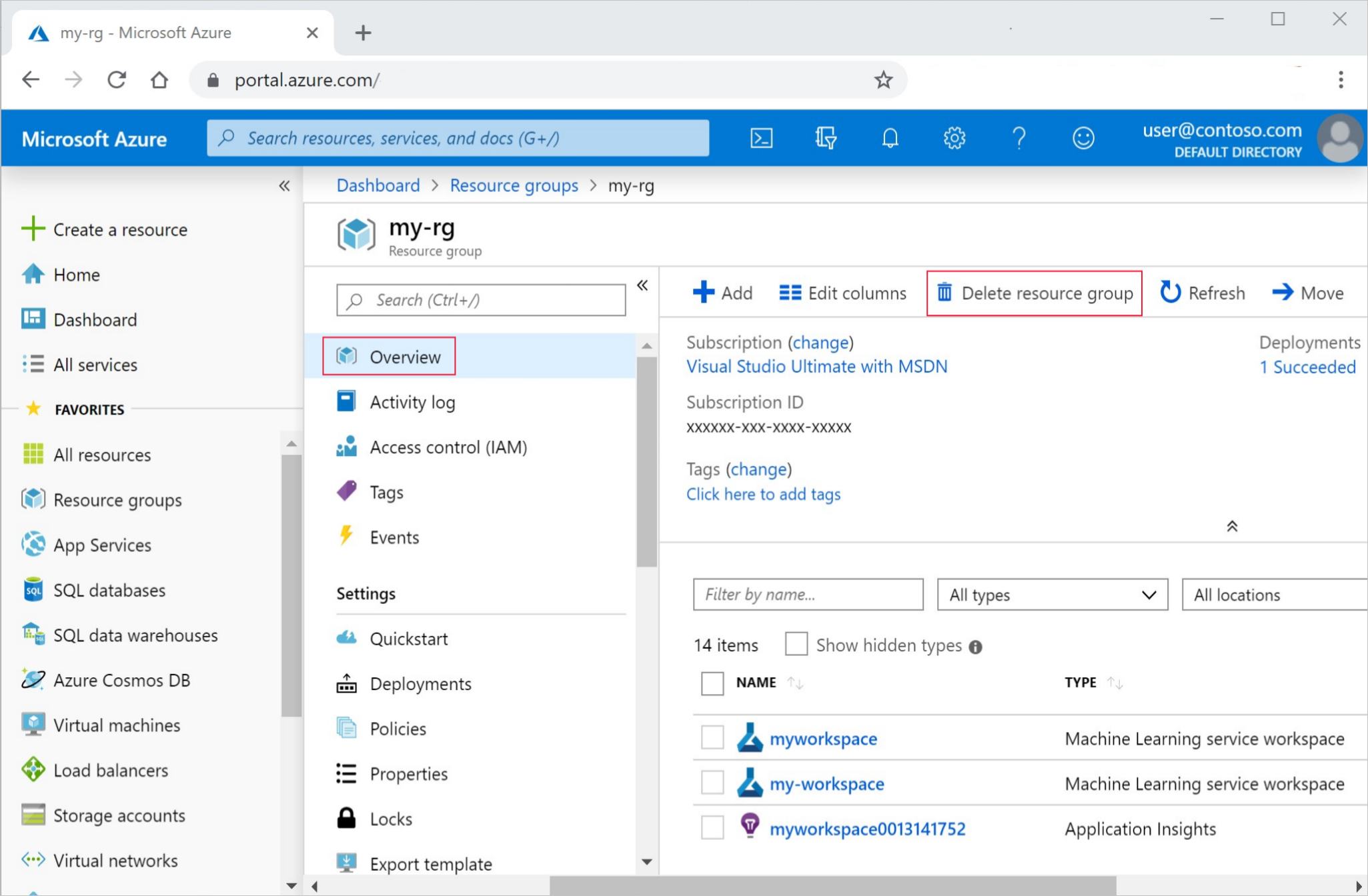
輸入資源群組名稱。 然後選取 [刪除]。
後續步驟
若要深入了解,請參閱下列資源:
- MLflow 中的人工產物和模型
- 使用 Git 搭配 Azure Machine Learning
- 在您的工作區中執行 Jupyter Notebook
- 在您的工作區中使用計算執行個體終端機
- 管理筆記本和終端工作階段
本教學課程示範建立模型的早期步驟,在程式碼所在的同一部機器上進行原型設計。 針對生產定型,了解如何在更強大的遠端計算資源上使用該定型指令碼: