教學課程:在 Azure Machine Learning 工作室中使用無程式碼自動化機器學習定型分類模型
在本教學課程中,您會瞭解如何在 Azure Machine Learning 工作室 中使用 Azure 機器學習,使用無程式代碼自動化機器學習 (AutoML) 來定型分類模型。 此分類模型會預測客戶是否訂閱與金融機構的固定期存款。
透過自動化 ML,您可以將耗用大量時間的工作自動化。 自動化機器學習會快速地逐一嘗試多種演算法和超參數的組合,協助您根據所選擇的成功計量找到最佳模型。
您在本教學課程中不會撰寫任何程式碼。 您可以使用 Studio 介面來執行定型。 您會了解如何執行下列工作:
- 建立 Azure Machine Learning 工作區
- 執行自動化機器學習實驗
- 探索模型詳細數據
- 部署建議的模型
必要條件
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請建立免費帳戶。
下載 bankmarketing_train.csv 資料檔案。 y 資料行指出客戶是否申請定期存款,稍後本教學課程會將其識別為預測的目標資料行。
注意
此銀行行銷資料集可在 Creative Commons (CCO: 公用網域) 授權。 個別資料庫內容中的任何權限都是以資料庫內容授權為依據,並可在 Kaggle 上取得。 此資料集原本位在 UCI Machine Learning 資料庫內。
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014.
建立工作區
Azure Machine Learning 工作區是雲端中您用來實驗、定型及部署機器學習模型的基礎資源。 工作區可將您的 Azure 訂用帳戶和資源群組與服務中容易使用的物件結合。
完成下列步驟以建立工作區並繼續進行教學課程。
選取 [建立工作區]。
提供下列資訊來設定新的工作區:
欄位 描述 工作區名稱 輸入可識別您工作區的唯一名稱。 名稱必須是整個資源群組中唯一的。 請使用可輕鬆回想並且與其他人建立的工作區有所區別的名稱。 工作區名稱不區分大小寫。 訂用帳戶 選取您要使用的 Azure 訂用帳戶。 資源群組 使用您訂用帳戶中現有的資源群組,或輸入名稱來建立新的資源群組。 資源群組會保留 Azure 方案的相關資源。 您需要參與者或擁有者角色,以使用現有的資源群組。 如需詳細資訊,請參閱管理對 Azure Machine Learning 工作區的存取。 區域 選取最接近使用者與資料資源的 Azure 區域,以建立工作區。 選取 [建立] 以建立工作區。
如需 Azure 資源的詳細資訊,請參閱 建立工作區。
如需在 Azure 中建立工作區的其他方式,請在入口網站或使用 Python SDK (v2) 管理 Azure Machine Learning 工作區。
建立自動化機器學習工作
使用 上的 https://ml.azure.comAzure Machine Learning 工作室,完成下列實驗設定並執行步驟。 機器學習 Studio 是合併的 Web 介面,其中包含機器學習工具,可針對所有技能層級的數據科學從業者執行數據科學案例。 Internet Explorer 瀏覽器不支援工作室。
選取訂用帳戶與您建立的工作區。
在瀏覽窗格中,選取 [撰寫>自動化 ML]。
由於本教學課程是您第一個自動化 ML 實驗,因此您會看到空白清單和文件連結。
![此螢幕快照顯示 [自動化 ML] 頁面,您可以在其中建立新的自動化 ML 作業。](media/tutorial-first-experiment-automated-ml/get-started.png?view=azureml-api-2)
選取 [ 新增自動化 ML 作業]。
在 [訓練方法] 中,選取 [自動訓練],然後選取 [開始設定作業]。
在 [基本設定] 中,選取 [新建],然後針對 [實驗名稱],輸入 my-1st-automl-experiment。
選取 [下一步 ] 以載入數據集。
![此螢幕快照顯示 [自動化 ML] 頁面,您可以在其中建立新的自動化 ML 作業。](media/tutorial-first-experiment-automated-ml/get-started.png?view=azureml-api-2#lightbox)
建立資料集並將其載入為資料資產
設定實驗之前,請先以 Azure 機器學習 數據資產的形式,將數據檔上傳至工作區。 在本教學課程中,您可以將數據資產視為自動化 ML 作業的數據集。 這麼做可讓您確保數據已針對實驗適當地格式化。
在 [工作類型與數據] 中,針對 [選取工作類型],選擇 [分類]。
在 [選取數據] 下,選擇 [建立]。
在 [資料類型] 表單中,提供您的數據資產名稱並提供選擇性描述。
針對 [ 類型],選取 [表格式]。 自動化 ML 介面目前僅支援 TabularDatasets。
選取 [下一步]。
在 [數據源] 表單中,選取 [從本機檔案]。 選取 [下一步]。
在 [目的地記憶體類型] 中,選取工作區建立期間自動設定的默認數據存放區: workspaceblobstore。 您可以將數據檔上傳至此位置,使其可供您的工作區使用。
選取 [下一步]。
在 [檔案或資料夾] 選取中,選取 [上傳檔案] 或 [上傳檔案] 資料夾>。
選擇您本機電腦上的 bankmarketing_train.csv 檔案。 您已將此檔案下載為 必要條件。
選取 [下一步]。
上傳完成時, 會根據檔類型填入數據預覽 區域。
在 [ 設定 ] 表單中,檢閱數據的值。 然後選取下一步。
欄位 描述 教學課程的值 File format 定義檔案中所儲存資料的版面配置和類型。 Delimited (分隔檔) 分隔符號 一或多個字元,其用來指定純文字或其他資料流中個別獨立區域之間的界限。 Comma 編碼方式 識別要用來讀取資料集之字元結構描述資料表的位元。 UTF-8 資料行標頭 指出資料集標頭 (如果有的話) 的處理方式。 All files have same headers (所有檔案都有相同的標頭) 跳過資料列 指出資料集內略過多少資料列 (如果有的話)。 無 [Schema] \(結構描述\) 表單可讓您進一步設定此實驗的資料。 針對此範例,請選取 [day_of_week] 的切換開關,如此一來,就不會將它包含在內。 選取 [下一步]。
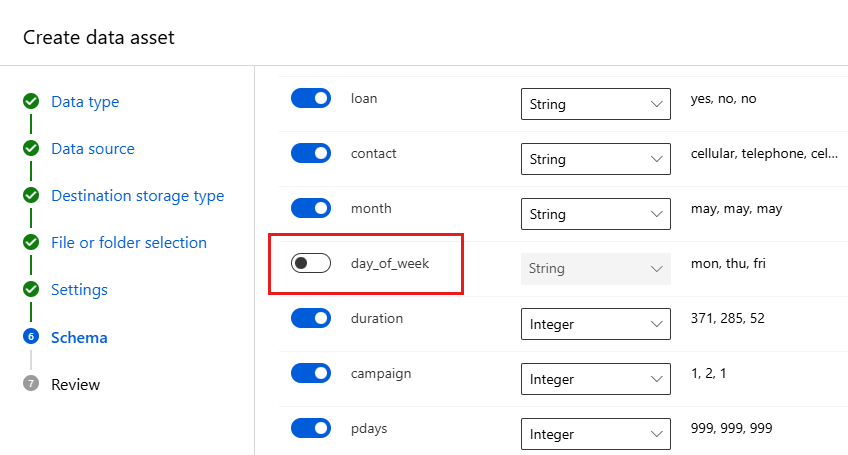
在 [檢閱] 窗體中,確認您的資訊,然後選取 [建立]。
從清單中選取您的資料集。
選取數據資產並查看預覽索引標籤,以檢閱數據。請確定它不包含day_of_week,然後選取 [關閉]。
選取 [下一步 ] 以繼續進行工作設定。
設定工作
在載入和設定資料之後,您可以設定您的實驗。 這項設定包括實驗設計工作,例如,選取計算環境的大小,以及指定您要預測的資料行。
填入 [ 工作設定 ] 表單,如下所示:
選取 y (String) 作為目標數據行,這是您想要預測的內容。 此資料行會指出用戶端是否已申請定期存款。
選取 [檢視其他組態設定] 並填入欄位,如下所示。 這些設定可進一步控制訓練作業。 否則會根據實驗選取範圍和資料來套用預設值。
其他設定 描述 教學課程的值 主要計量 用來測量機器學習演算法的評估計量。 AUCWeighted 解釋最佳模型 自動在自動化 ML 所建立的最佳模型上顯示可解釋性。 啟用 封鎖的模型 您要從定型作業中排除的演算法 無 選取儲存。
在 [驗證和測試] 下:
- 針對 [驗證類型],選取 k 折交叉驗證。
- 針對 [交叉驗證數目],選取 [2]。
選取 [下一步]。
選取 [計算叢集] 作為計算類型。
計算目標是用來執行定型指令碼或裝載服務部署的本機或雲端式資源環境。 針對此實驗,您可以嘗試雲端式無伺服器計算 (預覽版) 或建立您自己的雲端式計算。
注意
若要使用無伺服器計算, 請啟用預覽功能、選取 [無伺服器],然後略過此程式。
若要建立您自己的計算目標,請在 [選取計算類型] 中,選取 [計算叢集] 來設定計算目標。
填入 虛擬機 表單以設定您的計算。 選取新增。
欄位 描述 教學課程的值 Location 您要執行機器的區域 美國西部 2 虛擬機器階層 選取您的實驗應具備的優先順序 專用 虛擬機器類型 為您的計算選取虛擬機器類型。 CPU (中央處理器) 虛擬機器大小 為您的計算選取虛擬機器大小。 系統會根據您的資料和實驗類型提供建議的大小清單。 Standard_DS12_V2 選取 [下一步 ] 以移至 [ 進階設定] 窗體。
![此螢幕快照顯示 [進階設定] 頁面,您可以在其中輸入計算叢集的值。](media/tutorial-first-experiment-automated-ml/compute-settings.png?view=azureml-api-2)
欄位 描述 教學課程的值 計算名稱 可識別您計算內容的唯一名稱。 automl-compute 最小/最大節點數 若要分析資料,您必須指定一個或多個節點。 最小節點: 1
最大節點數:6縮小之前的閒置秒數 叢集自動縮小至最小節點計數之前的閒置時間。 120 (預設值) 進階設定 用於設定和授權虛擬網路以進行實驗的設定。 無 選取 建立。
建立計算可能需要幾分鐘的時間才能完成。
建立之後,請從清單中選取新的計算目標。 選取 [下一步]。
選取 [提交訓練作業] 以執行實驗。 [概觀] 畫面隨即開啟,在實驗準備開始時,會以頂端的 [狀態] 開啟。 此狀態會隨著實驗的進行而更新。 通知也會出現在 Studio 中,通知您實驗的狀態。
![此螢幕快照顯示 [進階設定] 頁面,您可以在其中輸入計算叢集的值。](media/tutorial-first-experiment-automated-ml/compute-settings.png?view=azureml-api-2#lightbox)
重要
準備實驗執行需要 10-15 分鐘的時間。 執行之後,每個反覆項目需要 2-3 分鐘以上的時間。
在生產環境中,您可以先離開一下。 但在本教學課程中,您可以在其他演算法繼續執行時,開始探索 [模型] 索引標籤上的已測試演算法。
探索模型
流覽至 [ 模型 + 子作業 ] 索引標籤,以查看已測試的演算法(models)。 根據預設,作業會依計量分數排序模型完成。 在本教學課程中,根據所選 AUCWeighted 計量評分最高的模型位於清單頂端。
當您等候所有實驗模型完成時,可選取已完成模型的演算法名稱來探索其效能詳細資料。 選取 [概 觀 ] 和 [ 計量] 索引 標籤,以取得作業的相關信息。
下列動畫會檢視所選模型的屬性、計量和效能圖表。

檢視模型說明
在您等候模型完成時,也可以查看模型說明,並查看影響特定模型預測的資料功能 (原始或工程)。
您可以視需要產生這些模型說明。 屬於 [說明] 索引標籤一部分的模型說明儀錶板摘要說明這些說明。
若要產生模型說明:
在頁面頂端的導覽連結中,選取要返回 [模型 ] 畫面的作業名稱。
選取 [ 模型 + 子作業] 索引標籤。
在本教學課程中,請選取第一個 MaxAbsScaler、LightGBM 模型。
選取 [ 說明模型]。 右側即出現 [說明模型] 窗格。
選取您的計算類型,然後選取您先前建立的實例或叢集: automl-compute 。 此計算會啟動子作業以產生模型說明。
選取 建立。 綠色成功訊息隨即出現。
注意
可解釋性作業大約需要 2-5 分鐘才能完成。
選取 [說明][預覽]。 此索引標籤會在說明性執行完成之後填入。
在左側展開窗格。 在 [功能] 底下,選取顯示未經處理的數據列。
選取 [ 匯總特徵重要性] 索引標籤 。此圖表顯示哪些數據特徵會影響所選模型的預測。
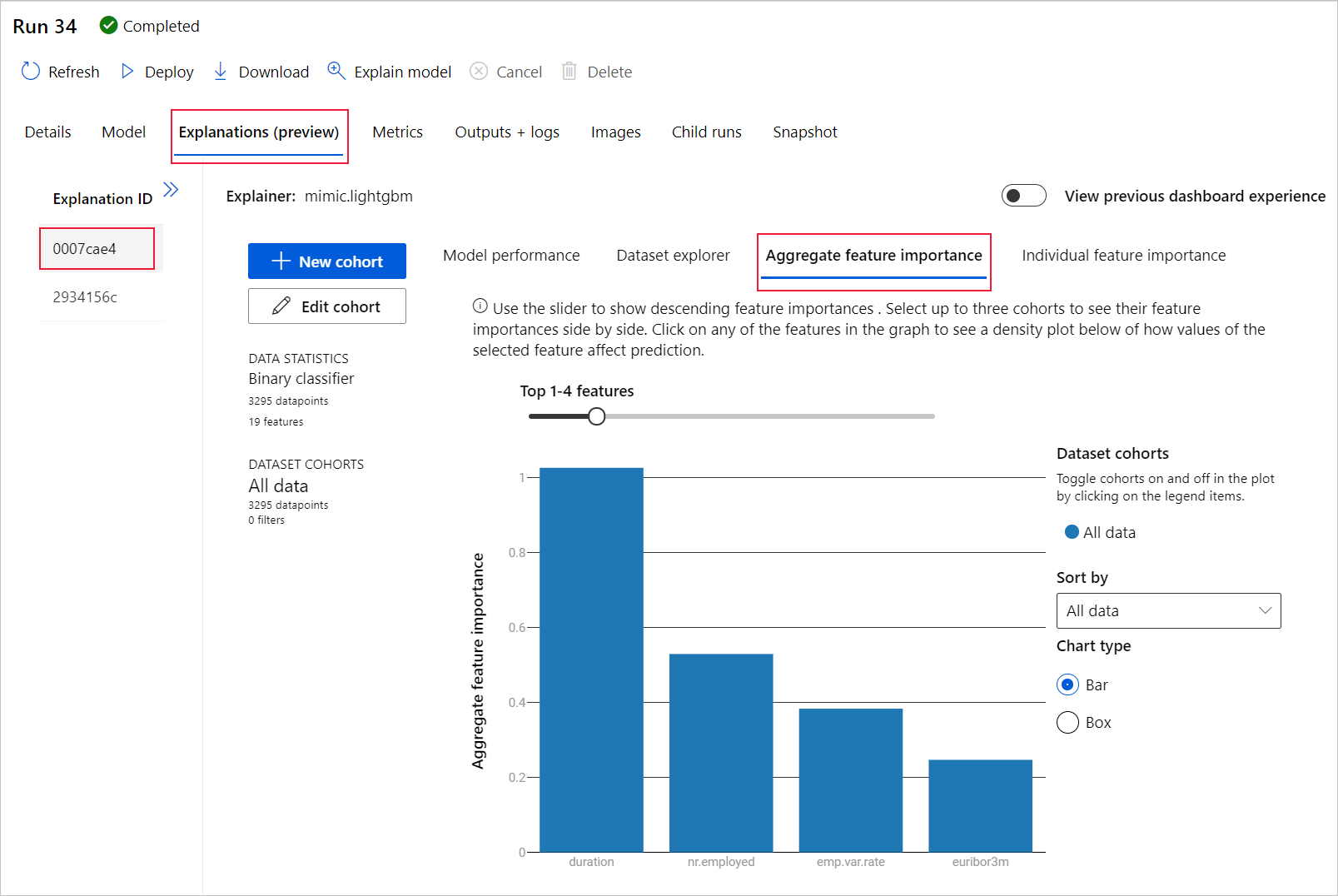
在此範例中,持續時間 似乎對此模型的預測有最大的影響。

部署最佳模型
自動化機器學習介面可讓您將最佳模型部署為 Web 服務。 部署 是模型的整合,因此它可以預測新的數據,並識別潛在的商機領域。 此實驗中對 Web 服務的部署表示金融機構現在有可反覆進行且可調整的 Web 解決方案,能識別潛在的定期存款客戶。
檢查您的實驗執行是否完成。 若要這樣做,請選取畫面頂端的作業名稱,以流覽回父作業頁面。 [完成] 狀態會顯示在畫面的左上方。
實驗執行完成後, [詳細 數據] 頁面會填入 [最佳模型摘要 ] 區段。 在此實驗內容中, VotingEnsemble 會根據 AUCWeighted 計量被視為最佳模型。
部署此模型。 部署大約需要 20 分鐘才能完成。 部署程序需要幾個步驟,包括註冊模型、產生資源,以及為 Web 服務設定這些資源。
選取 [VotingEnsemble] 以開啟模型特定頁面。
選取 [部署>Web 服務]。
填入 [部署模型] 窗格,如下所示:
欄位 值 名稱 my-automl-deploy 描述 我的第一個自動化機器學習實驗部署 計算類型 選取 Azure 容器實例 啟用驗證 [停用]。 使用自訂部署資產 [停用]。 允許自動產生預設驅動程式檔案(評分腳本)和環境檔案。 在此範例中,請使用 [ 進階 ] 功能表中提供的預設值。
選取部署。
綠色成功訊息會出現在 [作業] 畫面頂端。 在 [模型摘要] 窗格中,狀態消息會出現在 [部署狀態] 底下。 定期選取 [重新整理] 以檢查部署狀態。
您有可操作的 Web 服務來產生預測。
繼續進行相關內容,以深入瞭解如何使用新的 Web 服務,並使用 Azure 內建的 Power BI 來測試預測 機器學習 支援。
清除資源
部署檔案比資料和實驗檔案大,因此儲存的成本會較高。 如果您想要保留工作區和實驗檔案,請只刪除部署檔案,以將帳戶的成本降到最低。 如果您不打算使用任何檔案,請刪除整個資源群組。
刪除部署執行個體
只從 Azure 機器學習 刪除部署實例https://ml.azure.com/.
移至 Azure Machine Learning。 流覽至工作區,然後在 [資產] 窗格底下,選取 [端點]。
選取您想要刪除的部署,然後選取 [刪除]。
選取 [繼續]。
刪除資源群組
重要
您所建立的資源可用來作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
如果不打算使用您建立的任何資源,請刪除以免產生任何費用:
在 [Azure 入口網站] 的搜尋方塊中,輸入 [資源群組],然後從結果中選取它。
從清單中,選取您所建立的資源群組。
在 [概觀] 頁面上,選取 [刪除資源群組]。
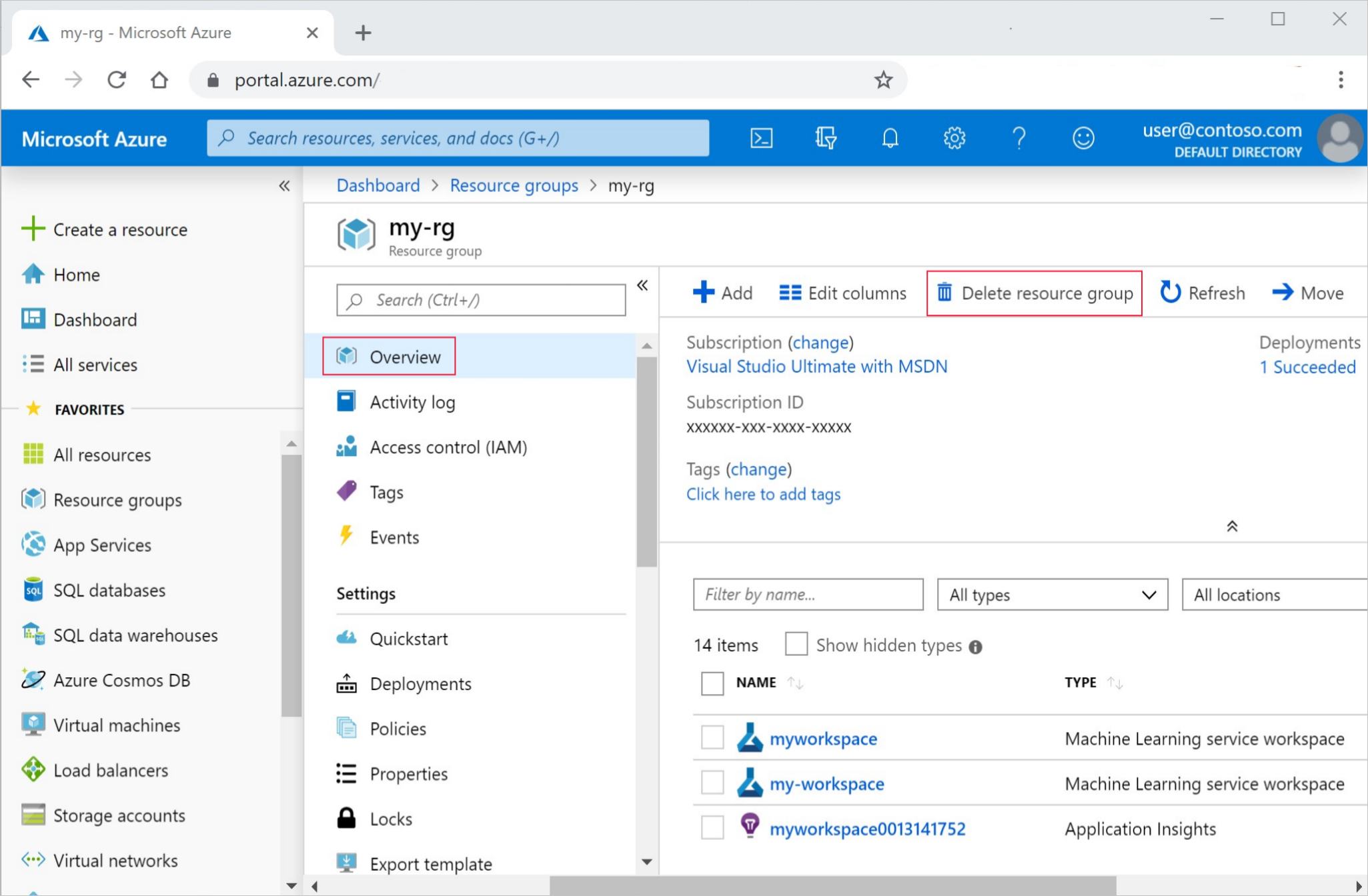
輸入資源群組名稱。 接著選取刪除。
相關內容
在此自動化機器學習教學課程中,您已使用 Azure Machine Learning 的自動化 ML 介面來建立及部署分類模型。 如需詳細資訊和後續步驟,請參閱下列資源:
- 深入了解自動化機器學習。
- 了解分類計量和圖表: 評估自動化機器學習實驗結果 一文。
- 深入了解如何設定 NLP 的 AutoML。
也請嘗試這些其他模型類型的自動化機器學習:
- 如需預測的無程式代碼範例,請參閱教學課程:在 Azure Machine Learning 工作室 中使用無程式代碼自動化機器學習的預測需求。
- 如需物件偵測模型的第一個程式碼範例,請參閱教學課程:使用 AutoML 和 Python 來將物件偵測模型定型。