Azure Managed Redis 運行於 Redis Enterprise 堆疊上,這比 Redis 社群版有顯著優勢。 下列資訊提供 Azure Managed Redis 架構方式的更詳細資料,包括對進階使用者有用的資訊。
與 Azure Cache for Redis 的比較
Azure Cache for Redis 的 Basic 、Standard 和 Premium 三層可運行於 Redis 社群版。 此 Redis 社群版本有數個重大限制,包括單個線程。 這個限制大幅降低效能,也讓擴展效率降低,因為服務沒有充分利用更多 vCPU。 典型 Azure Cache for Redis 執行個體會使用如下的架構:
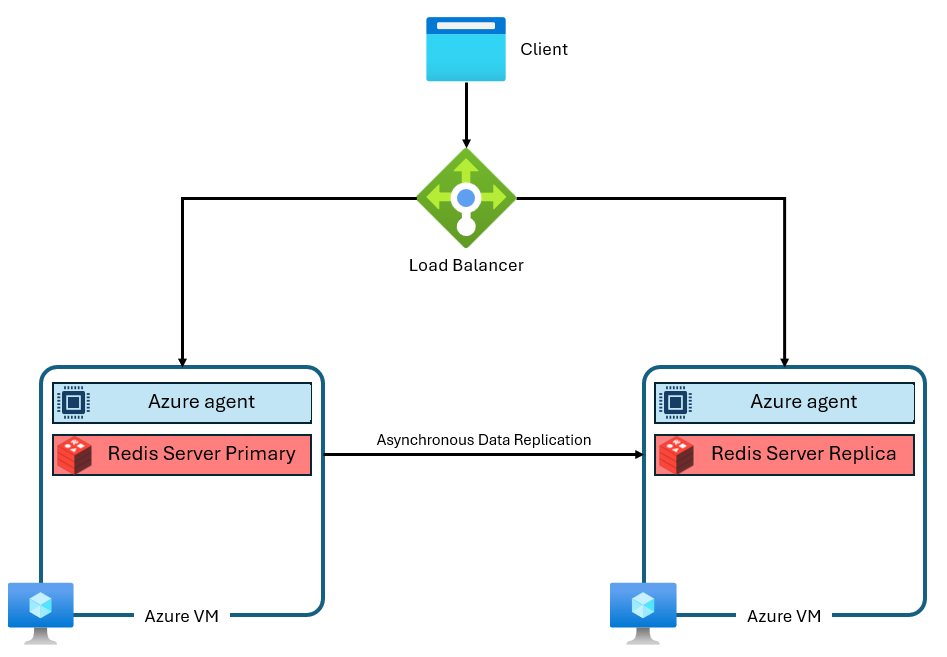
請注意使用了兩個虛擬機——一個是主虛擬機,一個是複本。 這些虛擬機也被稱為節點。 主節點負責保留主要的 Redis 程序,並接受所有寫入。 複寫會以非同步方式對複本節點執行,在維護、調整或未預期的失敗期間提供備份複本。 由於社群 Redis 採用單執行緒設計,每個節點只能執行一個 Redis 伺服器程序。
Azure Managed Redis 的架構改進
Azure Managed Redis 使用更進階的架構,如下所示:
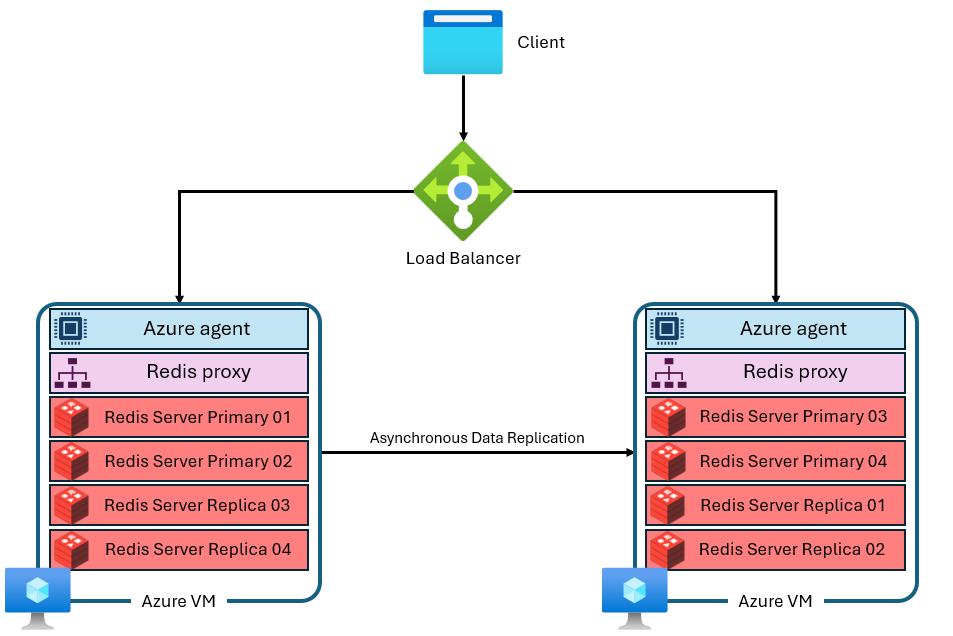
有數個相異之處:
- 每個虛擬機(或節點)會平行執行多個 Redis 伺服器程序(稱為分片)。 多個分區可讓每個虛擬機器上的 vCPU 更有效率地使用,並且有更高的效能。
- 並非所有主要 Redis 分區都位於相同 VM/節點上。 相反地,主要和複本分區會分散到這兩個節點。 由於主要分片比複本分片消耗更多 CPU 資源,此方法使更多主要分片能平行運行。
- 每個節點都有高效能 Proxy 程序來管理分區、處理連線管理,以及觸發自我修復。
此架構同時支援更高效能及進階功能,如 主動式地理複製。
叢集
每個 Azure 受控 Redis 實例都在內部配置為使用叢集,適用於所有層級和 SKU。 Azure Managed Redis 是基於 Redis Enterprise,可以在每個節點使用多個分片。 這項功能包括只設定為使用單一分片的較小實例。 叢集是一種將 Redis 實例中資料劃分到多個 Redis 程序的方法,也稱為分片。 Azure Managed Redis 提供三種 叢集策略 ,決定 Redis 用戶端可用哪種協定連接快取實例。
叢集原則
Azure Managed Redis 提供三種叢集原則:OSS、企業和非叢集。 OSS 叢集政策對大多數應用程式來說是好的,因為它支援更高的最大吞吐量,但每個版本都有其優缺點。
- 如果你是從 Basic、Standard 或 Premium 非叢集拓撲轉換,建議考慮使用 OSS 叢集來提升效能。 只有當你的應用程式無法支援 OSS 或企業拓撲時,才使用非叢集配置。 OSS 叢集政策實作與 Redis 開源軟體相同的 API。 Redis 叢集 API 允許 Redis 用戶端直接連接每個 Redis 節點的分片,降低延遲並優化網路吞吐量。 隨著分片和虛擬CPU數量增加,吞吐量幾乎呈線性成長。 OSS 叢集政策通常提供最低延遲與最佳吞吐量效能。 不過,OSS 叢集政策要求你的客戶端函式庫必須支援 Redis 叢集 API。 目前,幾乎所有 Redis 用戶端都支援 Redis 叢集 API,但相容性可能是舊版用戶端版本或特製化程式庫的問題。
你無法在 RediSearch 模組中使用 OSS 叢集策略。
OSS 叢集通訊協定需要客戶端進行正確的分區連線。 初始連線是透過埠 10000。 連接單一節點時,會使用85XX範圍的埠口。 85xx 的埠口會隨時間改變,你不應該硬編碼進你的應用程式。 支援叢集的 Redis 用戶端會使用 CLUSTER NODES 命令來判斷主要和複本分區所使用的確切埠,併為您建立分區連線。
企業叢集政策是一種較簡單的設定,使用單一端點管理所有用戶端連線。 當你使用企業叢集策略時,它會將所有請求路由到一個作為代理的 Redis 節點。 此節點內部將請求路由至叢集中正確的節點。 這種方法的優點在於,讓 Azure 託管 Redis 對用戶看起來不具叢集特性。 這表示 Redis 用戶端函式庫不需要支援 Redis 叢集,也能享有 Redis Enterprise 的一些效能優勢。 使用單一端點提升向下相容性,並使連線更簡單。 缺點是單一節點代理可能會成為計算利用率或網路吞吐量的瓶頸。
企業叢集原則是唯一能搭配 RediSearch 模組使用的原則。 雖然企業叢集原則會讓 Azure 受控 Redis 實例在使用者看來是非叢集的,但多鍵命令仍有一些限制。
非叢集叢集原則會將資料儲存在每個節點上,但不進行分區化。 它只適用於大小為 25 GB 且更小的快取。 使用非叢集叢集政策的情境包括:
- 從未分區的 Redis 環境移轉時。 例如,Azure Cache for Redis 中 Basic、Standard 和 Premium SKU 的非分片架構。
- 廣泛執行跨插槽命令並將資料分割到分區時,可能導致系統故障。 例如,MULTI 命令。
- 使用 Redis 作為訊息代理程式且不需要分區化時。
使用非叢集政策時的考量包括:
- 此政策僅適用於 Azure 管理的 Redis 等級,其大小小於或等於 25 GB。
- 它的效能不如其他叢集策略,因為只有在快取被分片時,CPU 才能利用 Redis Enterprise 軟體執行多線程。
- 如果您想擴展 Azure 受控 Redis 快取,您必須先更改叢集策略。
- 如果你是從 Basic、Standard 或 Premium 非叢集拓撲轉換過來,可以考慮使用 OSS 叢集來提升效能。 只有當你的應用程式無法支援 OSS 或企業拓撲時,才使用非叢集配置。
擴增或新增節點
核心 Redis 企業軟體可透過使用較大的虛擬機來擴展,或透過增加更多節點或虛擬機來擴展。 這兩種縮放選項都增加了更多記憶體、更多虛擬處理器和更多分片。 由於這種冗餘性,Azure Managed Redis 無法控制每個配置中所使用的節點數量。 這些實作細節被抽象化,以避免混淆、複雜性及次優配置。 相反地,每個 SKU 都設計出能最大化 vCPU 與記憶體的節點配置。 Azure Managed Redis 的某些 SKU 使用兩個節點,而其他則使用更多節點。
多鍵命令
因為 Azure 管理的 Redis 實例採用叢集配置,你可能會在多個鍵上執行指令時看到 CROSSSLOT 例外。 具體行為會隨著使用的叢集原則而不同。 如果您使用 OSS 叢集原則,所有多索引鍵命令的索引鍵都必須對應至相同雜湊位置。
您也可能看到企業叢集原則出現 CROSSSLOT 錯誤。 企業叢集時,僅允許跨槽位使用以下多鍵指令:DEL、MSET、MGET、EXISTS、UNLINK和TOUCH。
在 Active-Active 資料庫中,多鍵寫入指令(,DELMSET , UNLINK)只能在同一插槽中的鍵上執行。 不過,在主動-主動資料庫的各位置可使用下列多索引鍵命令:MGET、EXISTS 和 TOUCH。 如需詳細資訊,請參閱資料庫叢集。
分區化設定
Azure Managed Redis 的每個 SKU 會平行執行特定數量的 Redis 伺服器程序,稱為 分片。 吞吐量效能、分片數量與每個實例可用虛擬CPU數量之間的關係相當複雜。 你無法手動更改碎片數量。
在相同記憶體大小下,記憶體優化版本擁有最少的 vCPU 與分片數量,而計算優化版本則擁有最多。
增加分片數量通常能提升效能,因為 Redis 操作可以平行執行。 但如果沒有可用的 vCPU 執行指令,效能可能會下降。
分片會被映射以優化每個 vCPU 的使用率,同時保留 vCPU 週期給 Redis 伺服器程序、管理代理程式及作業系統任務,這些任務同時也影響效能。 你建立的客戶端應用程式與 Azure Managed Redis 互動,就像它是單一邏輯資料庫一樣。 該服務負責管理 vCPU 和分片之間的路由。
要增加 SKU 的碎片數量,請使用該 SKU 中較高的分層。 你也可以調整 SKU 以符合你的效能需求。
下表顯示在特定階層大小下,vCPU 與主要分片的比例。 欄位中的資料並不保證這是 vCPU 或分片的數量。 這些表格僅供說明。
備註
Azure 託管 Redis 會透過調整每個 SKU 上使用的分片數目與 vCPU,隨時間優化效能。
記憶體優化、平衡與運算優化版本
下表展示了 大小 與 vCPU 或主要分片關係的一般範例。
| 級別 | 記憶體最佳化 | 平衡 | 計算最佳化 |
|---|---|---|---|
| 大小 (GB) | vCPU/主要分區 | vCPU/主要分區 | vCPU/主要分區 |
| 24 ¹ | 4/2 | 8月6日 | 12月16日 |
| 60 ¹ | 8月6日 | 12月16日 | 32/24 |
¹ 在特定階層大小下,vCPU 與主要分片的比例並不代表 SKU 或等級的保證。
閃存優化版本
下表展示了 大小 與 vCPU 或主要分片關係的一般範例。
| 級別 | Flash Optimized (預覽) |
|---|---|
| 大小 (GB) | vCPU/主要分區 |
| 480 ¹ ² | 12月16日 |
| 720 ¹ ² | 24/24 |
¹ 這些分級目前為公開預覽。
² 在特定階層大小下,vCPU 與主要分片的比例並不代表 SKU 或階層的保證。
這很重要
所有使用超過 350 GB 儲存空間的記憶體內層級皆在公開預覽中,包括記憶體優化 M500 及以上版本;平衡B500及以上;以及 Compute Optimized X500 及以上版本。 所有這些層級和更高層級都處於公開預覽狀態。
所有 Flash 優化層都處於公開預覽狀態。
在沒有啟用高可用性模式的情況下執行
你可以在不啟用高可用性(HA)模式的情況下執行。 這個設定代表你的 Redis 實例沒有啟用複寫,也無法存取可用性 SLA。 除了開發和測試場景外,不要在非 HA 模式下執行。 你無法在已經建立的實例中關閉高可用性。 您可以在尚未設定高可用性的執行個體啟用高可用性。 因為執行一個沒有高可用性的實例會消耗較少的虛擬機和節點,虛擬處理器的使用效率降低,效能可能會較低。
啟用 HA 模式後,你的實例會部署,主分片和複本分片分布在至少兩個節點上。 此配置建議適用於所有生產場景及可用性SLA存取。 在支援可用性區域的區域,Azure Managed Redis 預設會將節點分配到不同區域。 欲了解更多資訊,請參閱 Azure Managed Redis 的可靠性。
保留的記憶體
在每個 Azure Managed Redis 執行個體上,大約 20% 的可用記憶體會保留為非快取作業的緩衝區,例如容錯移轉期間的複寫和作用中異地複寫緩衝區。 此緩衝區有助於改善快取效能,並防止記憶體耗盡。
縮小
Azure 託管 Redis 目前不支援縮小規模。 如需詳細資訊,請參閱 調整 Azure 受控 Redis 的限制。
快閃最佳化層
快閃最佳化層會同時使用 NVMe 快閃儲存體和 RAM。 由於快閃儲存體成本較低,因此使用快閃最佳化層可讓您以一些效能來換取價格效率。
在快閃最佳化執行個體上,20% 的快取空間位於 RAM 上,而其他 80% 則使用快閃儲存體。 所有索引鍵都會儲存在 RAM 上,而值可以儲存在快閃儲存體或 RAM 中。 Redis 軟體會以智慧方式判斷值的位置。 頻繁存取的經常性存取層值會儲存在 RAM 上,而不常使用的極非經常性存取層值則會保留在快閃上。 在讀取或寫入資料之前,必須將它移至 RAM,成為經常性存取層資料。
由於 Redis 會針對最佳效能最佳化,因此執行個體會先填滿可用的 RAM,再將項目新增至快閃儲存體。 首先填滿 RAM 對效能有一些影響:
- 以低記憶體使用量進行測試時,可能會發生更佳的效能和較低的延遲。 在使用完整快取實例進行測試時,效能可能會較低,因為在低記憶體使用的測試階段中只使用 RAM 記憶體。
- 隨著您將更多資料寫入快取,相較於快閃儲存體,RAM 中的資料比例會降低,通常也會降低延遲和輸送量效能。
適用於快閃最佳化層的工作負載
在快閃優化層級上運行良好的工作負載通常具有以下特性:
- 大量讀取,對比寫入命令具有高比率的讀取命令。
- 集中存取使用頻率遠高於資料集其他部分的索引鍵子集。
- 與索引鍵名稱相比,相對較大的值。 (因為索引鍵名稱一律會儲存在 RAM 中,因此大型值可能會成為記憶體成長的瓶頸。)
不適用於快閃最佳化層的工作負載
某些工作負載具有針對快閃最佳化層設計較不最佳化的存取特性:
- 大量寫入工作負載。
- 大部分資料集的隨機或統一資料存取模式。
- 具有相對較小值大小的長索引鍵名稱。
相關內容
- 縮放 Azure Managed Redis 執行個體 (部分機器翻譯)