多租用戶 SaaS 應用程式與 Azure AI 搜尋服務的設計模式
多租用戶應用程式是為不能查看或共用任何其他租用戶資料的租用戶,提供相同服務和功能的應用程式,其中租用戶的數目並無限制。 本文將針對 Azure AI 搜尋服務建置的多租用戶應用程式,討論租用戶隔離策略。
Azure AI 搜尋服務概念
Azure AI 搜尋服務是一個搜尋即服務解決方案,可讓開發人員不需管理任何基礎結構或成為資訊擷取專家,就能夠將豐富的搜尋體驗新增到應用程式中。 資料會上傳至服務,然後儲存在雲端。 使用對 Azure AI 搜尋服務 API 的簡單要求,接著便可修改及搜尋資料。
搜尋服務、索引、欄位及文件
在討論設計模式之前,請務必先了解一些基本概念。
使用 Azure AI 搜尋服務時,使用者需訂閱搜尋服務。 由於資料是上傳到 Azure AI 搜尋服務,因此它會儲存在該搜尋服務內的索引中。 單一服務內可能會有好幾個索引。 若要使用熟悉的資料庫概念,搜尋服務可以比喻為資料庫,而服務內的索引則可比喻為資料庫內的資料表。
搜尋服務內的每個索引都有自己的結構描述,此結構描述是由一些可自訂的「欄位」 所定義。 資料會以個別文件的形式新增到 Azure AI 搜尋服務索引中。 每個文件都必須上傳至特定的索引,並且必須符合該索引的結構描述。 使用 Azure AI 搜尋服務來搜尋資料時,會針對特定索引發出全文檢索搜尋查詢。 若要將這些概念比喻成資料庫的概念,則欄位可以比喻為資料表中的資料行,而文件則可以比喻為資料列。
延展性
「標準」定價層中的任何 Azure AI 搜尋服務都可以調整成兩個維度︰儲存體和可用性。
- 來增加搜尋服務的儲存體。
- 可被新增到服務中,以增加搜尋服務所能處理的要求輸送量。
新增及移除資料分割和複本將可讓搜尋服務的容量,隨著應用程式要求的資料量和流量成長。 為了讓搜尋服務達到讀取 SLA,它將需要兩個複本。 為了讓服務達到讀寫 SLA,它將需要三個複本。
Azure 搜尋服務中的服務和索引限制
Azure AI 搜尋服務有幾個不同的定價層,每個層都有不同的限制和配額。 這些限制當中有些在服務層級,有些在索引層級,有些則是在資料分割層級。
S3 高密度
在 Azure AI 搜尋服務的 S3 定價層中,有一個專門針對多租用戶案例設計的「高密度」(HD) 模式選項。 在許多情況下,必須在單一服務下支援大量較小的租用戶,才能達到簡化和成本效益的好處。
S3 HD 會以使用資料分割擴增索引的能力換取在單一服務中裝載更多索引的能力,來允許在單一搜尋服務的管理下封裝許多小型索引。
S3 服務的設計目的是裝載固定數目的索引 (最多 200 個),並允許每個索引在新增至服務時,可水平縮減大小。 如將分割區新增至 S3 HD 服務,會增加服務可裝載的最大索引數目。 個別 S3HD 索引的理想大小上限是大約 50 - 80 GB,雖然系統並未對每個索引設下硬性的大小限制。
多租用戶應用程式的考量
多租用戶應用程式必須有效地將資源分散到各個租用戶中,同時又在各個租用戶之間保留某種程度的隱私性。 設計這類應用程式的架構時,有幾個考量︰
租用戶隔離︰ 應用程式開發人員需要採取適當措施,以確保沒有任何租用戶能夠在未經授權或不需要的情況下存取其他租用戶的資料。 除了資料隱私性的觀點以外,租用戶隔離策略還需要有效的共用資源管理,以及對吵雜鄰居的防範。
雲端資源成本︰ 與任何其他應用程式一樣,軟體解決方案作為多租用戶應用程式的元件,必須保有成本競爭力。
操作輕鬆︰ 開發多租用戶架構時,對應用程式的作業與複雜性的影響是很重要的考量。 Azure AI 搜尋服務具有 99.9% 的 SLA。
遍佈全球︰多租用戶應用程式經常需要為分散在全球各地的租用戶提供服務。
延展性︰ 應用程式開發人員需要考慮到要如何讓應用程式不要太複雜,而又要能設計應用程式來依租用戶數目及租用戶資料和工作負載大小做調整。
Azure AI 搜尋服務提供一些可用來隔離租用戶資料和工作負載的界限。
使用 Azure AI 搜尋服務來建立多租用戶模型
在多租用戶案例的情況中,應用程式開發人員會使用一或多個搜尋服務,然後將其租用戶劃分到服務、索引或兩者。 建立多租用戶案例模型時,Azure AI 搜尋服務有幾個常見的模式:
每個租用戶都使用專屬索引︰每個租用戶在與其他租用戶共用的搜尋服務內,都會有自己的索引。
每個租用戶都使用專屬服務:每個租用戶都有自己專用的 Azure AI 搜尋服務,可提供最高層級的資料和工作負載分隔。
兩者混合︰ 針對較大且較活躍的租用戶會指派專用服務,而針對較小的租用戶則會在共用服務內指派個別的索引。
模型 1:每個租使用者一個索引
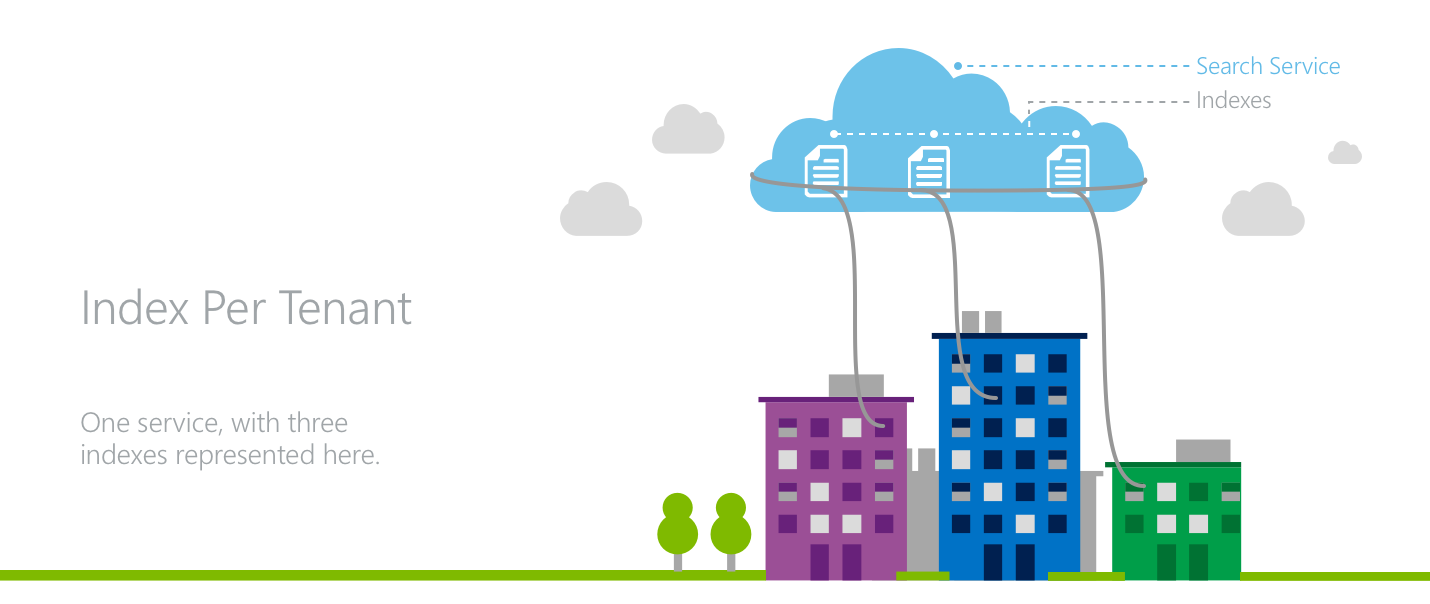
在「每個租用戶都使用專屬索引」模型中,多個租用戶會佔用單一的 Azure AI 搜尋服務,其中每個租用戶都有自己的索引。
租用戶可達到資料隔離的目的,因為所有搜尋要求和文件作業都是在 Azure AI 搜尋服務的索引層級發出。 在應用程式層中具有需求感知功能,可將各個租用戶的流量導向到適當的索引,同時也管理所有租用戶的服務層級資源。
「每個租用戶都使用專屬索引」模型有一個關鍵屬性,就是能夠讓應用程式開發人員在應用程式的租用戶之間過度訂閱搜尋服務的容量。 如果租用戶的工作負載分配不平均,系統可以將最佳的租用戶組合分散到搜尋服務的各個索引,以因應一些非常活躍、耗用大量資源的租用戶需求,而同時仍為為數眾多但較不活躍的租用戶提供服務。 取捨的結果是如果每個租用戶同時都非常活躍,此模型便無法處理。
「每個租用戶都使用專屬索引」模型提供了可變成本模型的基礎,其中需預先購置整個 Azure AI 搜尋服務,然後再接著填入租用戶。 這可讓您將未使用的容量指定給試用版和免費帳戶。
對遍佈全球的應用程式來說,「每個租用戶都使用專屬索引」模型可能不是最有效率的模型。 如果應用程式的租用戶遍佈全球,每個區域可能就都需要個別的服務,而可能導致在各個區域產生重複的成本。
Azure AI 搜尋服務同時考量到了個別索引規模的擴大和索引總數的增加。 如果選擇了適當的定價層,當服務內的個別索引在儲存體或流量方面成長得太大時,將可為整個搜尋服務新增資料分割和複本。
如果單一服務的索引總數成長得太大,則必須佈建另一個服務來容納新的租用戶。 如果在新增新的服務時,必須在搜尋服務之間移動索引,您將必須手動將來自索引的資料,從一個索引複製到另一個索引,因為 Azure AI 搜尋服務並未考量到索引移動的情況。
模型 2:每個租使用者一個服務
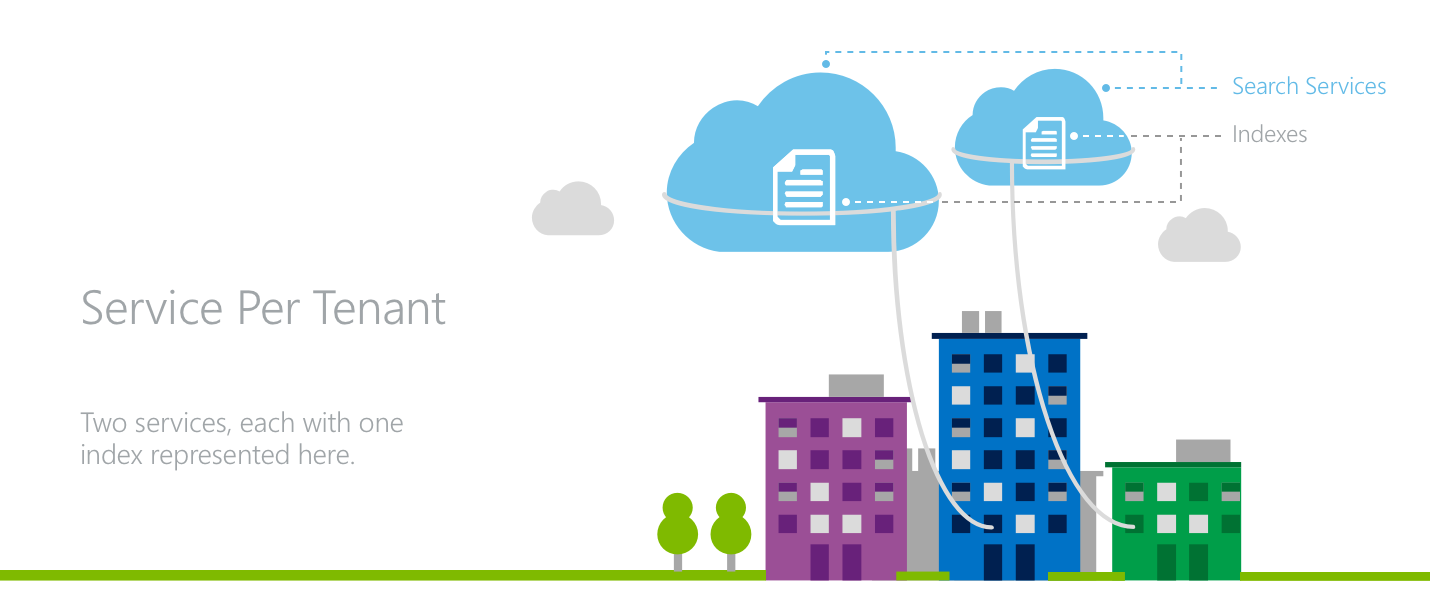
在「每個租用戶都使用專屬服務」架構中,每個租用戶都有自己的搜尋服務。
在此模型中,應用程式可針對其租用戶達到最大程度的隔離。 每項服務都有專用的儲存體和輸送量來處理搜尋要求。 每個租用戶都有 API 金鑰的個別擁有權。
如果應用程式的每個租用戶都具有較大的使用量,或是租用戶之間的工作負載變化小,則「每個租用戶都使用專屬服務」模型就是相當適合的選擇,因為資源不會在各個租用戶的工作負載之間共用。
每個租用戶都使用專屬服務模型也提供可預測、固定成本模型的優點。 整個搜尋服務在有租用戶填入之前,並不需要預先做任何投資,不過,每一租用戶的成本會高於「每個租用戶都使用專屬索引」模型。
對遍佈全球的應用程式來說,「每個租用戶都使用專屬服務」模型是一個有效率的選擇。 當租用戶的地理位置相當分散時,要在適當的區域中具有每個租用戶的服務,就相當簡單。
當個別租用戶的成長速度超出其服務所能處理的範圍時,調整此模式的挑戰便隨之產生。 Azure AI 搜尋服務目前不支援升級搜尋服務的定價層,因此所有資料都將必須手動複製到新的服務。
模型 3:混合式
建立多租用戶模型的另一種模式是將「每個租用戶都使用專屬索引」與「每個租用戶都使用專屬服務」策略混合。
透過混合這兩種模式,應用程式的最大租用戶便可以佔用專用服務,而為數眾多的較不活躍且較小的租用戶則可以在共用服務中佔用索引。 此模型可確保最大租用戶可以從服務一直享有高效能,同時又可協助保護較小的租用戶不受任何吵雜的鄰居干擾。
不過,實作此策略需要有遠見來預測哪些租用戶需要的是專用服務,而哪些租用戶需要的是共用服務中的索引。 當產生管理這兩個多租用戶模型的需求時,應用程式複雜性也隨之增加。
達到更精細的細微度
上述用來在 Azure AI 搜尋服務中建立多租用戶案例模型的設計模式是假設一個一致的範圍,其中每個租用戶都是一個完整的應用程式執行個體。 不過,應用程式有時可能是處理許多較小的範圍。
如果「每個租用戶都使用專屬服務」和「每個租用戶都使用專屬索引」模型的範圍不夠小,您可以建立索引模型來達到更精細的細微程度。
若要讓單一索引針對不同的用戶端端點有不同的行為,您可以在索引中新增欄位,來為每個可能的用戶端指定特定的值。 每次用戶端呼叫 Azure AI 搜尋服務來查詢或修改索引時,來自用戶端應用程式的程式碼都會在查詢階段使用 Azure AI 搜尋服務的篩選功能,為該欄位指定適當的值。
此方法可用來實現個別使用者帳戶的功能、分隔權限等級,甚至是完全分隔應用程式。
注意
使用上述方法來設定單一索引,為多個租用戶提供服務,進而影響搜尋結果的相關性。 搜尋相關性分數是在索引層級範圍計算,而不是在租用戶層級範圍計算,因此所有租用戶的資料都會併入相關性分數的基礎統計資料 (例如詞彙頻率)。
下一步
對許多應用程式而言,Azure AI 搜尋服務都是吸引力十足的選擇。 評估多租用戶應用程式的各種設計模式時,請考量各種定價層和個別的服務限制,以便量身打造 Azure AI 搜尋服務來配合各種規模的應用程式工作負載和架構。