在 Azure AI 搜尋服務中針對向量搜尋解決方案對大型文件進行區塊化
將大型文件分割成較小的區塊,可協助您維持在內嵌模型的最大語彙基元輸入限制之下。 例如,Azure OpenAI (部分機器翻譯) 內嵌模型的輸入文字長度上限為 8,191 個語彙基元。 假設常用 OpenAI 模型的每個語彙基元是四個字元的文字,此上限相當於大約 6,000 字的文字。 如果您使用這些模型來產生內嵌,輸入文字必須維持在限制之下。 將內容分割成區塊可確保資料可以透過用於填入向量存放區和文字到向量查詢轉換的內嵌模型來處理。
本文說明進行資料區塊化的幾個方法。 只有在來源文件對於模型所強加的輸入大小上限來說太大時,才會需要進行區塊化。
注意
如果您使用向量搜尋 (部分機器翻譯) 的正式推出版本,資料區塊化和內嵌都需要外部程式碼,例如程式庫或自訂技能。 名為整合向量化 (部分機器翻譯) 的新功能 (其目前處於預覽狀態) 能提供內部資料區塊化和內嵌。 整合向量化相依於索引子、技能,文字分割技能,以及 AzureOpenAiEmbedding 技能 (或自訂技能)。 如果您無法使用預覽功能,本文中的範例會提供替代路徑。
常見的區塊化技術
以下是一些常見的區塊化技術,從最廣泛使用的方法開始:
固定大小的區塊:定義一個固定大小,其足以用於具語意意義的段落 (例如 200 個字),並允許某些重疊 (例如 10-15% 的內容) 可以產生良好的區塊作為內嵌向量產生器的輸入。
以內容為基礎的可變大小區塊:根據內容特性分割您的資料,例如句尾標點符號、行結尾標記,或使用自然語言處理 (NLP) 程式庫中的功能。 Markdown 語言結構也可以用來分割資料。
自訂或逐一查看上述其中一種技術。 例如,處理大型文件時,您可以使用可變大小的區塊,但也會將文件標題附加至文件中間的區塊,以防止內容遺失。
內容重疊考量
當您對資料進行區塊化時,在區塊之間重疊少量文字有助於保留內容。 建議您從大約 10% 的重疊開始。 例如,假設固定區塊大小為 256 個語彙基元,建議您從 25 個語彙基元的重疊開始測試。 實際重疊數量會因資料類型和特定使用案例而有所不同,但我們發現 10-15% 的重疊適用於許多案例。
對資料進行區塊化的因素
在對資料進行區塊化時,請考慮這些因素:
文件的形狀和密度。 如果您需要完整的文字或段落,使用能保留句子結構的較大區塊和可變區塊化可能會產生更好的結果。
使用者查詢:較大的區塊和重疊策略有助於保留以特定資訊為目標之查詢的內容和語意豐富性。
大型語言模型 (LLM) 具有適用於區塊大小的效能指導方針。 您必須設定最適合您使用之所有模型的區塊大小。 例如,如果您使用模型進行摘要和內嵌,請選擇適用於這兩者的最佳區塊大小。
區塊化如何融入工作流程
如果您有大型文件,您必須將區塊化步驟插入索引編製和查詢工作流程,以分割大型文字。 使用整合向量化 (預覽) (部分機器翻譯) 時,會套用使用文字分割技能 (部分機器翻譯) 的預設區塊化策略。 您也可以使用自訂技能 (部分機器翻譯) 來套用自訂區塊化策略。 提供區塊化的一些程式庫包括:
- LangChain 文字分隔器 (英文)
- 語意核心 TextChunker (英文)
大部分的程式庫都提供適用於固定大小、可變大小或這兩者之組合的常見區塊化技術。 您也可以指定重疊,其能在每個區塊中複製少量內容以進行內容保留。
區塊化範例
下列範例示範如何將區塊化策略套用至 NASA 的 Earth at Night 電子書 (英文) PDF 檔案:
- 文字分割技能 (預覽)
- LangChain
- 自訂技能 (部分機器翻譯)
文字分割技能範例
透過文字分割技能 (部分機器翻譯) 整合的資料區塊化目前處於公開預覽狀態。 針對此案例,請使用預覽 REST API 或 Azure SDK 搶鮮版 (Beta) 套件。
本節說明使用技能驅動方法和文字分割技能參數 (部分機器翻譯) 的內建資料區塊化。
您可以在 azure-search-vector-samples (英文) 存放庫上找到此範例的範例筆記本。
將 textSplitMode 設定為將內容分成較小的區塊:
pages(預設)。 區塊是由多個句子所組成。sentences. 區塊是由單一句子所組成。 構成「句子」的條件與語言有關。 在英文中,會使用標準句尾標點符號,例如.或!。 語言是由defaultLanguageCode參數所控制。
pages 參數會新增額外的參數:
maximumPageLength會定義每個區塊中的字元 1 數目上限。 文字分割器會避免分割句子,因此實際的字元計數會取決於內容。pageOverlapLength會定義要將前一頁結尾的多少個字元包括到下一頁的開頭。 若設定,這必須少於頁面長度上限的一半。maximumPagesToTake會定義要從文件擷取多少頁面/區塊。 預設值為 0,其表示要從文件擷取所有頁面或區塊。
1 字元不符合語彙基元 (部分機器翻譯) 的定義。 LLM 所測量的語彙基元數目可能會與文字分割技能所測量的字元大小不同。
下表示範所選擇的參數會如何影響 Earth at Night 電子書的總區塊計數:
textSplitMode |
maximumPageLength |
pageOverlapLength |
總區塊計數 |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N/A | N/A | 13361 |
使用 pages 的 textSplitMode 會導致大部分的區塊都具有接近 maximumPageLength 的總字元計數。 基於區塊內句子界限位置的差異,區塊字元計數會有所變化。 區塊語彙基元長度會因區塊內容的差異而有所不同。
下列長條圖顯示針對 Earth at Night 電子書,在使用 pages 的 textSplitMode、2000 的 maximumPageLength,以及 500 的 pageOverlapLength 時,針對 gpt-35-turbo (部分機器翻譯) 區塊字元長度的分布與區塊語彙基元長度的比較:
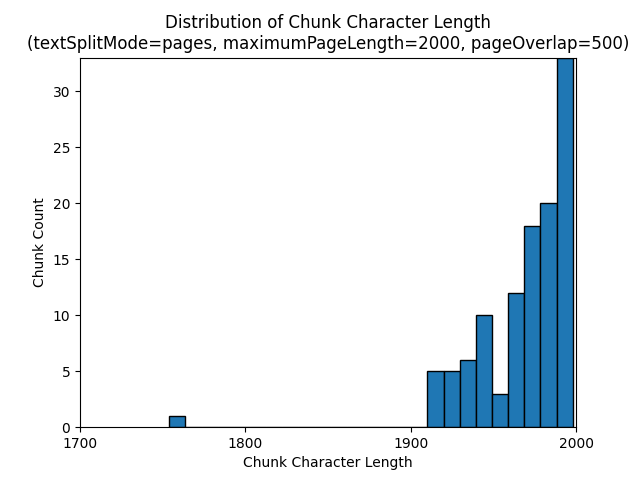
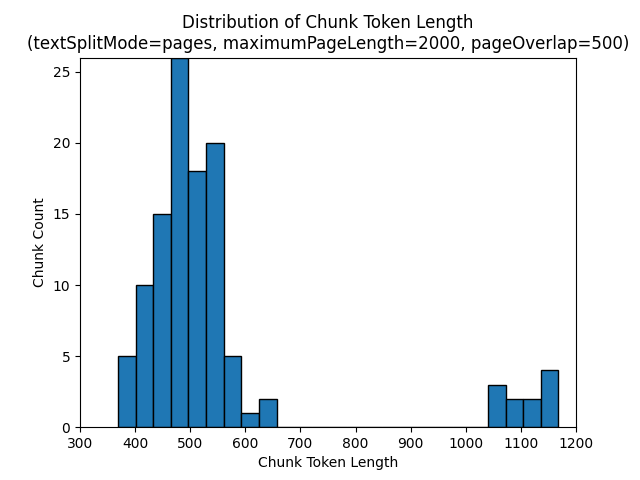
使用 textSplitMode 的 sentences 會產生由個別句子組成的大量區塊。 這些區塊明顯小於 pages 所產生的區塊,而區塊的語彙基元計數更符合字元計數。
下列長條圖顯示針對 Earth at Night 電子書,在使用 sentences 的 textSplitMode 時,針對 gpt-35-turbo (部分機器翻譯) 區塊字元長度的分布與區塊語彙基元長度的比較:
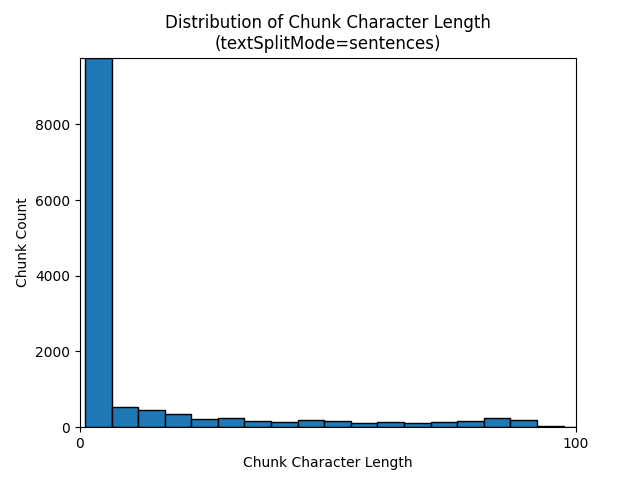
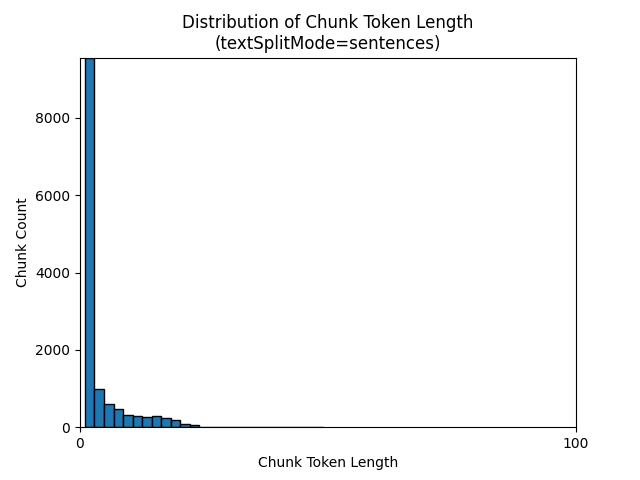
參數的最佳選擇取決於區塊的使用方式。 針對大部分的應用程式,建議從下列預設參數開始:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
LangChain 資料區塊化範例
LangChain 提供文件載入器和文字分隔器。 此範例示範如何載入 PDF、取得語彙基元計數,以及設定文字分隔器。 取得語彙基元計數可協助您針對區塊調整大小做出明智的決策。
您可以在 azure-search-vector-samples (英文) 存放庫上找到此範例的範例筆記本。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
輸出指出 PDF 中有 200 份文件或頁面。
若要取得這些頁面的估計語彙基元計數,請使用 TikToken。
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
輸出指出沒有頁面有零個語彙基元,每個頁面的平均語彙基元長度為 189 個語彙基元,而任何頁面的語彙基元計數上限為 1,583 個。
了解平均和最大語彙基元大小可讓您取得設定區塊大小的見解。 雖然您可以使用 2000 個字元搭配 500 個字元重疊的標準建議,但在此情況下,基於範例文件的語彙基元計數,使用較低的字元數是比較合理的做法。 事實上,設定太大的重疊值可能會導致完全不會出現重疊。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
兩個連續區塊的輸出會顯示第一個區塊的文字重疊到第二個區塊。 我們已稍微編輯過輸出,以增加其可讀性。
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
自訂技能
固定大小的區塊化和內嵌產生範例 (英文) 示範使用 Azure OpenAI (部分機器翻譯) 內嵌模型進行區塊化和向量內嵌產生。 此範例使用進階技能存放庫 (英文) 中的 Azure AI 搜尋服務自訂技能 (部分機器翻譯) 來包裝區塊化步驟。
另請參閱
- 了解 Azure OpenAI 服務中的內嵌 (部分機器翻譯)
- 了解如何產生內嵌 (部分機器翻譯)
- 教學課程:探索 Azure OpenAI 服務內嵌和文件搜尋 (部分機器翻譯)
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應