查詢加速可讓應用程式和分析架構只擷取執行指定作業所需的數據,大幅優化數據處理。 這可減少取得所儲存數據的重要見解所需的時間和處理能力。
概觀
查詢加速接受篩選謂詞和數據列投影,使應用程式能夠在從磁碟讀取數據時篩選數據行和列。 只有符合述詞條件的數據會透過網路傳輸至應用程式。 這可降低網路等待時間和計算成本。
您可以使用 SQL 在查詢加速要求中指定資料行篩選條件和資料列投影。 要求只會處理一個檔案。 因此,不支援 SQL 的進階關係型功能,例如依匯總聯結和分組。 加速查詢支援 CSV 和 JSON 格式的數據作為每個請求的輸入。
查詢加速功能不僅限於 Data Lake Storage(已啟用階層命名空間的儲存帳戶)。 查詢加速功能與儲存帳戶中 未 啟用階層命名空間的 Blob 相容。 這表示當您處理已儲存為記憶體帳戶中 Blob 的數據時,可以達到相同的網路等待時間和計算成本。
如需如何在用戶端應用程式中使用查詢加速的範例,請參閱 使用 Azure Data Lake Storage 查詢加速來篩選數據。
數據流
下圖說明一般應用程式如何使用查詢加速來處理數據。
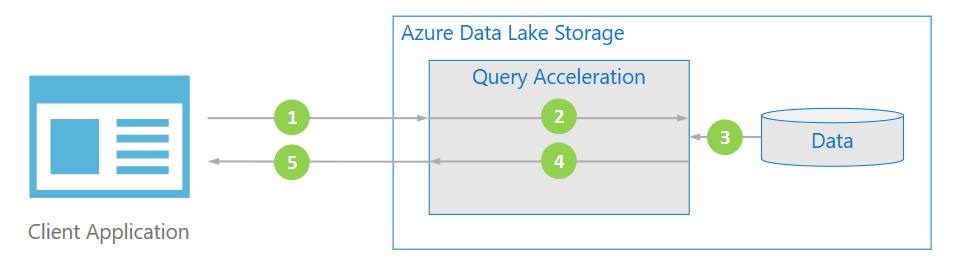
用戶端應用程式會藉由指定述詞和數據行投影來要求檔案數據。
查詢加速會解析指定的 SQL 查詢,並分配任務以解析和篩選數據。
處理器會從磁碟讀取數據、使用適當的格式剖析數據,然後套用指定的述詞和數據行投影來篩選數據。
查詢加速將回應資料分片結合起來,以串流的方式回傳至用戶端應用程式。
用戶端應用程式會接收並剖析串流回應。 應用程式不需要篩選任何其他數據,而且可以直接套用所需的計算或轉換。
以較低的成本提升效能
查詢加速可藉由減少應用程式傳輸和處理的數據量,來優化效能。
為了計算匯總值,應用程式通常會從檔案擷取 所有數據 ,然後在本機處理和篩選數據。 分析工作負載的輸入/輸出模式分析顯示,應用程式通常需要 20% 讀取的數據,才能執行任何指定的計算。 即使在套用分割剪枝等技術之後,此統計數據也是如此。 這意味著該數據的 80% 被不必要地透過網路傳輸、剖析和由應用程式篩選。 此模式是專為移除不必要的數據所設計,會產生顯著的計算成本。
雖然 Azure 具有領先業界的網路功能,但就輸送量和延遲而言,不需要透過該網路傳輸數據,對於應用程式效能而言仍成本高昂。 藉由在記憶體要求期間篩選掉不必要的數據,查詢加速會消除此成本。
此外,剖析和篩選不必要的數據所需的CPU負載需要您的應用程式布建更大的數目和較大的 VM,才能執行其工作。 藉由將此計算負載傳輸至查詢加速,應用程式可以大幅節省成本。
可受益於查詢加速的應用程式
查詢加速是專為分散式分析架構和數據處理應用程式所設計。
Apache Spark 和 Apache Hive 等分散式分析架構包含架構中的記憶體抽象層。 這些引擎也包含查詢優化器,可在判斷用戶查詢的最佳查詢計劃時,納入基礎 I/O 服務功能的知識。 這些架構正在逐步整合查詢加速功能。 因此,這些架構的使用者會看到改善的查詢延遲和較低的總擁有成本,而不需要對查詢進行任何變更。
查詢加速也是針對數據處理應用程式所設計。 這些類型的應用程式通常會執行大規模數據轉換,這些轉換可能不會直接導致分析深入解析,因此它們不一定會使用已建立的分散式分析架構。 這些應用程式通常與基礎記憶體服務有更直接的關係,因此它們可以直接受益於查詢加速等功能。
如需應用程式如何整合查詢加速的範例,請參閱 使用 Azure Data Lake Storage 查詢加速來篩選數據。
定價
由於 Azure Data Lake Storage 服務內的計算負載增加,使用查詢加速的定價模式與一般 Azure Data Lake Storage 交易模型不同。 查詢加速會針對掃描的數據量以及傳回給呼叫端的數據量收取成本。 如需詳細資訊,請參閱 Azure Data Lake Storage 定價。
儘管計費模式有所變更,查詢加速的定價方案旨在降低工作負載的總持有成本,因為能減少更昂貴的虛擬機器成本。