教學課程:在沒有程式代碼的情況下定型機器學習模型(已淘汰)
您可以使用 自動化機器學習定型的新機器學習模型,擴充 Spark 資料表中的資料。 在 Azure Synapse Analytics 中,您可以直接在工作區中選取 Spark 資料表,作為用來在無需程式碼體驗中建立機器學習模型的訓練資料集。
在本教學課程中,您將了解如何在 Synapse Studio 中使用無需程式碼體驗來定型機器學習模型。 Synapse Studio 是 Azure Synapse Analytics 的一項功能。
您會在 Azure Machine Learning 中使用自動化機器學習,而不是手動編碼體驗。 您所定型的模型類型取決於您嘗試解決的問題。 在本教學課程中,您將使用迴歸模型,從紐約市計程車資料集預測計程車的車資。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
警告
- 自 2023 年 9 月 29 日起,Azure Synapse 將會停止對 Spark 2.4 運行時間的官方支援。 在 2023 年 9 月 29 日之後,我們不會處理任何與 Spark 2.4 相關的支援票證。 Spark 2.4 的 Bug 或安全性修正不會有發行管線。 使用Spark 2.4後,支援截止日期會自行承擔風險。 由於潛在的安全性和功能考慮,我們強烈勸阻其繼續使用。
- 作為 Apache Spark 2.4 淘汰程式的一部分,我們想要通知您 Azure Synapse Analytics 中的 AutoML 也將已被取代。 這包括低程式代碼介面和用來透過程式代碼建立 AutoML 試用版的 API。
- 請注意,AutoML 功能是透過 Spark 2.4 運行時間獨佔提供的。
- 對於想要繼續使用 AutoML 功能的客戶,建議您將資料儲存到 Azure Data Lake 儲存體 Gen2 (ADLSg2) 帳戶。 您可以從該處順暢地透過 Azure 機器學習 (AzureML) 存取 AutoML 體驗。 如需此因應措施的詳細資訊,請參閱 這裡。
必要條件
- Azure Synapse Analytics 工作區。 確定其已將 Azure Data Lake Storage Gen2 儲存體帳戶設定為預設儲存體。 針對您使用的 Data Lake Storage Gen2 檔案系統,請確定您是儲存體 Blob 資料參與者。
- 在您 Azure Synapse Analytics 工作區中的 Apache Spark 集區 (2.4 版)。 如需詳細資料,請參閱快速入門:使用 Synapse Studio 建立無伺服器 Apache Spark 集區。
- Azure Synapse Analytics 工作區中的 Azure Machine Learning 連結服務。 如需詳細資料,請參閱快速入門:在 Azure Synapse Analytics 中建立新的 Azure Machine Learning 連結服務。
登入 Azure 入口網站
登入 Azure 入口網站。
為定型資料集建立 Spark 資料表
在本教學課程中,您需要使用 Spark 資料表。 下列筆記本會建立一個 Spark 資料表:
將筆記本匯入到 Synapse Studio。
![Azure Synapse Analytics 的螢幕快照,其中已醒目提示 [匯入] 選項。](media/tutorial-automl-wizard/tutorial-automl-wizard-00a.png)
選取要使用的 Spark 集區,然後選取 [全部執行]。 此步驟會從開啟的資料集取得紐約計程車資料,並將資料儲存至您的預設 Spark 資料庫。
![Azure Synapse Analytics 的螢幕快照,其中已醒目提示 [全部執行] 和 [Spark] 資料庫。](media/tutorial-automl-wizard/tutorial-automl-wizard-00b.png)
當筆記本執行完成之後,您會在預設 Spark 資料庫下看到新的 Spark 資料表。 從資料中,尋找名為 nyc_taxi 的資料表。

開啟自動化機器學習精靈
若要開啟精靈,請以滑鼠右鍵按一下您在上一個步驟中建立的 Spark 資料表。 然後,選取 [機器學習]>[定型新模型]。

選擇模型類型
根據您想了解的內容,選取實驗的機器學習模型類型。 因為您嘗試預測的值是數值 (計程車費),所以請在這裡選取 [迴歸]。 然後選取 [繼續]。

設定實驗
在 Azure Machine Learning 中提供建立自動化機器學習實驗執行的組態詳細資料。 此執行會定型多個模型。 來自成功執行的最佳模型會在 Azure Machine Learning 模型登錄中註冊。

Azure Machine Learning 工作區:建立自動化機器學習實驗執行時,必須要有 Azure Machine Learning 工作區。 您也需要使用連結服務,將 Azure Synapse Analytics 工作區連結至 Azure Machine Learning 工作區。 在滿足了所有的必要條件之後,您可以指定要用於此自動化執行的 Azure Machine Learning 工作區。
實驗名稱:指定實驗名稱。 當您提交自動化機器學習執行時,必須提供一個實驗名稱。 執行的資訊會儲存在 Azure Machine Learning 工作區的該實驗底下。 此體驗預設會建立新的實驗,並產生建議的名稱,但您也可以提供現有實驗的名稱。
最佳模型名稱:從自動化執行指定最佳模型的名稱。 最佳模型會使用此名稱,並在執行後將其自動儲存在 Azure Machine Learning 模型登錄中。 自動化機器學習執行會建立許多機器學習模型。 根據您將在稍後步驟中選取的主要度量,您可以比較這些模型並選出最佳模型。
目標資料行:這是將定型以進行預測的模型。 選擇資料集中的資料行,其中包含您要預測的資料。 針對本教學課程,選取數值資料行
fareAmount作為目標資料行。Spark 集區:指定要用於自動化實驗執行的 Spark 集區。 系統會在您指定的集區上執行計算。
Spark 組態詳細資料:除了 Spark 集區,您也可以選擇提供工作階段組態詳細資料。
選取繼續。
設定模型
如果您已在上一節中選取 [迴歸] 作為模型類型,則可使用下列組態 (這些也適用於 [分類] 模型類型):
主要度量:輸入計量來測量模型的執行效能。 您可以使用此計量,比較自動化執行中所建立的不同模型,並判斷哪一個模型最適合執行。
定型工作時間 (小時):指定實驗執行和定型模型的時間量上限,以小時為單位。 請注意,您也可以提供小於 1 的值 (例如 0.5)。
並行反覆運算次數上限:選擇平行執行的反覆運算次數上限。
ONNX 模型相容性:如果啟用此選項,自動化機器學習定型的模型會轉換成 ONNX 格式。 如果要在 Azure Synapse Analytics SQL 集區中使用模型評分,此項目特別相關。
這些設定都有您可以自訂的預設值。

啟動執行
完成所有必要組態之後,您就可以開始執行自動化。 您可以選擇直接建立執行,方法是選取 [建立執行] - 這會在沒有程式碼的情況下啟動執行。 或者,如果偏好使用程式碼,您可以選取 [在筆記本中開啟] - 這會開啟一個筆記本,其中包含建立執行的程式碼,讓您可以檢視程式碼,並自行啟動執行。
![[建立執行] 或 [在筆記本中開啟] 選項的螢幕快照。](media/tutorial-automl-wizard/tutorial-automl-wizard-configure-run-00c2.png)
注意
如果已在上一節中選取 [時間序列預測] 作為模型類型,您必須設定其他組態。 預測也不支援 ONNX 模型相容性。
直接建立執行
若要直接啟動自動化機器學習執行,請選取 [建立執行]。 您會到正在啟動執行的通知。 然後您會看到另一個指出成功的通知。 您也可以選取通知中的連結,檢查 Azure Machine Learning 中的狀態。

使用筆記本建立執行
選取 [在筆記本中開啟] 以產生筆記本。 這讓您有機會新增設定,或為您的自動化機器學習執行修改程式碼。 當您準備好要執行程式碼時,請選取 [全部執行]。
![筆記本的螢幕快照,其中已醒目提示 [全部執行]。](media/tutorial-automl-wizard/tutorial-automl-wizard-configure-run-00e.png)
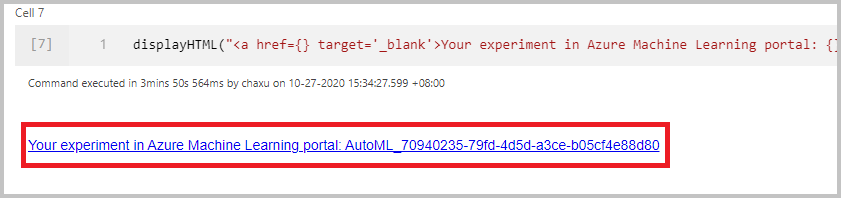
監視執行
在成功提交了執行之後,您會在筆記本輸出中看到 Azure Machine Learning 工作區中實驗執行的連結。 選取連結,以在 Azure Machine Learning 中監視您的自動化機器學習執行。
下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應