Apache Spark 顧問會分析由 Spark 執行的命令和程式代碼,並實時顯示筆記本中的作業建議。 Spark 建議程式具有內建模式,可協助使用者避免常見的錯誤、提供程式碼優化的建議、執行錯誤分析,以及找出失敗的根本原因。
內建建議
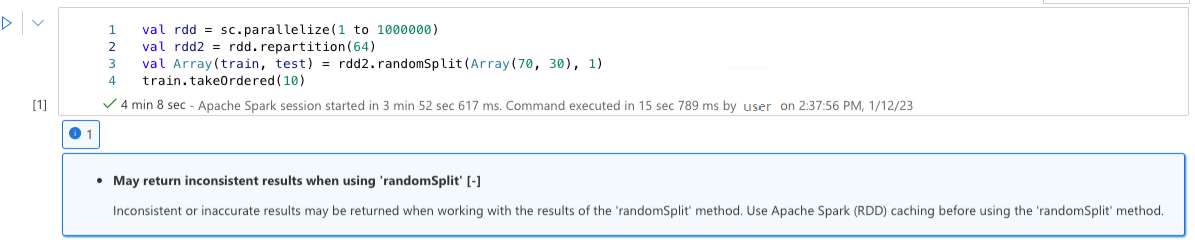
使用 『randomSplit』 時可能會傳回不一致的結果
使用 『randomSplit』 方法的結果時,可能會傳回不一致或不正確的結果。 使用 'randomSplit' 方法之前,請先使用 Apache Spark (RDD) 快取。
randomSplit() 方法相當於在資料框架上多次執行 sample(),每次抽樣時,會重新抓取資料、進行分區並在各個分區內排序資料框架。 跨分割區和排序順序的數據分佈對於 randomSplit() 和 sample() 都很重要。 如果在重新抓取數據時發生變更,可能會出現重複值或分割之間缺少值的情況,而且即便使用相同的種子,相同的樣本也可能產生不同的結果。
這些不一致可能不會在每次執行時發生,但為了完全消除它們,您可以快取您的數據框架、在某些欄位上重新分割或者套用像 groupBy 等聚合函數。
數據表/檢視名稱已在使用中
已建立的資料表與已存在的檢視同名,或者已建立的檢視與已存在的資料表同名。 當此名稱用於查詢或應用程式時,無論最先建立的是什麼,總是只傳回一個檢視。 若要避免衝突,請重新命名資料表或檢視。
無法辨識提示
選取的查詢包含無法辨識的提示。 確認提示拼字正確。
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
找不到指定的關聯名稱
找不到提示中指定的關聯性。 請確認關聯項是否拼寫正確,並且在提示範圍內可以存取。
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
查詢中的提示可防止套用另一個提示
選取的查詢包含防止套用另一個提示的提示。
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
啟用 'spark.advise.divisionExprConvertRule.enable' 以減少捨入錯誤傳播
此查詢包含具有 Double 類型的表達式。 建議您啟用組態 'spark.advise.divisionExprConvertRule.enable',這有助於減少除法表達式,並減少四捨五入錯誤傳播。
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
啟用 'spark.advise.nonEqJoinConvertRule.enable' 以改善查詢效能
此查詢因「或」條件導致聯結操作耗時。 建議您啟用組態 'spark.advise.nonEqJoinConvertRule.enable',這有助於將 “Or” 條件觸發的聯結轉換為 SMJ 或 BHJ 來加速此查詢。
使用小檔案壓縮優化 Delta 表
此查詢在一個有許多小檔案的 Delta 表格上。 若要改善查詢的效能,請在 Delta 表上執行 OPTIMIZE 命令。 如需詳細資訊,請參閱 這篇文章。
使用 ZOrder 優化 Delta 表格
此查詢位於 Delta 資料表上,且包含高度選擇性篩選。 若要改善查詢的效能,請在 Delta 表上執行 OPTIMIZE ZORDER BY 命令。 如需詳細資訊,請參閱 這篇文章。
用戶體驗
Apache Spark 諮詢工具會在 Notebook 單元格的即時輸出中顯示建議,提供資訊、警告及錯誤。
資訊
警告

錯誤

後續步驟
如需監視 Apache Spark 應用程式的詳細資訊,請參閱 使用 Synapse Studio 監視 Apache Spark 應用程式 一文。
如需建立筆記本的詳細資訊,請參閱 如何使用 Synapse 筆記本