最佳化 Azure Synapse Analytics 中的 Apache Spark 工作
了解如何特定工作負載最佳化 Apache Spark 叢集設定。 最常見的挑戰是記憶體壓力,因為不正確的設定 (特別是錯誤大小的執行程式)、長時間執行的作業,以及導致笛卡兒 (Cartesian) 作業的工作。 您可以使用適當的快取,並允許資料扭曲,以便作業加速執行。 為了達到最佳效能,必須監視和檢閱長時間執行而且耗用資源的 Spark 作業執行。
下列各節描述常見的 Spark 作業最佳化和建議。
選擇資料抽象
舊版 Spark 使用 RDD 來提取資料,Spark 1.3 和 1.6 分別導入了 DataFrame 和 DataSet。 請考慮下列的相對優勢:
- DataFrames
- 大部分情況下的最佳選擇。
- 透過 Catalyst 提供查詢最佳化。
- 整體階段程式碼產生。
- 直接記憶體存取。
- 低記憶體回收 (GC) 額外負荷。
- 不像 DataSets 適合開發人員使用,因為沒有任何編譯時間檢查或網域物件程式設計。
- DataSets
- 適合可接受效能影響的複雜 ETL 管線。
- 不適合效能影響可能相當大的彙總。
- 透過 Catalyst 提供查詢最佳化。
- 提供網域物件程式設計和編譯時間檢查,因此適合開發人員使用。
- 新增序列化/還原序列化額外負荷。
- 高 GC 額外負荷。
- 中斷整體階段程式碼產生。
- RDDs
- 除非您需要建立新的自訂 RDD,否則不需要使用 RDD。
- 沒有透過 Catalyst 的任何查詢最佳化。
- 沒有整體階段程式碼產生。
- 高 GC 額外負荷。
- 必須使用 Spark 1.x 舊版 API。
使用最佳的資料格式
Spark 支援許多格式,例如 csv、json、xml、parquet、orc 和 avro。 Spark 可以擴充來支援外部資料來源的多種格式,如需詳細資訊,請參閱 Apache Spark 封裝。
效能的最佳格式是 snappy 壓縮的 parquet,這是 Spark 2.x 的預設格式。 Parquet 以單欄式格式儲存資料,而且在 Spark 中高度最佳化。 此外,「snappy 壓縮」可能會產生比 gzip 壓縮更大的檔案。 由於這些檔案的可分割本質,因此可加快解壓縮速度。
使用快取
Spark 提供本身的原生快取機制,可透過 .persist()、.cache() 和 CACHE TABLE 等不同的方式使用。 對於較小型資料集,以及需要快取中繼結果的 ETL 管線,此原生快取相當有效。 不過,Spark 原生快取目前不適用於資料分割,因為快取的資料表不會保留分割資料。
有效率地使用記憶體
Spark 的運作方式是將資料放入記憶體,因此管理記憶體資源視 Spark 工作執行最佳化的重要層面。 有數種技術可以有效使用叢集的記憶體。
偏好較小的資料分割區,並在分割策略中考量資料大小、類型和發佈。
在 Synapse Spark (執行階段 3.1 或更高版本) 中,Kryo 資料序列化預設會啟用 Kryo 資料序列化。
您可以根據您的工作負載需求,使用 Spark 設定來自訂 kryoserializer 緩衝區大小:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")監視和微調 Spark 組態設定。
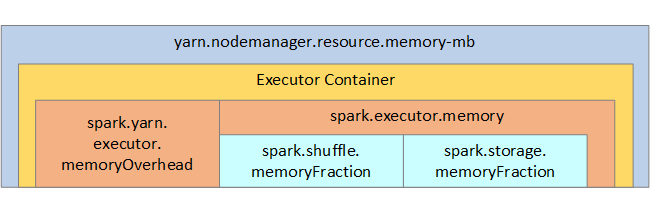
下圖顯示 Spark 記憶體結構,以及部分索引鍵執行程式記憶體參數,以供您參考。
Spark 記憶體考量
Azure Synapse 中的 Apache Spark 會使用 Apache Hadoop YARN,因此 YARN 會控制每個 Spark 節點上的所有容器使用的記憶體最大總和。 下圖顯示索引鍵物件及其關聯性。
若要處理「記憶體不足」訊息,請嘗試:
- 檢閱 DAG 管理重組。 以對應端減少、預先分割 (或貯體分類) 來源資料加以減少、最大化單一重組,並減少傳送的資料量。
- 偏好固定記憶體限制為
GroupByKey的ReduceByKey,這會提供彙總、視窗化和其他功能,但是有無限制的記憶體限制。 - 偏好對於執行程式或資料分割進行較多作業的
TreeReduce,而不偏好對於驅動程式進行所有作業的Reduce。 - 運用資料框架,而非運用較低層級 RDD 物件。
- 建立封裝動作的 ComplexTypes,例如「前 N 項」、各種彙總或視窗化作業。
最佳化資料序列化
Spark 作業相當分散,因此適當資料序列化對於達到最佳效能相當重要。 Spark 序列化有兩個選項:
- JAVA 序列化
- 預設為 Kryo 序列化。 其是較新的格式,可進行比 Java 更快且更精簡的序列化。 Kryo 會要求您註冊程式中的類別,而且不支援所有可序列化的類別。
使用貯體
貯體類似於資料分割,但是每個貯體都可以保存一組資料行值,而非其中一個值。 貯體適用於大量 (數百萬個以上) 值的資料分割,例如產品識別碼。 貯體是由資料列貯體索引鍵的雜湊所決定。 貯體資料表提供唯一的最佳化,因為這些資料表會儲存有關如何將資料表儲存和排序的中繼資料。
某些進階貯體功能包括:
- 根據貯體中繼資訊進行查詢最佳化。
- 最佳化彙總。
- 最佳化聯結。
您可以同時使用資料分割和貯體。
最佳化聯結和重組
如果在聯結或重組有緩慢的作業,原因可能是「資料扭曲」,也就是作業資料不對稱。 例如,對應作業可能需要 20 秒,但是執行連結或重組資料的作業需要數小時。 若要修正資料扭曲,您應該將整個索引鍵設定為 salt,或僅針對一部分的索引鍵使用「隔離 salt」。 如果您使用隔離 salt,應該進一步篩選來隔離對應聯結中一部分的 salt 索引鍵。 另一個選項是導入貯體資料行並先在貯體中預先彙總。
造成緩慢聯結的另一個因素可能是聯結類型。 Spark 預設使用 SortMerge 聯結類型。 這種聯結最適用於大型資料集,但是佔用大量運算資源,因為它必須先將左邊和右邊的資料排序,再合併資料。
Broadcast 聯結最適合使用較小的資料集,或聯結的一端遠小於另一端的情況。 這種聯結會將一端廣播到所有的執行程式,因此一般而言需要較多記憶體用於廣播。
您也可以設定 spark.sql.autoBroadcastJoinThreshold 在您的設定中變更聯結類型,也可以使用資料框架 API (dataframe.join(broadcast(df2))) 設定聯結提示。
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
如果您使用貯體資料表,則您有第三個聯結類型:Merge 聯結。 正確預先分割和預先排序的資料集會略過 SortMerge 聯結的昂貴排序階段。
聯結順序相當重要,尤其是更複雜的查詢。 先從大多數選擇性聯結開始。 此外,盡可能移動彙總之後會增加資料列數目的聯結。
若要管理笛卡兒聯結的平行處理,您可以加入巢狀結構、視窗化,而且可略過 Spark 作業中的一或多個步驟。
選取正確的執行程式大小
決定執行程式設定時,請考慮 Java 記憶體回收 (GC) 額外負荷。
減少執行程式大小的因素:
- 減少低於 32 GB 的堆積大小,讓 GC 額外負荷保持 < 10%。
- 減少核心數目,讓 GC 額外負荷保持 < 10%。
增加執行程式大小的因素:
- 減少執行程式之間的通訊額外負荷。
- 減少較大叢集上 (> 100個執行程式) 的執行程式 (N2) 之間的開啟連線數目。
- 增加堆積大小,以容納需要大量記憶體的工作。
- 選用:減少每個執行程式的記憶體額外負荷。
- 選用:超載使用 CPU 以增加使用率和並行。
依照一般經驗法則,選取執行程式大小時:
- 從每個執行程式 30 GB 開始,並分配可用的電腦核心。
- 增加較大叢集 (> 100 個執行程式) 的執行程式核心數目。
- 根據試用版執行和上述因素修改大小,例如 GC 額外負荷。
執行並行查詢時,請考慮下列各項:
- 從每個執行程式和所有電腦核心 30 GB 開始。
- 超載使用 CPU (大約延遲提升 30%) 來建立多個平行 Spark 應用程式。
- 將查詢分散到各平行應用程式。
- 根據試用版執行和上述因素修改大小,例如 GC 額外負荷。
藉由查看時間軸檢視、SQL 圖形、作業的統計資料等等,監視極端值的查詢效能或其他效能問題。 有時一或數個執行程式比其他執行程式慢,而且工作花較長的執行時間。 較大的叢集 (> 30 個節點) 通常會發生這種情況。 在此情況下,將工作分割為較多的工作,讓排程程式彌補緩慢的工作。
例如,應用程式中的核心數目至少是工作數目的兩倍。 您也可以使用 conf: spark.speculation = true 啟用工作的推測性執行。
最佳化作業執行
- 必要時進行快取,例如,如果您使用資料兩次,則快取資料。
- 將變數廣播到所有執行程式。 變數只會序列化一次,因此查閱更快。
- 使用驅動程式上的執行緒集區,會使許多工作的作業加快。
Spark 2.x 查詢效能的關鍵是 Tungsten 引擎,這取決於整體階段程式碼產生。 在某些情況下,可能會停用整體階段程式碼產生。
例如,如果您在彙總運算式中使用不可變類型 (string),會出現 SortAggregate 而非 HashAggregate。 例如,為了提升效能,請嘗試下列方法,然後重新啟用程式碼產生:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應