適用於: Azure Synapse Analytics 專用 SQL 集區
當使用者查詢專用 SQL 集區中的數據行存放區數據表時,優化器會檢查儲存在每個區段中的最小值和最大值。 查詢述詞界限外的區段不會從磁碟讀取到記憶體。 如果要讀取的區段數目及其大小總計很小,查詢可以更快完成。
注意
本文適用於 Azure Synapse Analytics 專用 SQL 集區。 如需 SQL Server 和其他 SQL 平臺中已排序數據行存放區索引的資訊,請參閱 使用已排序的叢集數據行存放區索引進行效能微調。
已排序與非已排序的叢集數據行存放區索引
根據預設,針對未建立索引選項的每個數據表,內部元件(索引產生器)會在其中建立非排序的叢集數據行存放區索引 (CCI)。 每個數據行中的數據都會壓縮成個別的CCI資料列群組區段。 每個區段的值範圍都有元數據,因此查詢執行期間不會從磁碟讀取超出查詢述詞界限的區段。 CCI 提供最高層級的數據壓縮,並減少要讀取的區段大小,以便查詢執行得更快。 不過,由於索引產生器在將數據壓縮成區段之前不會排序數據,因此可能會發生重疊值範圍的區段,導致查詢從磁碟讀取更多區段,而且需要較長的時間才能完成。
有序叢集資料行存放區索引透過啟用有效的區段排除,藉由略過大量不符合查詢述詞的有序資料,帶來更快的效能。 建立已排序的 CCI 時,專用 SQL 集區引擎會在索引產生器將現有數據壓縮成索引區段之前,依順序索引鍵排序記憶體中的現有數據。 透過已排序的數據,區段重迭會減少,讓查詢有更有效率的區段消除,因此效能較快,因為要從磁碟讀取的區段數目較小。 如果所有數據可以一次在記憶體中排序,則可以避免區段重疊。 由於數據倉儲中的大型數據表,此案例不會經常發生。
若要檢查資料列的區段範圍,請使用資料表名稱和資料行名稱執行下列命令:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
注意
在已排序的 CCI 數據表中,來自相同批次 DML 或數據載入作業的新數據會在該批次內排序,數據表中的所有數據都沒有任何全域排序。 用戶可以透過 REBUILD 已排序的 CCI 來整理數據表中的所有數據。 在專用 SQL 集區中,數據行存放區索引 REBUILD 是離線作業。 針對分割的資料表,重建一次只會處理一個分割。 正在重建的數據分割中的數據「離線」,且在重建完成該分割區之前無法使用。
查詢效能
查詢從已排序的CCI獲得效能取決於查詢模式、數據大小、數據排序方式、區段的實體結構,以及為查詢執行選擇的 DWU 和資源類別。 在設計已排序的CCI數據表時,用戶應該先檢閱所有這些因素,再選擇排序數據行。
具有所有這些模式的查詢通常在使用有序 CCI 時執行得更快。
- 查詢具有相等、不等或範圍述詞
- 謂詞欄位和已排序的CCI欄位相同。
在此範例中,數據表 T1 具有依Col_C、Col_B和Col_A順序排序的叢集數據行存放區索引。
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
查詢 1 和查詢 2 的效能比其他查詢更能從已排序的 CCI 中獲益,因為它們參考了所有已排序的 CCI 資料行。
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
數據載入效能
將數據載入已排序的 CCI 資料表的效能與分區資料表類似。 由於資料排序作業,將資料載入已排序 CCI 資料表可能會較載入非排序 CCI 資料表花費更長的時間,但之後查詢可利用已排序 CCI 使執行速度更快。
以下是將數據載入具有不同架構之數據表的效能比較範例。
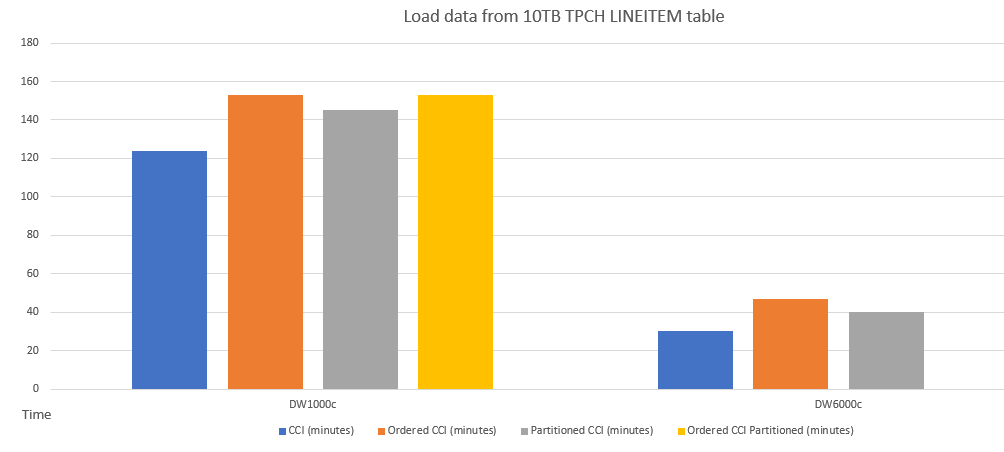
以下是CCI與已排序CCI之間的查詢效能比較範例。
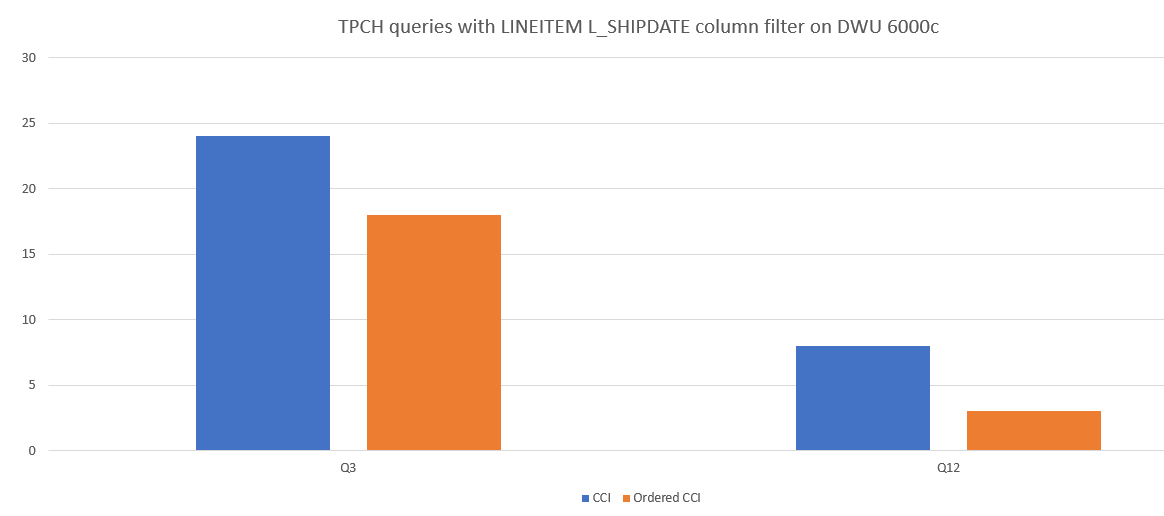
減少區段重迭
重疊區段的數目取決於要排序的數據大小、可用的記憶體,以及在建立有序 CCI 時平行處理的最大並行度 (MAXDOP) 設定。 下列策略可減少建立已排序 CCI 時的區段重疊。
在較高的 DWU 上使用
xlargerc資源類別,以便在索引生成器將數據壓縮成區段之前,允許使用更多記憶體進行數據排序。 一旦在索引區段中,就無法變更數據的實體位置。 區段內或跨區段沒有數據排序。使用
OPTION (MAXDOP = 1)建立已排序的CCI。 用於建立排序 CCI 的每個線程都在數據子集上運行,並在本地對其進行排序。 在不同線程排序的數據之間沒有全域排序。 使用平行線程可以縮短建立已排序 CCI 的時間,但會產生比使用單個線程更多的重疊區段。 使用單個線程作業可提供最高的壓縮品質。 例如:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
注意
目前,在 Azure Synapse Analytics 的專用 SQL 集區中,只有在使用 CREATE TABLE AS SELECT 命令建立已排序的 CCI 數據表時,才支援 MAXDOP 選項。 透過 CREATE INDEX 或 CREATE TABLE 命令建立已排序的CCI不支援 MAXDOP選項。 這項限制不適用於 SQL Server 2022 和更新版本,您可以在其中使用 CREATE INDEX 或 CREATE TABLE 命令指定 MAXDOP。
- 在將數據載入數據表之前,先依照排序索引鍵預先排序數據。
以下是經過排序的CCI表範例,根據上述建議,其區段沒有任何重疊。 在 DWU 1000c 資料庫中,使用 CTAS 從 20-GB Heap 資料表建立排序的 CCI 資料表,並使用 MAXDOP 1 和 xlargerc。 CCI 會在不包含重複值的 BIGINT 資料行上進行排序。
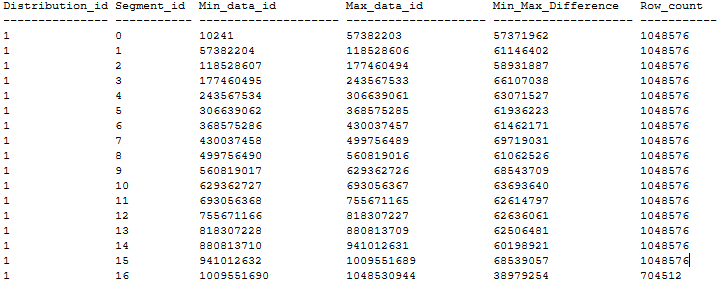
在大型數據表上建立已排序的CCI
建立已排序的 CCI 是離線作業。 對於沒有數據分割的數據表,在排序的CCI建立程式完成之前,使用者將無法存取數據。 針對分割資料表,由於引擎會逐一分割建立有序 CCI,使用者仍可存取未在進行有序 CCI 建立之分割中的資料。 您可以使用此選項,將大型資料表建立有序 CCI 期間的停機時間降到最低:
- 在目標大型數據表上建立分割區(稱為
Table_A)。 - 使用與
Table_A相同的資料表和分區架構,建立空的有序 CCI 表(稱為Table_B)。 - 將分割區從
Table_A切換為Table_B。 - 執行
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>以在Table_B上重建已切換的分割區。 - 針對中的每個
Table_A分割區重複步驟 3 和 4。 - 將所有分割區從
Table_A切換為Table_B並完成重建後,刪除Table_A,並將Table_B重新命名為Table_A。
提示
對於具有已排序 CCI 的專用 SQL 集區數據表,ALTER INDEX REBUILD 會使用 tempdb重新排序數據。 在重建作業期間監視 tempdb 。 如果您需要更多 tempdb 空間,請擴大集區。 索引重建完成後再縮回。
對於具有已排序 CCI 的專用 SQL 集區數據表,ALTER INDEX REORGANIZE 不會重新排序數據。 若要重新排序資料,請使用 ALTER INDEX REBUILD。
如需有序 CCI 維護的詳細資訊,請參閱 優化叢集資料欄存放區索引。
SQL Server 2022 功能的功能差異
SQL Server 2022 (16.x) 引進了已排序的叢集數據行存放區索引,類似於 Azure Synapse 專用 SQL 集區中的功能。
- 目前,只有 SQL Server 2022 (16.x) 和更新版本支援針對 string、binary 和 guid 資料類型,以及 scale 大於 2 的 datetimeoffset 資料類型之叢集資料行存放區增強區段排除功能。 先前,此區段排除適用於 numeric、date 和 time 資料類型,以及 scale 小於或等於 2 的 datetimeoffset 資料類型。
- 目前,只有 SQL Server 2022 (16.x) 和更新版本支援針對
LIKE述詞首碼的叢集資料行存放區 rowgroup 排除,例如column LIKE 'string%'。 LIKE 用於非前綴時,不支援片段刪除,例如column LIKE '%string'。
如需詳細資訊,請參閱 數據行存放區索引的新功能。
範例
A. 若要檢查有序資料行與順序序數:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. 若要變更資料行序數、從順序清單新增或移除資料行,或從 CCI 變更為有序 CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
下一步
- 如需更多開發秘訣,請參閱開發概觀。
- 資料行存放區索引:概觀
- 資料行存放區索引的最新動態
- 資料行存放區索引 - 設計指導
- 資料行存放區索引 - 查詢效能