Tip
Microsoft Fabric Data Warehouse 是一個企業規模的關聯式倉庫,建立在資料湖基礎上,具備未來準備架構、內建 AI 及新功能。 如果你是資料倉儲新手,建議先從Fabric Data Warehouse開始。 現有的 專用 SQL 工作負載可升級至 Fabric,以取得資料科學、即時分析與報告等多項新功能。
本文說明如何在 Azure Synapse Analytics 中估算和管理無伺服器 SQL 池的成本:
- 在發出查詢前,估計處理的資料量
- 使用成本控制功能來設定預算
請理解,Azure Synapse Analytics 中無伺服器 SQL 池的成本只是您 Azure 帳單每月費用的一部分。 如果你使用其他 Azure 服務,則會為你 Azure 訂閱中所有的 Azure 服務和資源(包括第三方服務)收費。 本文說明如何在 Azure Synapse Analytics 中規劃並管理無伺服器 SQL 池的成本。
已處理的數據
處理 中的資料是指系統在查詢執行時暫時儲存的資料量。 處理的資料包含以下量:
- 從儲存裝置讀取的資料量。 此金額包括:
- 讀取資料時讀取的資料。
- 讀取中繼資料時讀取的資料 (適用於包含中繼資料的檔案格式,例如 Parquet)。
- 中間結果中的數據量。 這些資料會在查詢執行時在節點間傳輸。 它包含資料傳輸到你的端點,以未壓縮格式呈現。
- 寫入儲存的資料量。 如果你用 CETAS 將結果集匯出到儲存,寫入的資料量會加到 SELECT 部分處理的資料量上。
從儲存體讀取檔案已高度最佳化。 此過程使用:
- 預先擷取可能會讓讀取的資料量增加一些額外負荷。 如果查詢能讀取整個檔案,那就沒有額外負擔。 如果檔案是部分讀取,例如在 TOP N 查詢中,則透過預取技術可以多讀取一些資料。
- 一款優化逗號分隔值(CSV)解析器。 如果你用 PARSER_VERSION='2.0' 來讀取 CSV 檔案,從儲存空間讀取的資料量會稍微增加。 優化過的 CSV 解析器會平行讀取檔案,且以相同大小的區塊進行。 區塊不一定包含完整的資料列。 為了確保所有列都被解析,優化後的 CSV 解析器也會讀取相鄰區塊的小型片段。 這個過程會增加一些額外的開銷。
統計資料
無伺服器 SQL 池查詢優化器依賴統計數據來產生最佳的查詢執行計畫。 你可以手動建立統計數據。 否則,無伺服器 SQL 池會自動產生它們。 無論哪種方式,統計資料都是透過執行一個獨立查詢來產生,該查詢會以指定的取樣率回傳特定欄位。 此查詢會處理相應的資料量。
如果你執行相同或任何其他需要統計資料的查詢,那麼統計資料會盡可能重複使用。 統計產生時不會處理額外的資料。
當為 Parquet 欄位建立統計資料時,僅從檔案讀取相關欄位。 當為 CSV 欄位建立統計資料時,會讀取並解析整個檔案。
四捨五入
每個查詢處理的資料量,都會無條件進位到最接近的 MB。 每個查詢至少處理 10 MB 的資料。
處理的資料不包含
- 伺服器層級的元資料(例如登入、角色和伺服器層級的憑證)。
- 你在端點建立的資料庫。 這些資料庫僅包含元資料(如使用者、角色、結構、視圖、內嵌資料表值函式(TVF)、儲存程序、資料庫範圍驗證憑證、外部資料來源、外部檔案格式及外部資料表)。
- 如果你使用結構推論,檔案片段會被讀取以推斷欄位名稱和資料型態,讀取的資料量會加到處理的資料量上。
- 資料定義語言(DDL)語句,除了 CREATE STATISTICS 語句,因為它是根據指定的樣本百分比處理儲存資料。
- 僅限元資料查詢。
減少處理資料量
你可以透過將資料分割並轉換成壓縮的欄位格式(如 Parquet),來優化每查詢處理的資料量並提升效能。
Examples
想像三張桌子。
- population_csv表由 5 TB 的 CSV 檔案支援。 檔案被組織成五個大小相等的欄位。
- population_parquet表與population_csv表的資料相同。 它有 1 TB 的 Parquet 檔案作為後盾。 此表格比前一個小,因為資料以Parquet格式壓縮。
- very_small_csv表以 100 KB 的 CSV 檔案作為後盾。
查詢 1:從 population_csv 中選擇總和(人口)
此查詢會讀取並解析整個檔案,以取得母體欄位的值。 節點處理此表格的片段,每個片段的人口總和會在節點間轉移。 最後的總金額會轉送到您的目的端。
此查詢會處理 5 TB 的資料,外加少量用於傳輸片段總和的額外負荷。
查詢 2:SELECT SUM(population) FROM population_parquet
當你查詢壓縮和欄式格式如 Parquet 時,讀取的資料比查詢 1 少。 你會看到這個結果,是因為無伺服器 SQL 池讀取的是單一壓縮欄位,而不是整個檔案。 在這種情況下,讀取量為 0.2 TB。 (五個大小相等的欄位各為 0.2 TB。)節點處理此表格的片段,每個片段的人口總和會在節點間轉移。 最後的總金額會轉送到您的目的端。
此查詢會處理 0.2 TB 的資料,外加少量用於傳輸片段總和的額外負荷。
查詢 3:從 population_parquet 中選擇 *
此查詢會讀取所有欄位,並將所有資料以未壓縮格式傳輸。 如果壓縮格式是 5:1,則查詢會處理 6 TB,因為它讀取 1 TB 並傳輸 5 TB 未壓縮資料。
查詢 4:從 very_small_csv 中選擇 COUNT(*)
此查詢會讀取整個檔案。 此資料表儲存檔案總大小為 100 KB。 節點處理此表格的片段,每個片段的總和會在節點間傳輸。 最後的總金額會轉送到您的目的端。
此查詢處理的資料量略超過 100 KB。 如本文進位一節所述,此查詢處理的資料量會無條件進位至 10 MB。
成本控制
無伺服器 SQL 池的成本控制功能讓你能設定處理資料的預算。 你可以設定一天、一週和一個月處理的資料預算(TB)。 同時,你也可以設定一個或多個預算。 要設定無伺服器 SQL 池的成本控制,可以使用 Synapse Studio 或 T-SQL。
在 Synapse Studio 中設定無伺服器 SQL 池的成本控制
要在 Synapse Studio 設定無伺服器 SQL 池的成本控制,請在左側選單中點選「管理項目」,然後在「分析池」中選擇 SQL 池項目。 當你滑停在無伺服器 SQL 池時,會注意到一個成本控制圖示——點擊這個圖示。
點擊成本控制圖示後,會出現側邊欄:
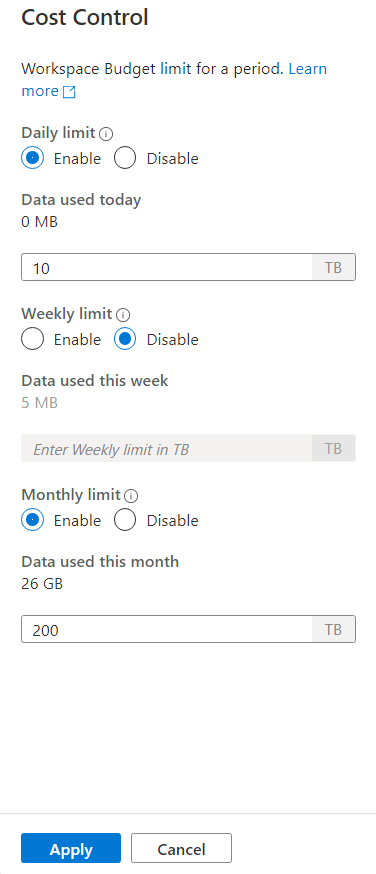
要設定一個或多個預算,請先點擊你想設定預算的啟用單選按鈕,然後在文字框中輸入整數值。 該數值的單位是TBs。 設定好想要的預算後,點擊側邊欄底部的套用按鈕。 就這樣,你的預算現在已經確定了。
在 T-SQL 中設定無伺服器 SQL 池的成本控制
要在 T-SQL 中設定無伺服器 SQL 池的成本控制,你需要執行以下一個或多個儲存程序。
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
要查看目前的配置,請執行以下 T-SQL 陳述句:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
要查看當天、一週或本月處理了多少資料,請執行以下 T-SQL 陳述句:
SELECT * FROM sys.dm_external_data_processed
超過成本控制所定義的限制
若查詢執行過程中超過任何限制,查詢不會被終止。
當超過限制時,新的查詢將被拒絕,並會跳出錯誤訊息,錯誤訊息包含該期間的詳細資料、該期限的定義限制及處理的資料。 例如,若執行新查詢,且每週限制設為 1 TB 且已超過,錯誤訊息將為:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
下一步
想了解如何優化你的查詢以提升效能,請參閱 無伺服器 SQL 池的最佳實務。