Tip
Microsoft Fabric Data Warehouse 是一個企業規模的關聯式倉庫,建立在資料湖基礎上,具備未來準備架構、內建 AI 及新功能。 如果你是資料倉儲新手,建議先從Fabric Data Warehouse開始。 現有的 專用 SQL 工作負載可升級至 Fabric,以取得資料科學、即時分析與報告等多項新功能。
在本教學課程中,您將瞭解如何使用現有的開放式數據集來執行探勘數據分析,而不需要任何記憶體設定。 您可以使用無伺服器 SQL 集區來合併不同的 Azure 開放資料集。 接著,您會在適用於 Azure Synapse Analytics 的 Synapse Studio 中將結果可視化。
在本教學課程中,您已:
- 存取內建無伺服器 SQL 集區
- 存取 Azure 開放數據集以使用教學課程數據
- 使用 SQL 執行基本數據分析
存取無伺服器 SQL 集區
每個工作區都隨附預先設定的無伺服器 SQL 集區,讓您能夠使用稱為 內建的 SQL 集區。 若要存取它:
- 開啟您的工作區,然後選取 [開發樞紐
]。 - 選取 [+新增資源] 按鈕。
- 選取 [SQL 指令碼]。
您可以使用此腳本來探索您的數據,而不需要保留 SQL 容量。
如尚未擁有 Azure 訂用帳戶,請在開始之前先建立免費帳戶。
存取教學課程數據
我們在本教學課程中使用的所有數據都儲存在記憶體帳戶 azureopendatastorage 中,其中保存 Azure 開放數據集以供在此教學課程中開啟使用。 只要工作區可以存取公用網路,您就可以直接從工作區執行所有腳本。
本教學課程使用紐約市 (NYC) 計程車的相關數據集:
- 取貨和下車日期和時間
- 取貨和下車位置
- 車程距離
- 明細票價
- 速率類型
- 付款類型
- 司機報告的乘客計數
OPENROWSET(BULK...) 函式可讓您存取 Azure 儲存體中的檔案。
[OPENROWSET](develop-openrowset.md) 讀取遠端數據源的內容,例如檔案,並以一組數據列傳回內容。
若要熟悉 NYC 計程車數據,請執行下列查詢:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
其他可存取數據集
同樣地,您可以使用下列查詢來查詢公用假日數據集:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
您也可以使用下列查詢來查詢天氣資料資料集:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
在這些資料集的描述中,您可以進一步了解各個資料行的意義:
自動架構推斷
由於數據會以 Parquet 檔案格式儲存,因此可以使用自動架構推斷。 您可以查詢數據,而不列出檔案中所有數據行的數據類型。 您也可以使用虛擬數據行機制和函 filepath 式來篩選出特定檔案子集。
注意
預設定序為 SQL_Latin1_General_CP1_CI_ASIf。 對於非預設定序,請考量區分大小寫。
如果您在指定資料行時建立具有區分大小寫定序的資料庫,請務必使用正確的數據行名稱。
欄位名稱 tpepPickupDateTime 是正確的,但在非預設排序規則中,tpeppickupdatetime 將無法運作。
時間序列、季節性和極端值分析
您可以使用下列查詢來摘要說明計程車車程的年數:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
下列片段顯示每年計程車乘車次數的結果:
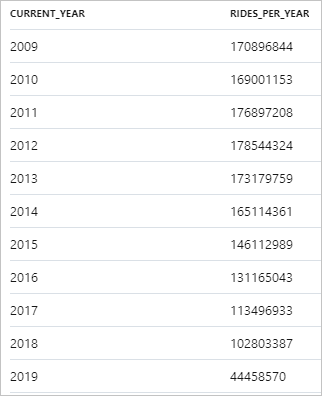
在 Synapse Studio 中,您可以將資料從 資料表 切換到 圖表 檢視,以進行可視化。 您可以選擇不同的圖表類型,例如 Area、 Bar、 Column、 Line、 Pie 和 Scatter。 在此案例中,請繪製資料行圖,並將類別資料行設定為 current_year:
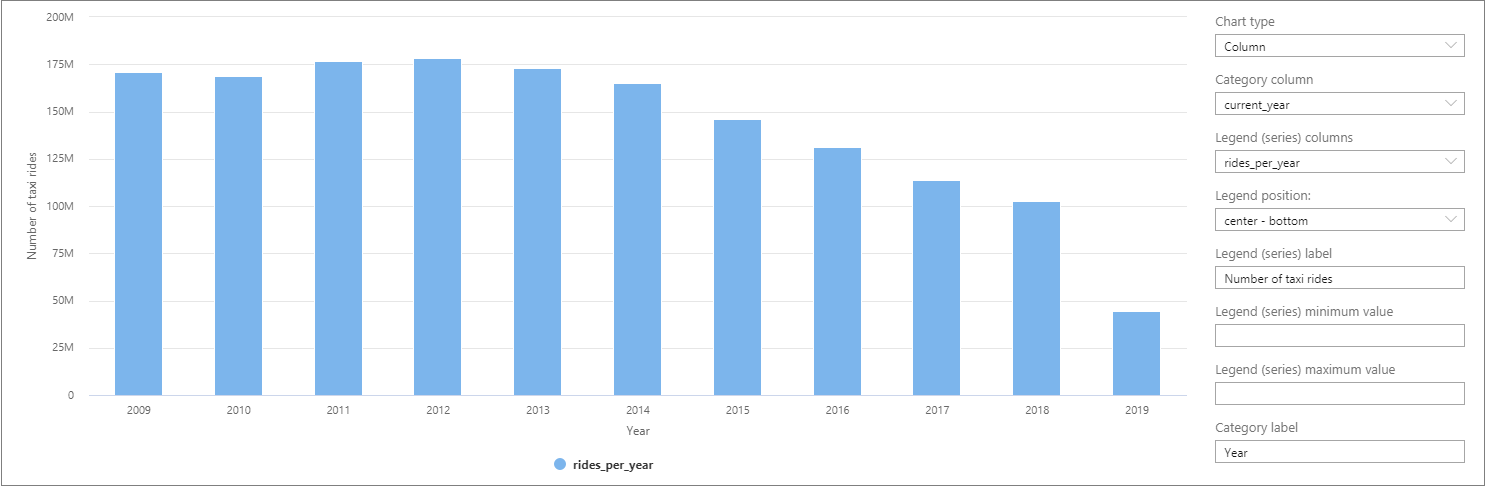
從這個可視化中,您可以看到車程數量年年降低的趨勢。 據推測,此下降是因為共乘公司近期人氣增加所致。
注意
撰寫本教學課程時,2019 年的數據不完整。 因此,當年的乘車次數大幅減少。
您可以將分析重點放在單一年份,例如 2016 年。 下列查詢會傳回該年度的每日車程數目:
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
下列代碼段顯示此查詢的結果:
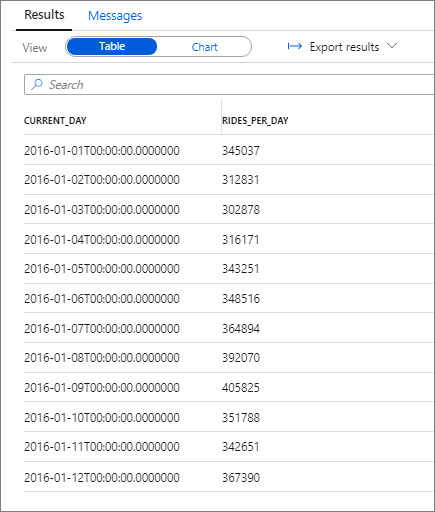
同樣地,您可以繪製 柱形圖,將 類別 列設定為 current_day,並將 圖例(數列) 列設定為 rides_per_day。
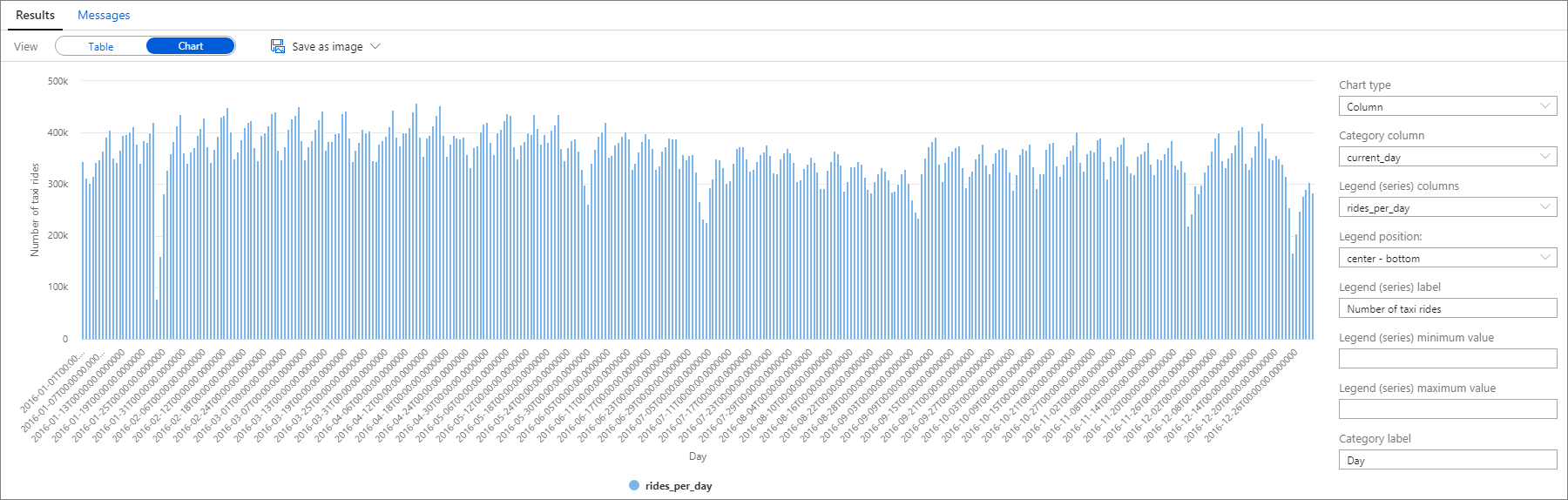
從繪圖圖中,您可以看到有每周模式,週六為尖峰日。 在夏季,由於假期,計程車車程較少。 此外,請注意,計程車搭乘數量出現顯著下降,但這些下降在發生的時間和原因上缺乏明顯的規律。
接下來,查看搭乘次數下降是否與公眾假期相關。 使用公用假日數據集聯結NYC計程車車程數據集,以檢查是否有相互關聯:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
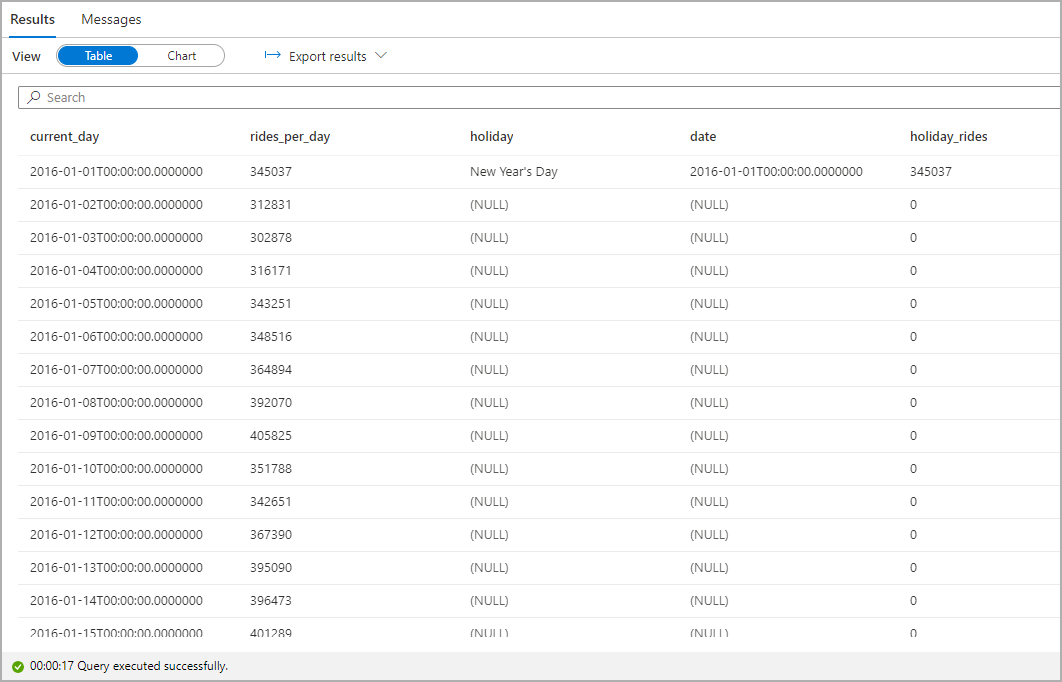
強調節假日期間的計程車搭乘數量。 為此,請選擇 current_day 為 類別 欄位,並選擇 rides_per_day 和 holiday_rides 作為 圖例(數列) 欄位。
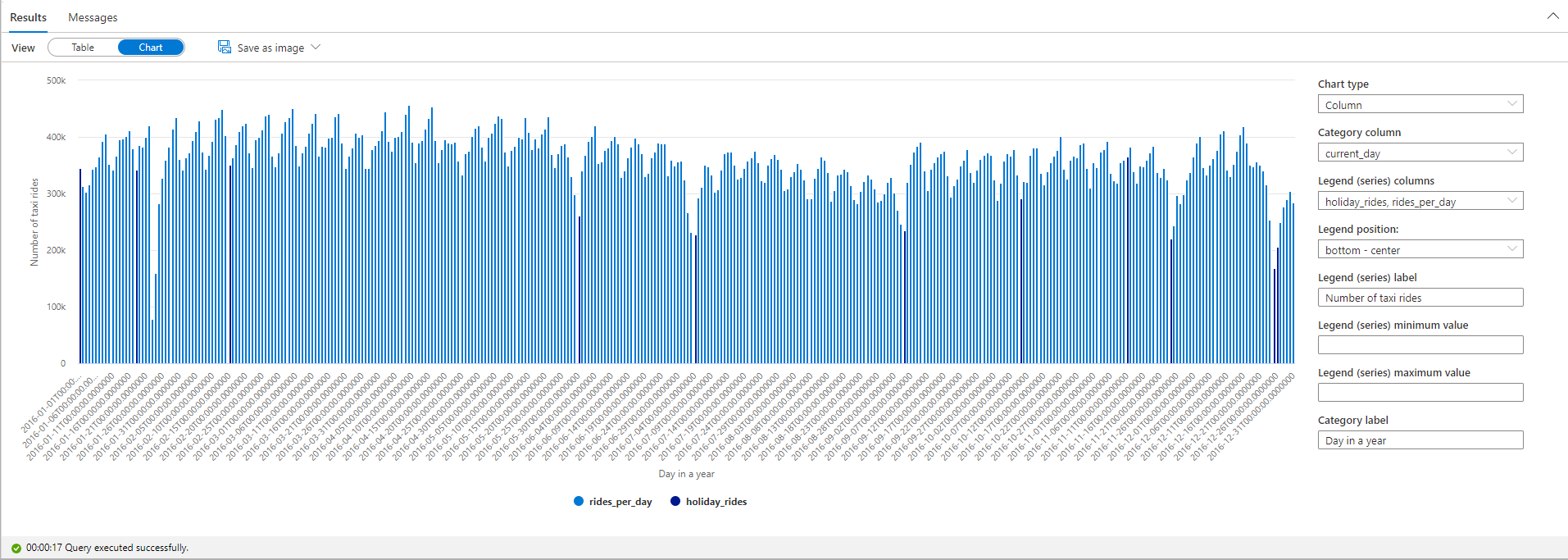
從繪圖圖中,您可以看到在公共假日期間計程車車程數目較低。 1月23日仍有一個無法解釋的大跌。 讓我們藉由查詢天氣數據數據集,檢查當天 NYC 的天氣:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

查詢結果顯示計程車搭乘數量的下降是因為:
- 那天在紐約,有一場暴風雪(~30釐米)。
- 天氣很冷(溫度低於零攝氏度)。
- 風很大(~每秒10米)。
本教學課程示範數據分析師如何快速執行探勘數據分析。 您可以使用無伺服器 SQL 集區結合不同的數據集,並使用 Azure Synapse Studio 將結果可視化。
相關內容
若要瞭解如何將無伺服器 SQL 集區連線到 Power BI Desktop 並建立報表,請參閱 將無伺服器 SQL 集區連線到 Power BI Desktop 並建立報表。
若要瞭解如何在無伺服器 SQL 集區中使用外部數據表,請參閱 搭配 Synapse SQL 使用外部數據表