在 SUSE Linux Enterprise Server 上的 Azure VM 實現 SAP HANA 的高可用性
若要在內部部署 SAP HANA 部署中建立高可用性,您可以使用 SAP HANA 系統複寫或共用儲存體。
在 Azure 虛擬機器 (VM) 上,Azure 上的 SAP HANA 系統複寫是目前唯一支援的高可用性功能。
SAP HANA 複寫包含一個主要節點以及至少一個次要節點。 對主要節點上資料的變更,會以同步或非同步方式複寫到次要節點。
本文說明如何部署和設定 VM、安裝叢集架構,以及安裝和設定 SAP HANA 系統複寫。
開始之前,請先閱讀下列 SAP 附註和文件:
- SAP 附註 1928533。 附註中包含:
- SAP 軟體部署支援的 Azure VM 大小清單。
- Azure VM 大小的重要容量資訊。
- 支援的 SAP 軟體、作業系統 (OS) 與資料庫組合。
- Microsoft Azure 上的 Windows 和 Linux 所需的 SAP 核心版本。
- SAP Note 2015553 列出 Azure 中 SAP 支援的 SAP 軟體部署先決條件。
- SAP 附註 2205917 包含針對 SUSE Linux Enterprise Server 12 (SLES 12) 建議的 OS 設定 (適用於 SAP 應用程式)。
- SAP 附註 2684254 包含針對 SUSE Linux Enterprise Server 15 (SLES 15) 建議的 OS 設定 (適用於 SAP 應用程式)。
- SAP 附註 2235581 包含 SAP HANA 支援的作業系統
- SAP 附註 2178632 包含針對 Azure 中的 SAP 回報的所有監視計量的相關詳細資訊。
- SAP 附註 2191498 包含 Azure 中的 Linux 所需的 SAP 主機代理程式版本。
- SAP 附註 2243692 包含 Azure 中的 Linux 適用 SAP 授權的相關資訊。
- SAP Note 1984787 包含 SUSE LINUX Enterprise Server 12 的一般資訊。
- SAP 附註 1999351 包含適用於 SAP 的 Azure 增強型監視延伸模組的其他疑難排解資訊。
- SAP 附註 401162 包含關於如何在設定 HANA 系統複寫時避免出現「位址已在使用中」錯誤的資訊。
- SAP 社群支援 Wiki 包含 Linux 所需的所有 SAP 附註。
- SAP HANA 認證 IaaS 平台。
- 適用於 Linux 上的 SAP 的 Azure 虛擬機器規劃和實作指南。
- Linux 上的 SAP 適用的 Azure 虛擬機器部署指南。
- 適用於 Linux 上的 SAP 的 Azure 虛擬機器 DBMS 部署 指南。
- 適用於 SAP 應用程式 15 的 SUSE Linux Enterprise Server 最佳做法指南和適用於 SAP 應用程式 12 的 SUSE Linux Enterprise Server 最佳做法指南:
- 設定 SAP HANA SR 效能最佳化基礎結構 (SLES for SAP Applications)。 本指南包含設定 SAP HANA 系統複寫以進行內部部署開發所需的所有資訊。 請使用此指南做為基礎。
- 設定 SAP HANA SR 成本最佳化基礎結構 (SLES for SAP Applications)。
規劃 SAP HANA 高可用性
若要達到高可用性,請在兩個 VM 上安裝 SAP HANA。 資料會使用 HANA 系統複寫進行複寫。
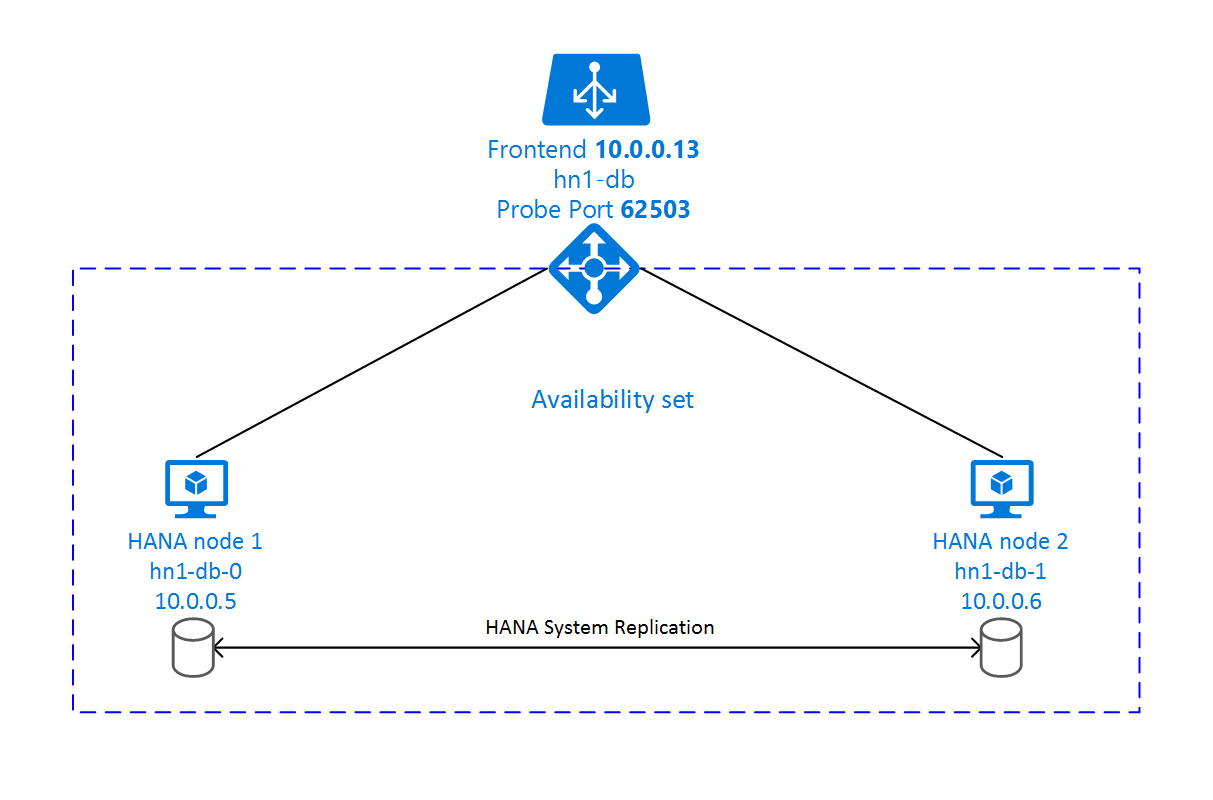
SAP HANA 系統複寫設定會使用專用的虛擬主機名稱和虛擬 IP 位址。 在 Azure 中,必須以負載平衡器部署虛擬 IP 位址。
上圖顯示具有下列設定的範例負載平衡器:
- 前端 IP 位址:10.0.0.13 (適用於 HN1-db)
- 探查連接埠:62503
準備基礎結構
SAP HANA 的資源代理程式隨附於 SUSE Linux Enterprise Server for SAP Applications 中。 Azure Marketplace 中提供適用於 SAP 應用程式 12 或 15 的 SUSE Linux Enterprise Server 映像。 您可以使用此映像來部署新的 VM。
透過 Azure 入口網站手動部署 Linux VM
本文件假設您已部署資源群組、Azure 虛擬網路和子網路。
為 SAP HANA 部署虛擬機器。 選擇支援 HANA 系統的適用 SLES 映像。 您可以在任一可用性選項中部署 VM - 虛擬機器擴展集、可用性區域或可用性設定組。
重要
請確定您選取的作業系統您計畫在部署使用的特定 VM 類型上已獲得 SAP HANA 認證。 您可以在 SAP Hana 認證 IaaS 平台中查閱 SAP Hana 認證的 VM 類型和作業系統版本。 請務必查閱 VM 類型的詳細資料,以取得 SAP Hana 針對特定 VM 類型支援的作業系統版本完整清單。
設定 Azure Load Balancer
在 VM 設定期間,您可以選擇在網路區段中建立或選取現有的負載平衡器。 請遵循下列步驟以設定 HANA 資料庫高可用性設定的標準負載平衡器。
- Azure 入口網站
- Azure CLI
- PowerShell
請遵循建立負載平衡器中的步驟,使用 Azure 入口網站為高可用性 SAP 系統設定標準負載平衡器。 在設定負載平衡器期間,請考慮下列幾點:
- 前端 IP 組態:建立前端 IP。 選取與資料庫虛擬機相同的虛擬網路和子網路名稱。
- 後端集區:建立後端集區並新增資料庫 VM。
- 輸入規則:建立負載平衡規則。 針對這兩個負載平衡規則,請遵循相同的步驟。
- 前端 IP 位址:選取前端 IP。
- 後端集區:選取後端集區。
- 高可用性連接埠:選取此選項。
- 通訊協定:選取 [TCP]。
- 健全狀態探查:使用下列詳細衣料建立健全狀態探查:
- 通訊協定:選取 [TCP]。
- 連接埠:例如,625<執行個體編號>。
- 間隔:輸入 5。
- 探查閾值:輸入 2。
- 閒置逾時 (分鐘):輸入 30。
- 啟用浮動 IP:選取此選項。
注意
未遵守健全狀態探查設定屬性 numberOfProbes,在入口網站中又名為狀況不良閾值。 若要控制連續探查成功或失敗的數目,請將屬性 probeThreshold 設定為 2。 目前無法使用 Azure 入口網站來設定此屬性,因此請使用 Azure CLI 或 PowerShell 命令。
如需 SAP Hana 所需連接埠的詳細資訊,請參閱 SAP Hana 租用戶資料庫指南的連線到租用戶資料庫一章,或 SAP 附註 2388694。
注意
當不具公用 IP 位址的 VM 放在 Azure Load Balancer 的內部 (沒有公用 IP 位址) 標準執行個體的後端集區時,預設設定為沒有輸出網際網路連線能力。 您可以採取額外的步驟,以允許路由傳送至公用端點。 如需關於如何實現輸出連線能力的詳細資料,請參閱在 SAP 高可用性案例中使用 Azure Standard Load Balancer 實現 VM 的公用端點連線能力。
重要
- 請勿在位於 Azure Load Balancer 後方的 Azure VM 上啟用 TCP 時間戳記。 啟用 TCP 時間戳記會導致健全狀態探查失敗。 將參數
net.ipv4.tcp_timestamps設定為0。 如需詳細資料,請參閱 Load Balancer 健全狀態探查或 SAP 附註 2382421。 - 若要防止 saptune 將手動設定
net.ipv4.tcp_timestamps值從0變更回1,請將 saptune 版本更新為 3.1.1 或更高版本。 如需詳細資訊,請參閱 saptune 3.1.1 – 我需要更新嗎?。
建立 Pacemaker 叢集
依照在 Azure 中的 SUSE Linux Enterprise Server 上設定 Pacemaker 中的步驟,建立此 HANA 伺服器的基本 Pacemaker 叢集。 您可以將相同的 Pacemaker 叢集用於 SAP HANA 和 SAP NetWeaver (A)SCS。
安裝 SAP Hana
本節中的步驟會使用下列前置詞:
- [A]:此步驟適用於所有節點。
- [1]:此步驟僅適用於節點 1。
- [2]:此步驟僅適用於 Pacemaker 叢集的節點 2。
將 <placeholders> 取代為 SAP HANA 安裝的值。
[A] 使用邏輯磁碟區管理員 (LVM) 設定磁碟配置。
我們建議針對儲存資料與記錄檔的磁碟區使用 LVM。 下列範例假設 VM 已連結四個用來建立兩個磁碟區的資料磁碟。
執行此指令以列出所有可用的磁碟:
/dev/disk/azure/scsi1/lun*範例輸出:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3為您想要使用的所有磁碟建立實體磁碟區:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3建立資料檔案的磁碟區群組。 一個磁碟區群組用於記錄檔,一個磁碟區群組用於 SAP HANA 的共用目錄:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3建立邏輯磁碟區。
當您使用
lvcreate卻未搭配-i參數時,會建立線性磁碟區。 建議建立等量磁碟區,以獲得更好的 I/O 效能。 將等量大小調整為 SAP HANA VM 儲存體設定中說明的值。-i引數應為基礎實體磁碟區的數目,-I引數則是等量大小。例如,若有兩個實體磁碟區用於資料磁碟區,
-i參數引數設定為 2,而資料磁碟區的等量大小為 256KiB。 有一個實體磁碟區作為記錄磁碟區,因此,記錄磁碟區命令中不需要明確使用-i或-I參數。重要
當您對每個資料磁碟區、記錄磁碟區或共用磁碟區使用多個實體磁碟區時,請使用
-i參數,並將其設定為基礎實體磁碟區的數目。 建立等量磁碟區時,請使用-I參數指定等量大小。如需建議的儲存體設定 (包括等量大小和磁碟數目),請參閱 SAP HANA VM 儲存體設定。
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_shared建立掛接目錄,並複製所有邏輯磁碟區的通用唯一識別碼 (UUID):
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkid編輯 /etc/fstab 檔案,以建立這三個邏輯磁碟區的
fstab項目:sudo vi /etc/fstab將以下這幾行插入 /etc/fstab 檔案中:
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2裝載新的磁碟區:
sudo mount -a
[A] 使用一般磁碟設定磁碟配置。
針對示範系統,您可以在一個磁碟上放置 HANA 資料與記錄檔。
在 /dev/disk/azure/scsi1/lun0 上建立磁碟分割,並使用 XFS 將其格式化:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstab將下列程式碼行插入 /etc/fstab 檔案:
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2建立目標目錄並裝載磁碟:
sudo mkdir /hana sudo mount -a
[A] 設定所有主機的主機名稱解析。
您可以使用 DNS 伺服器,或修改所有節點上的 /etc/hosts 檔案。 此範例說明如何使用 /etc/hosts 檔案。 請取代下列命令中的 IP 位址和主機名稱。
編輯 /etc/hosts 檔案:
sudo vi /etc/hosts將以下這幾行插入 /etc/hosts 檔案中。 變更 IP 位址和主機名稱以符合您的環境。
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] 安裝 SAP HANA,並遵循 SAP 的檔。
設定 SAP Hana 2.0 系統複寫
本節中的步驟會使用下列首碼:
- [A]:此步驟適用於所有節點。
- [1]:此步驟僅適用於節點 1。
- [2]:此步驟僅適用於 Pacemaker 叢集的節點 2。
將 <placeholders> 取代為 SAP HANA 安裝的值。
[1] 建立租用戶資料庫。
如果您使用 SAP HANA 2.0 或 SAP HANA MDC,請為您的 SAP NetWeaver 系統建立租用戶資料庫。
以 <HANA SID>adm 身分執行下列命令:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] 在第一個節點上設定系統複寫:
以 <HANA SID>adm 身分備份資料庫:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"然後,將系統公開金鑰基礎結構 (PKI) 檔案複製到次要站台:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/建立主要站台:
hdbnsutil -sr_enable --name=<site 1>[2] 在第二個節點上設定系統複寫:
註冊第二個節點以開始系統複寫。
以 <HANA SID>adm 身分執行下列命令:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
實作 HANA 資源代理程式
SUSE 為 Pacemaker 資源代理程式提供兩個不同的軟體套件來管理 SAP HANA。 軟體套件 SAPHanaSR 和 SAPHanaSR-angi 使用稍微不同的語法和參數,且不相容。 如需 SAPHanaSR 與 SAPHanaSR-angi 之間的詳細數據和差異,請參閱 SUSE 版本資訊與檔。 本文件涵蓋這兩個套件在個別索引標籤的個別區段中。
警告
請勿在已設定的叢集中,將 SAPHanaSR 取代為 SAPHanaSR-angi 套件。 從 SAPHanaSR 升級至 SAPHanaSR-angi 需要特定程式。
- [A] 安裝 SAP HANA 高可用性套件:
執行下列命令以安裝高可用性套件:
sudo zypper install SAPHanaSR
設定 SAP HANA HA/DR 提供者
SAP HANA HA/DR 提供者會將與叢集的整合優化,並在需要叢集故障轉移時改善偵測。 主要攔截腳本是 SAPHanaSR (適用於 SAPHanaSR 套件) / susHanaSR (適用於 SAPHanaSR-angi)。 強烈建議您設定 SAPHanaSR/susHanaSR Python 勾點。 針對 HANA 2.0 SPS 05 和更新版本,建議您同時實作 SAPHanaSR/susHanaSR 和 susChkSrv 攔截。
susChkSrv 勾點可擴充主要 SAPHanaSR/susHanaSR HA 提供者的功能。 它會在 HANA 程序 hdbindexserver 失效時運作。 當單一程序失效時,HANA 通常會嘗試加以重新啟動。 重新啟動索引伺服器流程可能需要較長時間,在此期間,HANA 資料庫無法回應。
實作 susChkSrv 後,會立即執行可設定的動作。 此動作會在設定的逾時期間觸發容錯移轉,而不是等待 hdbindexserver 程序在同一個節點上重新啟動。
- [A] 在兩個節點上停止 HANA。
以 sap-sid>adm 身分<執行下列程序代碼:
sapcontrol -nr <instance number> -function StopSystem
[A] 安裝 HANA 系統複寫勾點。 掛勾必須安裝在兩個 HANA 資料庫節點上。
提示
SAPHanaSR Python 勾點只能針對 HANA 2.0 實作。 SAPHanaSR 套件至少必須是 0.153 版。
SAPHanaSR-angi Python 攔截只能針對 HANA 2.0 SPS 05 和更新版本實作。
susChkSrv Python 攔截需要安裝 SAP HANA 2.0 SPS 05,且必須安裝 SAPHanaSR 版本0.161.1_BF或更新版本。[A] 在每個叢集節點上調整 global.ini 。
如果不符合 susChkSrv 勾點的需求,請從下列參數中移除整個
[ha_dr_provider_suschksrv]區塊。 您可以使用action_on_lost參數來調整susChkSrv的行為。 有效的值為 [ignore|stop|kill|fence]。[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = info如果您將參數路徑指向預設
/usr/share/SAPHanaSR位置,Python 攔截程式代碼會自動透過 OS 更新或套件更新進行更新。 HANA 會在下次重新啟動時使用勾點程式碼更新。 使用 之類的/hana/shared/myHooks選擇性路徑,您可以將 OS 更新與您使用的攔截版本分離。[A] 叢集需要 sap-sid>adm 的每個叢集節點上<的 sudoers 設定。 在此範例中,建立新檔案即可達成。
以 root 身分執行下列命令。 將 sid> 取代<為小寫 SAP 系統識別碼、<SID> 以大寫 SAP 系統識別碼和 <siteA/B> 取代為所選 HANA 網站名稱。
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
如需關於實作 SAP HANA 系統複寫勾點的詳細資訊,請參閱設定 HANA HA/DR 提供者。
[A] 在兩個節點上啟動 SAP Hana。 以 sap-sid>adm 身分<執行下列命令:
sapcontrol -nr <instance number> -function StartSystem[1] 驗證勾點安裝。 在作用中的 HANA 系統復寫網站上,以 sap-sid>adm 身分<執行下列命令:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] 確認 susChkSrv 勾點安裝。
在 HANA VM 上以 sap-sid>adm 身分<執行下列命令:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
建立 SAP HANA 叢集資源
- [1] 首先,建立 HANA 拓撲資源。
在其中一個 Pacemaker 叢集節點上執行下列命令:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] 接下來,建立 HANA 資源:
注意
本文參考了 Microsoft 不再使用的詞彙。 當這些字詞從軟體中移除時,我們會將其從本文中移除。
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] 繼續進行虛擬IP、預設值和條件約束的叢集資源。
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
重要
建議只有在完成整個容錯移轉測試後才可將 AUTOMATED_REGISTER 設定為 false,以防止失敗的主要執行個體自動註冊為次要執行個體。 順利完成容錯移轉測試後,請將 AUTOMATED_REGISTER 設定為 true,讓系統複寫在接管之後會自動繼續。
請確定叢集狀態為 OK,且所有資源皆已啟動。 資源在哪個節點上執行並不重要。
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
在 Pacemaker 叢集中設定 HANA 作用中/可讀系統複寫
在 SAP HANA 2.0 SPS 01 和更新版本中,SAP 允許 SAP HANA 系統複寫的作用中/可讀設定。 在此案例中,SAP HANA 系統複寫的次要系統可以主動用於讀取密集工作負載。
若要在叢集中支援此設定,您需要第二個虛擬 IP 位址,讓用戶端能夠存取次要可讀 SAP HANA 資料庫。 為了確保在接管之後仍可存取次要複寫站台,叢集需要將虛擬 IP 位址與 SAPHana 資源的次要站台一起移動。
本節說明在使用第二個虛擬 IP 位址的 SUSE 高可用性叢集中管理 HANA 作用中/可讀系統複寫所需的額外步驟。
繼續操作前,請確定您已完整設定用來管理 SAP HANA 資料庫的 SUSE 高可用性叢集,如先前幾節所述。
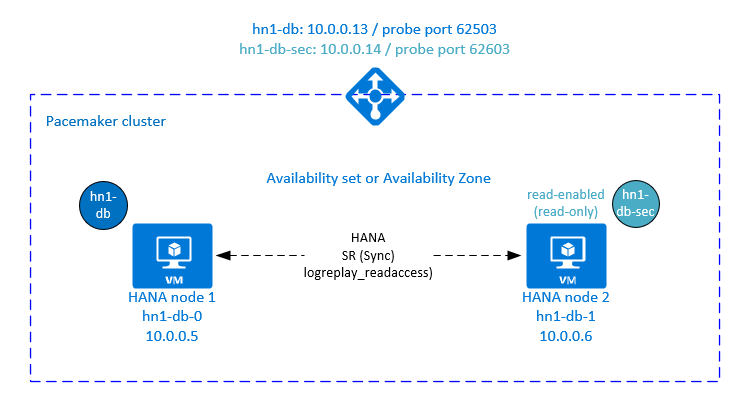
設定作用中/可讀系統複寫的負載平衡器
若要繼續進行額外的步驟來佈建第二個虛擬 IP,請確定您已設定 Azure Load Balancer,如透過 Azure 入口網站手動部署 Linux VM 中所述。
對於標準負載平衡器,請在您先前建立的相同負載平衡器上完成這些額外步驟。
- 建立第二個前端 IP 集區:
- 開啟負載平衡器,選取 [前端 IP 集區],然後選取 [新增]。
- 輸入第二個前端 IP 集區的名稱 (例如 hana-secondaryIP)。
- 將 [指派] 設為 [靜態],然後輸入 IP 位址 (例如 10.0.0.14)。
- 選取 [確定]。
- 建立新的前端 IP 集區之後,請記下前端 IP 位址。
- 建立健全狀態探查:
- 在負載平衡器中選取 [健全狀態探查],然後選取 [新增]。
- 輸入新的健全狀態探查名稱 (例如 hana-secondaryhp)。
- 選取 [TCP] 作為通訊協定,連接埠為 626< 執行個體號碼>。 讓 [間隔] 值保持設定為 5,而讓 [狀況不良閾值] 值保持設定為 2。
- 選取 [確定]。
- 建立負載平衡規則:
- 在負載平衡器中選取 [負載平衡規則],然後選取 [新增]。
- 輸入新的負載平衡器規則名稱 (例如 hana-secondarylb)。
- 選取您稍早建立的前端 IP 位址、後端集區及健全狀態探查 (例如,hana-secondaryIP、hana-backend 和 hana-secondaryhp)。
- 選取 [HA 連接埠]。
- 將閒置逾時增加為 30 分鐘。
- 確實啟用浮動 IP。
- 選取 [確定]。
設定啟用 HANA 作用中/可讀系統複寫
設定 HANA 系統複寫的步驟說明於設定 SAP HANA 2.0 系統複寫中。 如果您要部署可讀次要案例,當您在第二個節點上設定系統複寫時,請以 <HANA SID>adm 身分執行下列命令:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
新增次要虛擬 IP 位址資源
您可以使用下列命令,設定第二個虛擬 IP 和適當的共置條件約束:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
請確定叢集狀態為 OK,且所有資源皆已啟動。 第二個虛擬 IP 將會與 SAPHana 次要資源在次要站台上執行。
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
下一節將說明一組要執行的一般容錯移轉測試。
測試已設定了可讀次要伺服器的 HANA 叢集時的考量:
當您將
SAPHana_<HANA SID>_HDB<instance number>叢集資源移轉至hn1-db-1時,第二個虛擬 IP 會移至hn1-db-0。 如果您已設定AUTOMATED_REGISTER="false",且 HANA 系統複寫未自動註冊,則第二個虛擬 IP 會在hn1-db-0上執行,因為伺服器可供使用,且叢集服務處於線上狀態。當您測試伺服器損毀時,第二個虛擬 IP 資源 (
rsc_secip_<HANA SID>_HDB<instance number>) 和 Azure Load Balancer 連接埠 (rsc_secnc_<HANA SID>_HDB<instance number>) 會搭配主要虛擬 IP 資源在主要伺服器上執行。 當次要伺服器關閉時,連線至可讀 HANA 資料庫的應用程式,將會連線至主要 HANA 資料庫。 此為預期行為,因為當次要伺服器無法使用時,您不希望連線至可讀 HANA 資料庫的應用程式無法存取。當次要伺服器可供使用且叢集服務連線時,即使 HANA 系統複寫可能未註冊為次要伺服器,第二個虛擬 IP 和連接埠資源仍會自動移至次要伺服器。 在該伺服器上啟動叢集服務之前,請務必先將次要 HANA 資料庫註冊為可讀。 您可以設定 HANA 執行個體叢集資源,藉由設定參數
AUTOMATED_REGISTER="true"來自動註冊次要資料庫。在容錯移轉和後援期間,後續會使用第二個虛擬 IP 連線至 HANA 資料庫的應用程式現有的連線可能會中斷。
測試叢集設定
本節將說明如何測試您的設定。 每一個測試均假設您是以 root 身分登入的,且 SAP HANA 主要節點執行於 hn1-db-0 VM 上。
測試移轉
開始測試之前,請先確定 Pacemaker 沒有任何失敗的動作 (執行 crm_mon -r)、沒有非預期的位置條件約束 (例如,移轉測試的殘餘項目),且 HANA 處於同步狀態 (例如,藉由執行 SAPHanaSR-showAttr)。
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
您可以執行下列命令來移轉 SAP HANA 主要節點:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
叢集應該會將 SAP HANA 主要節點及包含虛擬 IP 位址的群組移轉至 hn1-db-1。
移轉完成後,crm_mon -r 輸出會如下列範例所示:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
使用 AUTOMATED_REGISTER="false"時,叢集不會重新啟動失敗的 HANA 資料庫,也不會對 上的 hn1-db-0新主資料庫進行註冊。 在此情況下,請執行下列命令,將 HANA 執行個體設定為次要:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
移轉會建立必須再次刪除的位置限制式:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
您也必須清除次要節點資源的狀態:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
使用 crm_mon -r 監視 HANA 資源的狀態。 當 HANA 在 hn1-db-0 上啟動時,輸出會如下列範例所示:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
封鎖網路通訊
開始測試之前的資源狀態:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
執行防火牆規則以封鎖其中一個節點上的通訊。
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
當叢集節點無法相互通訊時,就會有發生核心分裂情況的風險。 在這種情況下,叢集節點會嘗試同時相互隔離,進而導致隔離競爭。
設定隔離裝置時,建議您設定 pcmk_delay_max 屬性。 因此,發生核心分裂的情況時,叢集會針對每個節點上的隔離動作導入隨機延遲至 pcmk_delay_max 值。 系統會選取具有最短延遲的節點進行隔離。
此外,若要確保執行 HANA 主要節點的節點優先,並在核心分裂案例中贏得隔離競爭,建議您在叢集設定中設定 priority-fencing-delay 屬性。 藉由啟用 priority-fencing-delay 屬性,叢集將在隔離動作時出現額外延遲 (特別在裝載 HANA 主要資源的節點上),從而允許節點贏得隔離競爭。
執行下列命令以刪除防火牆規則。
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
測試 SBD 隔離
您可以終止 inquisitor 程序,以測試 SBD 的設定:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
<HANA SID>-db-<database 1> 叢集節點會重新開機。 Pacemaker 服務可能不會重新啟動。 請確實再次加以啟動。
測試手動容錯移轉
您可以藉由停止 hn1-db-0 節點上的 pacemaker 服務,來測試手動容錯移轉:
service pacemaker stop
容錯移轉之後,您可以再次啟動服務。 如果您設定 AUTOMATED_REGISTER="false",hn1-db-0 節點上的 SAP HANA 資源會無法以次要身分啟動。
在此情況下,請執行下列命令,將 HANA 執行個體設定為次要:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
SUSE 測試
重要
請確定您選取的作業系統已獲得 SAP 認證,可用於您預計要使用的特定 VM 類型上的 SAP HANA。 您可以在 SAP HANA 認證 IaaS 平台中查閱 SAP HANA 認證的 VM 類型和作業系統版本。 請務必查閱您要使用之 VM 類型的詳細資料,以取得 SAP HANA 針對特定 VM 類型支援的作業系統版本完整清單。
請根據您的案例,執行「SAP HANA SR 效能最佳化案例」指南或「SAP HANA SR 成本最佳化案例」指南中列出的所有測試案例。 您可以在 SLES for SAP 最佳做法中找到這些指南。
下列測試是 SAP HANA SR 效能最佳化案例 SUSE Linux Enterprise Server for SAP Applications 12 SP1 指南的測試描述複本。 如需最新版本,請閱讀指南本身。 請務必確定 HANA 處於同步狀態再開始測試,並確定 Pacemaker 的組態正確無誤。
在下列測試描述中,我們假設 PREFER_SITE_TAKEOVER="true" 和 AUTOMATED_REGISTER="false"。
注意
下列測試依設計會依序執行。 每個測試都取決於前個測試的結束狀態。
測試 1:在節點 1 上停止主要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在
hn1-db-0節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker 會偵測到已停止的 HANA 執行個體,並容錯移轉至其他節點。 容錯移轉完成後,由於 Pacemaker 不會自動將
hn1-db-0節點註冊為 HANA 次要節點,所以該節點上的 HANA 執行個體會停止。執行下列命令,將
hn1-db-0節點註冊為次要節點,並清除失敗的資源:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1測試 2:在節點 2 上停止主要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1在
hn1-db-1節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker 會偵測到已停止的 HANA 執行個體,並容錯移轉至其他節點。 容錯移轉完成後,由於 Pacemaker 不會自動將
hn1-db-1節點註冊為 HANA 次要節點,所以該節點上的 HANA 執行個體會停止。執行下列命令,將
hn1-db-1節點註冊為次要節點,並清除失敗的資源:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0測試 3:在節點 1 上損毀主要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在
hn1-db-0節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker 會偵測到已終止的 HANA 執行個體,並容錯移轉至其他節點。 容錯移轉完成後,由於 Pacemaker 不會自動將
hn1-db-0節點註冊為 HANA 次要節點,所以該節點上的 HANA 執行個體會停止。執行下列命令,將
hn1-db-0節點註冊為次要節點,並清除失敗的資源:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1測試 4:在節點 2 上損毀主要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1在
hn1-db-1節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker 會偵測到已終止的 HANA 執行個體,並容錯移轉至其他節點。 容錯移轉完成後,由於 Pacemaker 不會自動將
hn1-db-1節點註冊為 HANA 次要節點,所以該節點上的 HANA 執行個體會停止。執行下列命令,將
hn1-db-1節點註冊為次要節點,並清除失敗的資源。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0測試 5:損毀主要站台節點 (節點 1)。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在節點
hn1-db-0上以 root 身分執行下列命令:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker 會偵測到已終止的叢集節點,並將節點隔離。 節點隔離後,Pacemaker 會觸發 HANA 執行個體的接管作業。 當隔離的節點重新啟動時,Pacemaker 不會自動啟動。
執行下列命令以啟動 Pacemaker、清除
hn1-db-0節點的 SBD 訊息、將hn1-db-0節點註冊為次要節點,然後清除失敗的資源:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1測試 6:損毀次要站台節點 (節點 2)。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1在節點
hn1-db-1上以 root 身分執行下列命令:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker 會偵測到已終止的叢集節點,並將節點隔離。 節點隔離後,Pacemaker 會觸發 HANA 執行個體的接管作業。 當隔離的節點重新啟動時,Pacemaker 不會自動啟動。
執行下列命令以啟動 Pacemaker、清除
hn1-db-1節點的 SBD 訊息、將hn1-db-1節點註冊為次要節點,然後清除失敗的資源:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>測試 7:在節點 2 上停止次要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在
hn1-db-1節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker 會偵測到已停止的 HANA 執行個體,並在
hn1-db-1節點上將資源標記為已失敗。 Pacemaker 會自動重新啟動 HANA 執行個體。執行下列命令以清除失敗的狀態:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0測試 8:在節點 2 上損毀次要資料庫。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在
hn1-db-1節點上以 <hana sid>adm 身分執行下列命令:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker 會偵測到已終止的 HANA 執行個體,並在
hn1-db-1節點上將資源標記為已失敗。 執行下列命令以清除失敗的狀態。 然後,Pacemaker 會自動重新啟動 HANA 執行個體。# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0測試 9:損毀執行次要 HANA 資料庫的次要站台節點 (節點 2)。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在節點
hn1-db-1上以 root 身分執行下列命令:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker 會偵測到已終止的叢集節點,並將節點隔離。 當隔離的節點重新啟動時,Pacemaker 不會自動啟動。
執行下列命令以啟動 Pacemaker、清除
hn1-db-1節點的 SBD 訊息,然後清除失敗的資源:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0測試 10:損毀主要資料庫 indexserver
只有在您已如實作 HANA 資源代理程式中所述設定 susChkSrv 勾點時,此測試才相關。
開始測試之前的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0在節點
hn1-db-0上以 root 身分執行下列命令:hn1-db-0:~ # killall -9 hdbindexserver當索引伺服器終止時,susChkSrv 攔截會偵測事件,並觸發動作來隔離 『hn1-db-0』 節點並起始接管程式。
執行下列命令,將
hn1-db-0節點註冊為次要節點,並清除失敗的資源:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0測試完成之後的資源狀態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1您可以藉由造成次要節點上的索引伺服器損毀,來執行類似的測試案例。 當索引伺服器當機時,susChkSrv 攔截會辨識發生次數,並起始動作來隔離次要節點。