
就像已經开发了模式以協助應用程式中的程式碼佈局一樣,也有一些模式可以用來可靠地操作應用程式。 維護應用程式的三個實用模式已出現: 記錄、 監視和 警示。
使用記錄的時機
無論我們有多小心,應用程式在生產環境中幾乎總是以非預期的方式運作。 當使用者回報應用程式的問題時,能夠查看問題發生時應用程式的狀態會很有幫助。 擷取應用程式執行時所執行之相關信息的最嘗試和真實方式之一,就是讓應用程式寫下它正在執行的作業。 此過程被稱為記錄。 每當生產環境中發生失敗或問題時,目標應該是在非生產環境中重現發生失敗的情況。 備妥良好的記錄,可讓開發人員遵循藍圖,以便在可測試及實驗的環境中重複問題。
使用雲端原生應用程式進行記錄時的挑戰
在傳統應用程式中,記錄檔通常會儲存在本機計算機上。 事實上,在類似 Unix 的作系統上,有一個資料夾結構定義來保存任何記錄,通常位於 底下 /var/log。
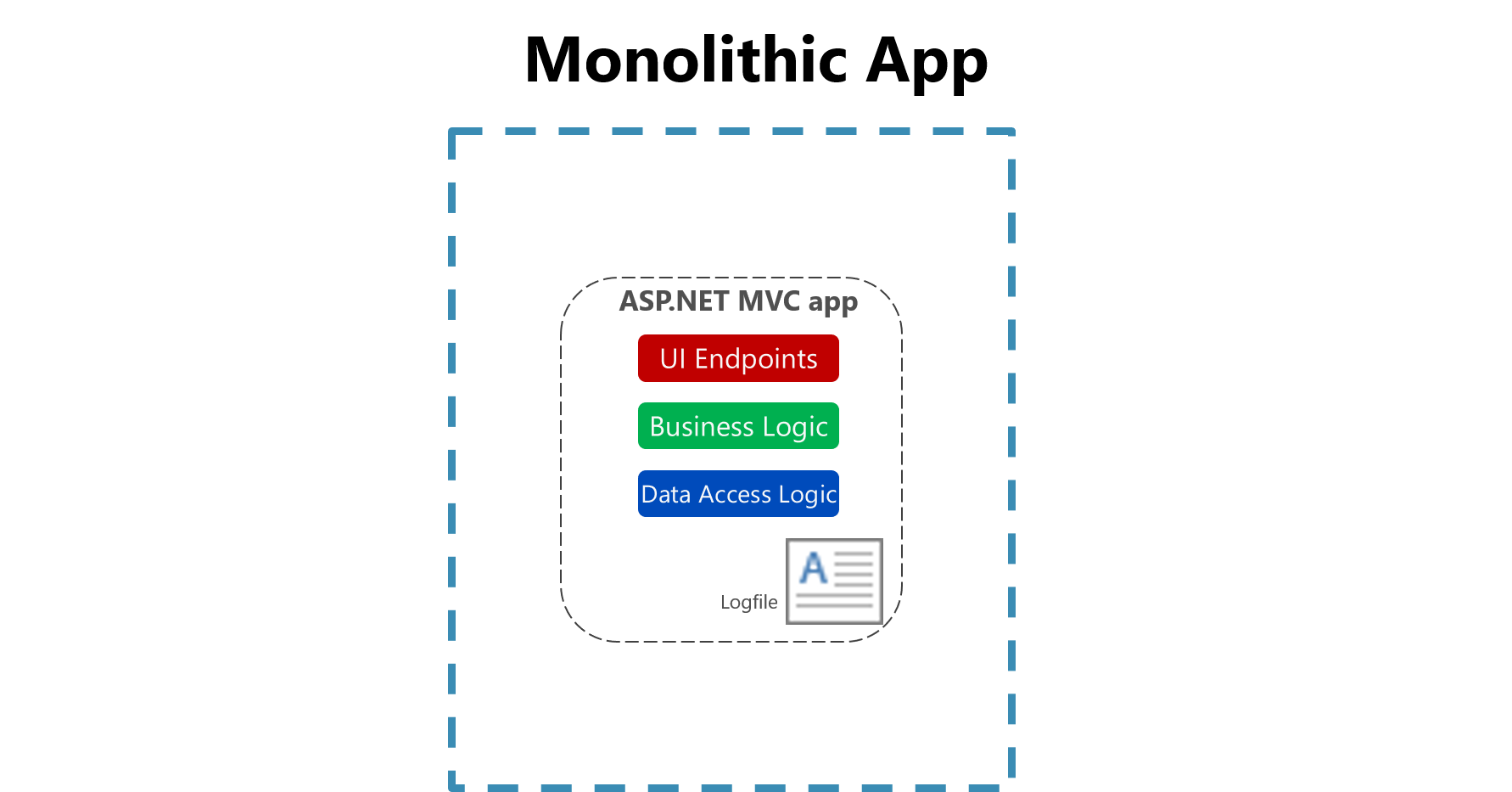 圖 7-1。 記錄至整合型應用程式中的檔案。
圖 7-1。 記錄至整合型應用程式中的檔案。
在雲端環境中,記錄到單一計算機上的一般檔案的效用大幅減少。 產生記錄的應用程式可能無法存取本機磁碟,或本機磁碟可能是高度暫時性的,因為容器會在實體機器周圍隨機顯示。 在跨越多個節點擴展單體應用程式時,即使是簡單的操作,仍然很難定位合適的檔案日誌。
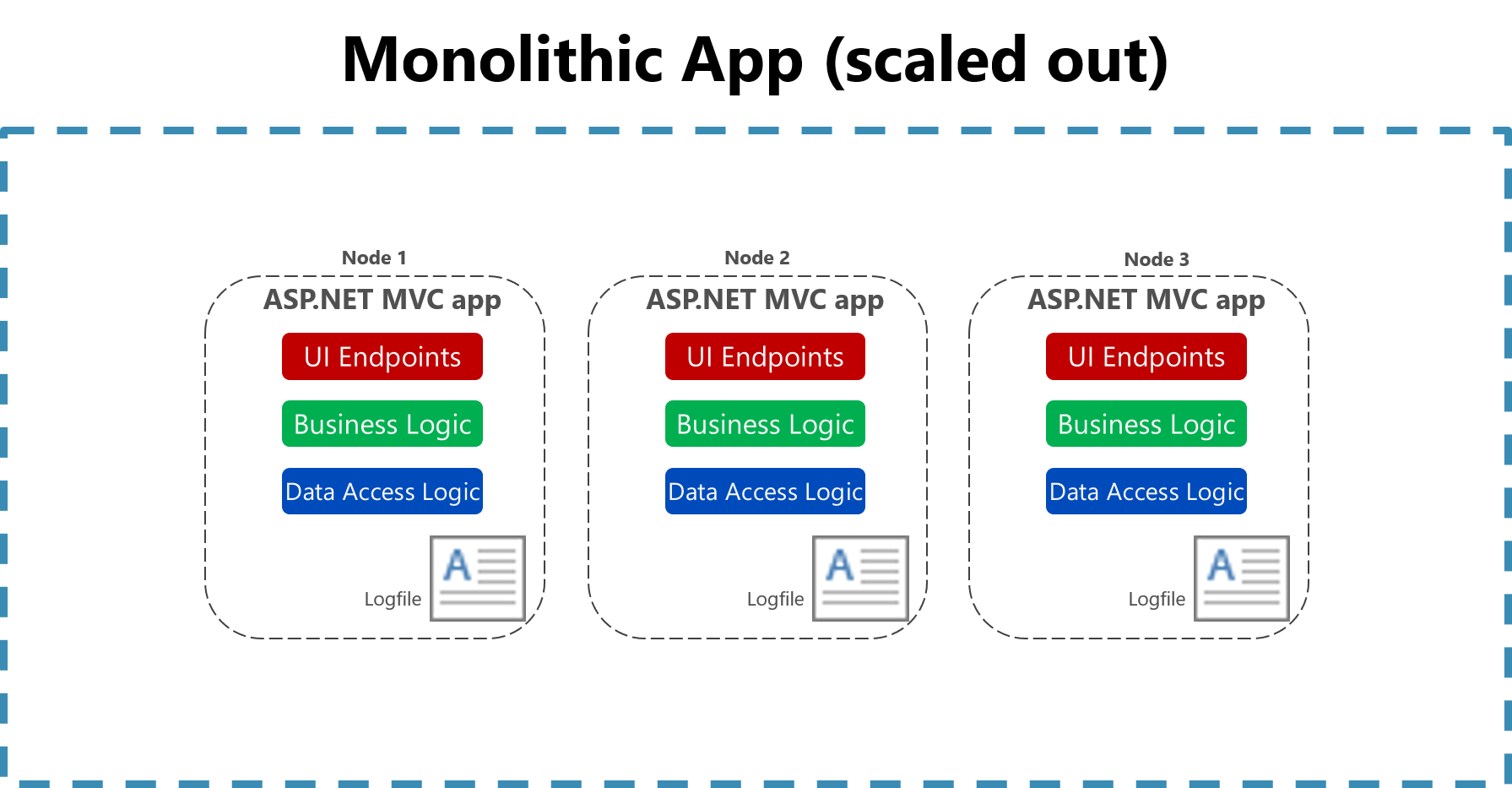 圖 7-2。 記錄至擴展的單體應用程式中的檔案。
圖 7-2。 記錄至擴展的單體應用程式中的檔案。
使用微服務架構開發的雲端原生應用程式也會對檔案型記錄器造成一些挑戰。 使用者要求現在可以跨越在不同計算機上執行的多個服務,而且可能包含無伺服器函式,完全無法存取本機文件系統。 要在這麼多服務和機器之間將來自使用者或會話的日誌相互關聯,將會極具挑戰性。
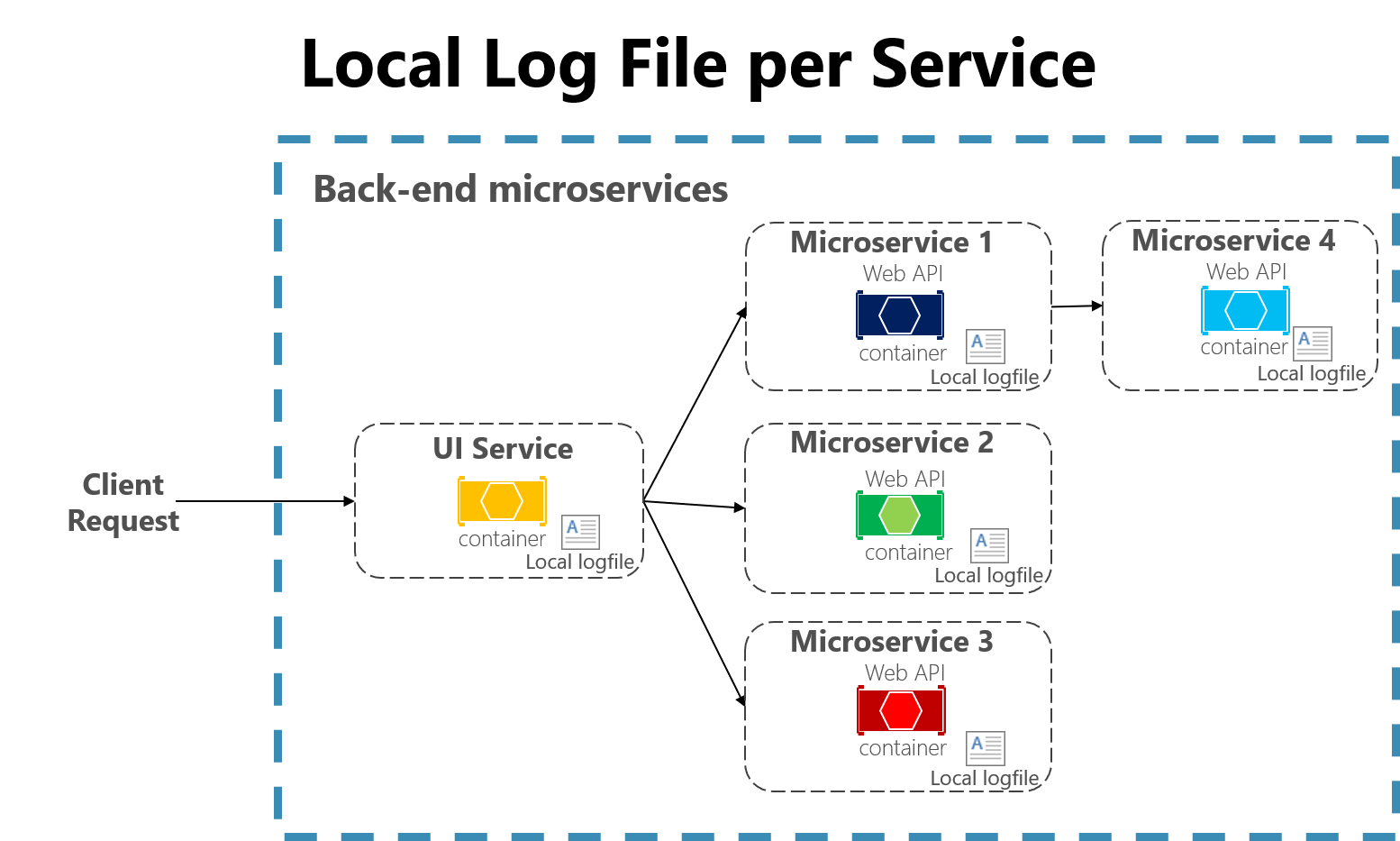 圖 7-3。 記錄至微服務應用程式中的本機檔案。
圖 7-3。 記錄至微服務應用程式中的本機檔案。
最後,某些雲端原生應用程式中的用戶數目很高。 假設每個使用者登入應用程式時會產生一百行記錄訊息。 單獨看來,這是可管理的,但當使用者數目超過100,000時,記錄量變得龐大,需要專業工具來支援記錄的有效使用。
在雲端原生應用程式中進行日誌記錄
每個程式設計語言都有允許寫入記錄的工具,通常寫入這些記錄的額外負荷很低。 許多日誌庫都提供不同類型的關鍵程度,可以在運行時進行調整。 例如, Serilog 連結庫 是適用於 .NET 的熱門結構化記錄連結庫,可提供下列記錄層級:
- 詳細資訊
- 除錯
- 資訊
- 警告
- 錯誤
- 致命
這些不同的日誌層級可提供更細緻的記錄。 當應用程式在生產環境中正常運作時,可能會設定為只記錄重要訊息。 當應用程式行為錯誤時,記錄層級可以增加,因此會收集更詳細的記錄檔。 這會平衡效能與可偵錯性。
記錄工具的高效能和詳細資訊的可調整性應該鼓勵開發人員經常記錄。 許多人偏好記錄每個方法的進入和結束模式。 這種方法聽起來可能有些多餘,但開發人員不常會希望減少記錄。 事實上,執行部署以添加記錄來針對有問題的方法並不少見。 寧可記錄過多,也不要記錄過少。 某些工具可用來自動提供這類記錄。
由於在雲端原生應用程式中使用檔案型記錄時遇到的挑戰,因此最好使用集中式記錄。 記錄會由應用程式收集,並運送至中央記錄應用程式,以編製索引並儲存記錄。 這個類別的系統每天可以擷取數十 GB 的記錄。
當建立橫跨多個服務的日誌時,遵循一些標準做法也會有所幫助。 例如,在冗長互動開始時產生相關性 ID,然後將其記錄在與該互動相關的每則訊息中,可以更輕鬆地搜尋所有相關訊息。 一個只需要尋找單一訊息,並擷取相互關聯標識碼來尋找所有相關訊息。 另一個範例是確保每個服務的記錄格式都相同,無論其使用的語言或記錄連結庫為何。 此標準化可讓讀取記錄更容易。 圖 7-4 示範微服務架構如何利用集中式記錄作為其工作流程的一部分。
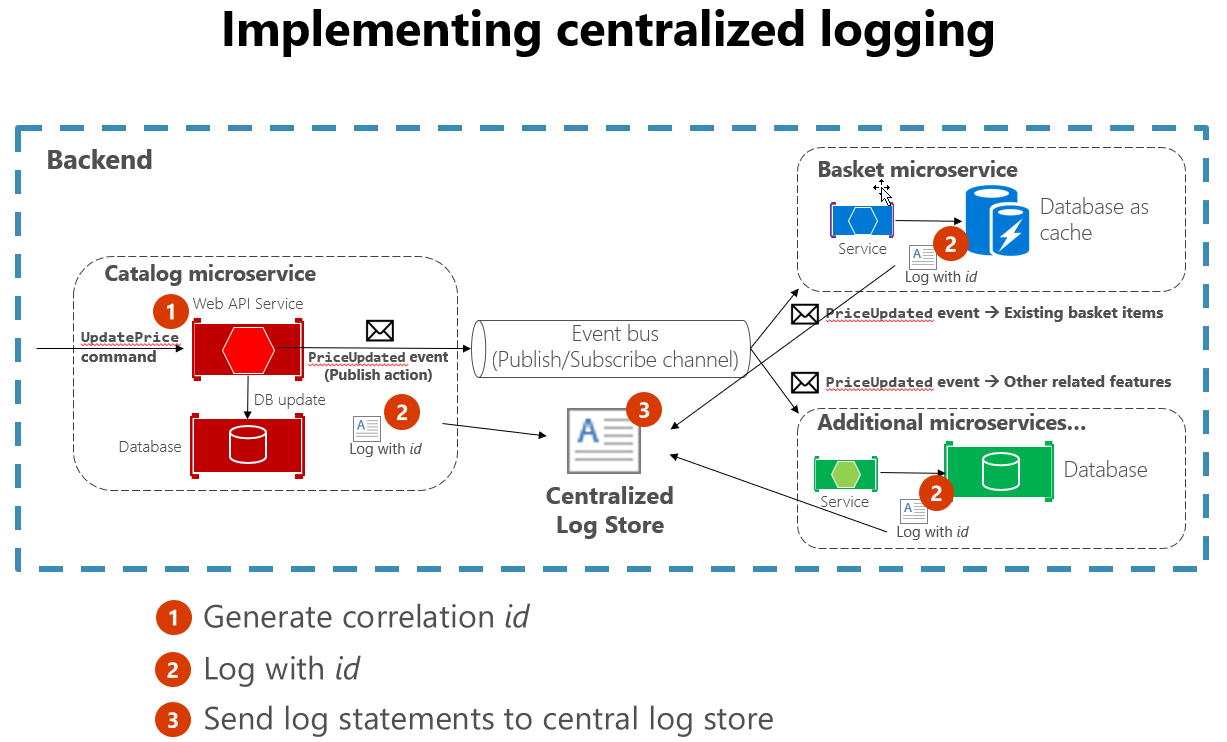 圖 7-4。 來自各種來源的記錄會內嵌到集中式記錄存放區。
圖 7-4。 來自各種來源的記錄會內嵌到集中式記錄存放區。
偵測和回應潛在應用程式健康情況問題的挑戰
某些應用程式並非任務關鍵。 也許它們只會在內部使用,而且發生問題時,使用者可以連絡負責的團隊,並重新啟動應用程式。 不過,客戶通常會對所取用的應用程式有較高的期望。 您應該知道應用程式在使用者 之前 發生問題,或是在使用者通知您之前發生問題。 否則,您可能是透過注意到社交媒體上的大量嘲弄您應用程式甚至是組織的貼文,才第一次察覺到問題的存在。
您可能需要考慮的一些案例包括:
- 應用程式中的一項服務會持續失敗並重新啟動,導致間歇性緩慢的回應。
- 在一天中的某個時間,應用程式的回應時間很慢。
- 在最近的部署之後,資料庫上的負載已增加三倍。
若正確執行,監測能讓您了解可能導致問題的狀況,使您能在造成任何重大使用者影響之前解決潛在問題。
監視雲端原生應用程式
某些集中式日誌系統除了純日誌之外,還會擔任額外的角色來收集其他遙測資料。 他們可以收集計量,例如執行資料庫查詢的時間、網頁伺服器的平均回應時間,甚至是作系統所報告的CPU負載平均值和記憶體壓力。 結合記錄,這些系統可以提供整個系統和應用程序節點健康情況的整體檢視。
您也可以從應用程式內手動提供監視工具的計量收集功能。 特別感興趣的商務流程,例如新用戶註冊或下單,可能會受到檢測,使其在中央監視系統中遞增計數器。 這個層面解鎖了監控工具,不僅可以監控應用程式的健康狀況,還能監控企業的健康狀況。
您可以在記錄匯總工具中建構查詢,以尋找特定統計數據或模式,然後可在自定義儀錶板上以圖形形式顯示。 小組經常會投資大型的掛牆式顯示器,該顯示器能夠輪流顯示與應用程式相關的統計數據。 如此一來,就能簡單地看出問題出現。
雲端原生監視工具提供即時遙測和深入解析應用程式,而不論應用程式是單一程式整合型應用程式還是分散式微服務架構。 其中包括可允許從應用程式收集數據的工具,以及查詢和顯示應用程式健康情況相關信息的工具。
回應雲端原生應用程式中重大問題的挑戰
如果您需要回應應用程式的問題,您需要某種方式來警示正確的人員。 這是第三個雲端原生應用程式可觀察性模式,取決於記錄和監視。 您的應用程式需要設置記錄功能,以便診斷問題,並在某些情況下整合到監控工具中。 它需要監視,才能在一個地方匯總應用程式計量和健康情況數據。 建立之後,就可以建立規則,當特定計量落在可接受的層級之外時,就會觸發警示。
一般而言,警示會分層在監視之上,讓某些條件觸發適當的警示,以通知小組成員緊急問題。 某些可能需要警示的案例包括:
- 其中一個應用程式服務在停機 1 分鐘後未回應。
- 您的應用程式傳回超過 1 個要求% 的 HTTP 回應失敗。
- 您的應用程式金鑰端點的平均回應時間超過 2000 毫秒。
雲端原生應用程式中的警示
您可以針對監視工具製作查詢,以尋找已知的失敗狀況。 例如,查詢可以在接收的記錄中搜尋是否有 HTTP 狀態代碼 500 的跡象,這表示網頁伺服器上的錯誤。 一旦偵測到其中一個,就可以將電子郵件或簡訊傳送給原始服務的擁有者,以便開始調查。
不過,一般而言,單一 500 錯誤不足以判斷發生問題。 這可能表示使用者輸入密碼錯誤或輸入一些格式不正確的數據。 警示查詢可以被設定成只有在偵測到超過平均數的 500 個錯誤時才發動。
警示中最具破壞性的模式之一是過多地發出警示,使人難以逐一調查。 服務擁有者會很快對先前調查過且確認為良性的錯誤變得不敏感。 然後,當真正的錯誤發生時,它們會淹沒在數百個偽陽性的雜訊中。 這個「狼來了的男孩」比喻經常用來警告孩子們注意這種危險。 請務必確保引發的警報能夠真正指示實際問題。