本文討論機器學習 (ML) 模型中的混淆矩陣、分類問題和準確性。 目的是增強您對 ML 預測結果正確性的理解。 目標受眾包括希望建立資料科學知識和技能的工程師、分析師和經理。
混淆矩陣
在一組歷史資料上訓練有監督的 ML 問題後,將使用訓練流程中保留的資料對其進行測試。 透過這種方式,您可以將訓練模型的預測與實際值進行比較。 混淆矩陣提供了一種評估分類問題的成功程度以及錯誤的發生位置 (即混淆之處) 的方法。
例如,您的目標是根據一些身體和行為屬性來預測寵物是狗還是貓。 如果您有一個包含 30 隻狗和 20 隻貓的測試資料集,則混淆矩陣可能類似於下圖。
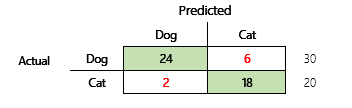
綠色儲存格中的數字代表正確的預測。 如您所見,該模型正確預測了實際貓的百分比更高。 模型的整體正確性很容易計算。 在此案例中,其為 42 ÷ 50,或 0.84。
混淆矩陣中的多類分類器
大多數關於混淆矩陣的討論都集中在二元分類器上,如前面的範例所示。 這種情況是一種特殊情況,可以考慮其他計量,例如敏感度和召回率。
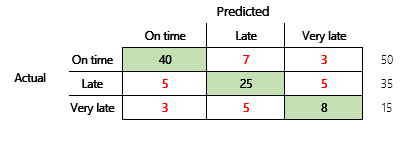
接下來,我們將考慮具有三個狀態的財務案例的分類問題。 該模型預測客戶發票是否會按時、逾期或嚴重逾期支付。 例如,在 100 張測試發票中,有 50 張按時付款,35 張逾期付款,15 張逾期付款。 在這種情況下,模型可能會產生類似於下圖的混淆矩陣。
 ]
]
與簡單的正確性計量相比,混淆矩陣提供的資訊要多得多。 但是,它仍然相對容易理解。 混淆矩陣告訴您是否有一個平衡的資料集,其中輸出類具有相似的計數。 對於多類案例,它會告訴您當輸出類是序數時,預測可能離您有多遠,如前面關於客戶付款的範例中所示。
模型正確性
不同的正確性計量具有量化模型品質的優勢。
因為正確性是一個易於理解的計量,所以它是向其他人解釋模型的一個很好的起點,尤其是對於不是資料科學家的模型使用者。 無需了解統計資料即可了解模型的正確性。 當混淆矩陣可用時,它可以進一步了解模型的效能。
然而,為了更透徹地理解,應注意與正確性相關的幾個挑戰。 計量的有用性取決於問題的內容。 與模型性能相關的一個經常出現的問題是,「模型有多好?然而,這個問題的答案不一定很簡單。 考慮以下混淆矩陣 (模型 2)。
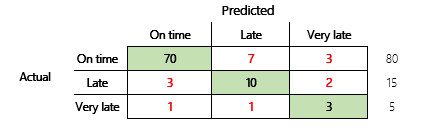
快速計算表明,該模型的正確性為 (70 + 10 + 3) ÷ 100,即 0.83。 從表面上看,這個結果似乎比之前的多類模型 (模型 1) 的結果要好,後者的正確性為 0.73。 但它更好嗎?
要開始解決這個問題,請考慮本能猜測的正確性。 對於分類問題,簡單的猜測總是會預測出最常見的類別。 對於模型 1,該猜測將是「準時」的,它會產生 0.50 的正確性。 對於模型 2,該猜測也將是「準時」的,它會產生 0.80 的正確性。 因為模型 1 將本能猜測提高了 0.73–0.50 = 0.23,而模型 2 將本能猜測提高了 0.83–0.80 = 0.03,因此模型 1 是一個更好的模型,儘管它的正確性較低。 計算表明,對模型品質的有效評估需要比正確性值更多的內容。
還需要注意一個方面。 考慮一個使用醫學測試來檢測患者疾病的案例。 該問題是一個二元分類問題,其中陽性結果表明患者患有該疾病。 在這種情況下,您必須考慮以下錯誤的影響:
- 誤判,即測試表明患者患有這種疾病,但患者並沒有真正患有這種疾病。
- 漏報,即測試表明患者未患有這種疾病,但實際上該患者有。
顯然,我們都不希望發生這兩種類型的錯誤,但哪一種更糟? 再次,這取決於具體情況。 對於需要快速治療的危及生命的疾病,應盡量減少漏報 (希望隨後進行額外的測試)。 在其他不太嚴重的情況下,模型建立者可能會盡量減少誤判。 無論如何,合理的結論是,要有效地確定模型的品質,您必須擁有比正確性計量提供的資訊更多資訊。
建議
正確性是與不熟悉統計資料的領域專家交流的重要工具。 然而,為了使資訊有用,提供額外的內容和正確性值是至關重要的。
對於支付預測案例,您可以為 ML 模型設定包含不同支付行為因素的目標。 目標是模型應該透過將錯誤答案的數量減少至少 50% 來改進本能的猜測。 換句話說,您需要一個目標正確性,它將本能猜測的正確性與 100% 的正確性分開。
下表總結了本文中混淆矩陣的這一原則。
| 模型 | 本能猜測 | 目標 | 模型正確性 | 達成目標了嗎? |
|---|---|---|---|---|
| 模型 1 | 0.50 | 0.75 | 0.73 | 幾乎達成。 該模型顯著改進了猜測。 |
| 模型 2 | 0.80 | 0.90 | 0.83 | 編號 需要改進。 |
分類 F1 正確性
本文的最後一個注意事項是分類 ML 性能的更高級度量,稱為 F1 準確性。
在定義 F1 正確性之前,必須引入兩個額外的計量:精確度和召回率。 精確度表示指定為正的預測總數中有多少被正確分配。 該計量也稱為陽性預測值。 召回率是正確預測的實際陽性病例的總數。 該計量也稱為靈敏度。
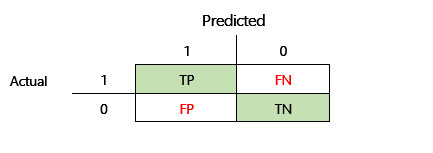
在上圖中的混淆矩陣中,這些計量的計算方式如下:
- 精確度 = TP ÷ (TP + FP)
- 召回率 = TP ÷ (TP + FN)
F1 計量結合了精確度和召回率。 結果是兩個值的調和平均值。 它的計算方式如下:
- F1 = 2 × (精確度 × 召回率) ÷ (精確度 + 召回率)
讓我們看一個具體的例子。 在本文的前面,有一個模型的例子,可以預測動物是狗還是貓。 以下重複此圖。
如果將「狗」當作肯定的答案,則結果如下。
- 精確度 = 24 ÷ (24 + 2) = 0.9231
- 招回率 = 24 ÷ (24 + 6) = 0.8
- F1 = 2 × (0.9231 × 0.8) ÷ (0.9231 + 0.8) = 0.8572
如您所見,F1 值介於精確度值和召回率值之間。
儘管 F1 正確性並不那麼容易理解,但它會增加基本正確性數字的細微差別。 它還可以幫助處理不平衡的資料集,如下面的討論所示。
本文的 模型準確性 部分比較了以下兩個混淆矩陣。 儘管第一個模型的正確性較低,但它被認為是一個更有用的模型,因為它比預設的按時付款猜測顯示出更多的改進。
讓我們看看這兩個模型在使用 F1 分數時的比較。 F1 分數會影響每個狀態的精確度和召回率,然後 F1 巨集計算會平均各個狀態的 F1 分數以確定總體 F1 分數。 還有其他 F1 變體,但考慮到對所有三個狀態的同等考慮,考慮巨集版本會更有趣。
為了簡化計算,構建了樣本陣列以符合實際值和預測值。 這些陣列在 Python 中使用了 sklearn 的指標庫來計算值。 結果如下。
| 模型 | 本能猜測 | 正確性 | F1 巨集 |
|---|---|---|---|
| 模型 1 | 0.5 | 0.73 | 0.67 |
| 模型 2 | 0.80 | 0.83 | 0.66 |
有關此計算如何工作的更多詳細資料,請參閱模型 1 的 sklearn.metrics 分類報告。 「準時」、「逾期」和「嚴重逾期」這三種狀態分別由標記為 1、2 和 3 的行表示。 巨集平均值只是「f1-score」欄的平均值。
| 精確度 | 招回率 | f1-score | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
如這些結果所示,這兩個模型具有幾乎相同的 F1 巨集正確性分數。 在這種情況和許多其他情況下,F1 正確性可以更好地指示模型的能力。 至於正確性,結果的解釋要求您了解模型中最重要的考慮因素。