在 Microsoft Fabric 中設定入門集區
在本文章中,我們會說明如何在 Microsoft Fabric 中針對分析工作負載自訂入門集區。 入門集區是一種快速且簡單的方法,可在數秒內在 Microsoft Fabric 平台上使用 Spark。 此方法可讓您立即使用 Spark 工作階段,而無需等待 Spark 為您設定節點,這可協助您使用資料進行更多作業,並更快速地取得深入解析。
入門集區具有始終開啟並準備就緒回應您請求的 Spark 叢集。 它們使用中型節點,並可根據您的工作負載需求相應擴大。
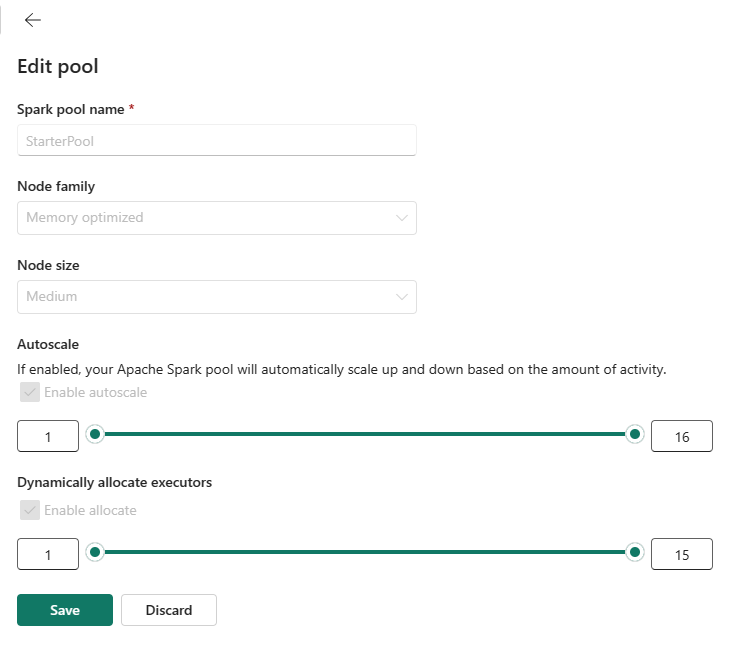
您可以根據資料工程或資料科學工作負載需求,指定自動調整的最大節點。 根據所設定的最大節點,系統會依工作的計算需求變更而動態取得和淘汰節點,從而實現高效調整和改善效能。
也可以在入門集區中設定執行程式的最大限制,當啟用了動態配置時,系統會根據資料量和工作層級計算需求來調整執行程式數目。 此程序可讓您專注於工作負載,而不必擔心效能優化和資源管理。
注意
若要自訂入門集區,您需要工作區的管理員存取權限。
設定入門集區
若要管理與工作區相關聯的入門集區:
前往工作區,選擇 [工作區設定]。
![螢幕擷取畫面,其中顯示在 [工作區設定] 功能表中選取 [資料工程] 的位置。](media/configure-starter-pools/data-engineering-menu.png)
然後,選取 [資料工程/科學] 選項以展開功能表。
選取 [入門集區] 選項。
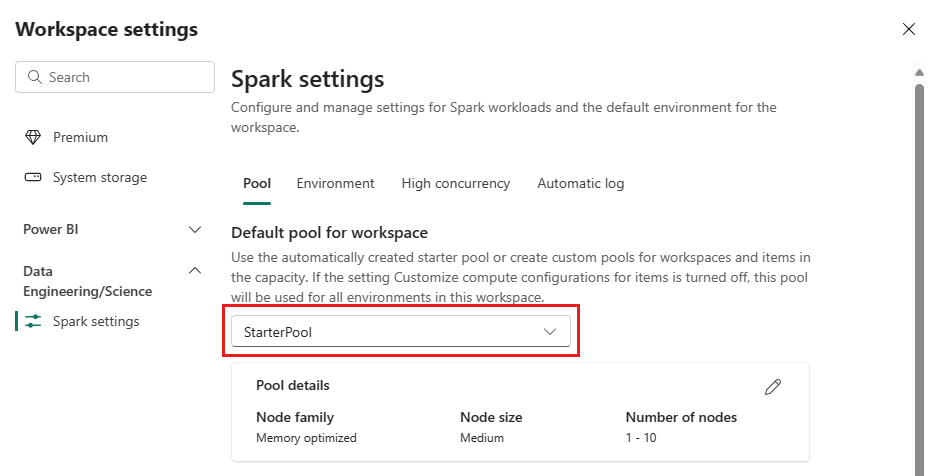
您可以根據購買的容量,將入門集區的節點組態上限設定為允許的數目,或在執行較小的工作負載時,降低預設的最大節點組態數目。
![螢幕擷取畫面,其中顯示在 [工作區設定] 功能表中選取 [資料工程] 的位置。](media/configure-starter-pools/data-engineering-menu.png#lightbox)
下方列出了基於 Microsoft Fabric 容量 SKU 的入門集區支援的各種預設組態和最大節點數目限制:
| SKU 名稱 | 容量單位 | Spark VCores | 節點大小 | 預設節點數目上限 | 節點數目上限 |
|---|---|---|---|---|---|
| F2 | 2 | 4 | 中 | 1 | 1 |
| F4 | 4 | 8 | 中 | 1 | 1 |
| F8 | 8 | 16 | 中 | 2 | 2 |
| F16 | 16 | 32 | 中 | 3 | 4 |
| F32 | 32 | 64 | 中 | 8 | 8 |
| F64 | 64 | 128 | 中 | 10 | 16 |
| (試用版容量) | 64 | 128 | 中 | 10 | 16 |
| F128 | 128 | 256 | 中 | 10 | 32 |
| F256 | 256 | 512 | 中 | 10 | 64 |
| F512 | 512 | 1024 | 中 | 10 | 128 |
| F1024 | 1024 | 2048 | 中 | 10 | 200 |
| F2048 | 2048 | 4096 | 中 | 10 | 200 |
注意
若要自訂入門集區,您需要工作區的管理員存取權限。
相關內容
- 若要深入了解,請參閱 Apache Spark 公開文件。
- 開始使用 Microsoft Fabric 中的 Spark 工作區管理設定。