在本教學課程中,了解如何在 Microsoft Fabric 中建立 Spark 工作定義。
Spark 工作定義建立程序快速且簡單;有數種方式可以開始使用。
你可以從 Fabric 入口網站建立 Spark 工作定義,或使用 Microsoft Fabric REST API 來建立。 本文重點是從 Fabric 入口網站建立 Spark 工作定義。 關於使用 REST API 建立 Spark 工作定義的資訊,請參閱 Apache Spark 工作定義 API v1 及 Apache Spark 工作定義 API v2。
必要條件
在開始之前,您必須:
- 具有作用中訂用帳戶的 Fabric 租用戶帳戶。 免費建立帳戶。
- Microsoft Fabric 中的一個工作空間。 欲了解更多資訊,請參閱「 在 Microsoft Fabric 中建立與管理工作空間」。
- 工作空間裡至少有一棟湖邊小屋。 湖屋是 Spark 工作定義的預設檔案系統。 欲了解更多資訊,請參閱 「創建湖畔別墅」。
- Spark 作業的主要定義檔案。 此檔案包含應用程式邏輯,且是執行 Spark 作業的必備文件。 每個 Spark 工作定義只能有一個主要定義檔案。
當您建立 Spark 工作定義時,您必須提供名稱。 名稱在目前工作區內必須具有唯一性。 新的 Spark 工作定義會在您目前的工作區中建立。
在 Fabric 入口網站建立 Spark 工作定義
要在 Fabric 入口網站建立 Spark 工作定義,請依照以下步驟操作:
- 登入 Microsoft Fabric 入口網站。
- 導航至您要建立 Spark 工作定義的工作區。
- 選擇 新項目>Spark 作業定義。
- 在 新 Spark 工作定義 窗格中,請提供以下資訊:
- 名稱:輸入一個獨特的 Spark 工作定義名稱。
- 地點:選擇工作區位置。
- 選擇 建立 以建立 Spark 工作定義。
建立 Spark 工作定義的另一個入口是利用 Fabric 首頁上的 SQL ...圖塊進行 資料分析 。 您可以選取 [一般] 圖塊,以找到相同的選項。
![螢幕快照,其中顯示在 [建立中樞] 上選取Spark作業定義的位置。](media/create-spark-job-definition/create-hub-data-engineering.png#lightbox)
當你選擇該磁磚時,系統會提示你建立新工作區或選擇現有工作區。 選擇工作區後,Spark 工作定義建立頁面會開啟。
自訂 PySpark(Python)的 Spark 工作定義
在你為 PySpark 建立 Spark 工作定義之前,你需要先上傳一個範例 Parquet 檔案到 lakehouse。
- 下載範例 Parquet 檔案 yellow_tripdata_2022-01.parquet。
- 到你想上傳檔案的湖屋。
- 上傳到湖邊別墅的「檔案」區塊。
針對 PySpark 建立 Spark 工作定義:
從 [語言] 下拉式清單中選取 [PySpark (Python)]。
下載 createTablefromParquet.py 範例定義檔。 把它上傳成主要的定義檔案。 主要定義檔案 (job.Main) 是包含應用程式邏輯的檔案,而且是執行 Spark 工作的必要項目。 針對每個 Spark 工作定義,您只能上傳一個主要定義檔案。
注意
您可以從本機桌面上傳主要定義檔案,也可以藉由提供檔案的完整 ABFSS 路徑,從現有的 Azure Data Lake Storage (ADLS) Gen2 上傳。 例如:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path。可選擇性地將參考檔案上傳成
.py(Python)檔案。 參考檔案是主定義檔匯入的 Python 模組。 如同主要定義檔案,您可以從桌面或現有的 ADLS Gen2 上傳。 支援多個參考檔案。提示
如果你使用 ADLS Gen2 路徑,請確保檔案是可存取的。 你必須給執行該工作的使用者帳號適當的儲存帳號權限。 以下是兩種不同的授權方式:
- 為使用者帳戶指派儲存體帳戶的參與者角色。
- 透過 ADLS Gen2 存取控制清單 (ACL) 將檔案的讀取和執行權限授與使用者帳戶。
手動執行時,會使用目前登入使用者的帳號來執行該工作。
視需要提供工作的命令列引數。 使用空格做為分隔符號來分隔引數。
將 Lakehouse 參考新增至工作。 您必須將至少一個 Lakehouse 參考新增至工作。 此 Lakehouse 是工作的預設 Lakehouse 內容。
支援多個 Lakehouse 參考。 在 [Spark 設定] 頁面中尋找非預設的 Lakehouse 名稱和完整的 OneLake 網址。

自訂 Scala/Java 的 Spark 工作定義
針對 Scala/JAVA 建立 Spark 工作定義:
從 [語言] 下拉式清單中選取 [Spark (Scala/JAVA)]。
將主定義檔上傳為
.jar(Java)檔案。 主要定義檔案是包含此工作應用程式邏輯的檔案,而且是執行 Spark 工作的必要項目。 針對每個 Spark 工作定義,您只能上傳一個主要定義檔案。 提供主要類別名稱。可選擇性地將參考檔案上傳為
.jar(Java)檔案。 參考檔案是主要定義檔案所參考/匯入的檔案。視需要提供工作的命令列引數。
將 Lakehouse 參考新增至工作。 您必須將至少一個 Lakehouse 參考新增至工作。 此 Lakehouse 是工作的預設 Lakehouse 內容。
為 R 自訂 Spark 工作定義
針對 SparkR(R) 建立 Spark 工作定義:
從 [語言] 下拉式清單中選取 [SparkR(R)]。
將主定義檔上傳為
.r(R) 檔案。 主要定義檔案是包含此工作應用程式邏輯的檔案,而且是執行 Spark 工作的必要項目。 針對每個 Spark 工作定義,您只能上傳一個主要定義檔案。可選擇性地將參考檔案上傳為
.r(R) 檔案。 參考檔案是主要定義檔案所參考/匯入的檔案。視需要提供工作的命令列引數。
將 Lakehouse 參考新增至工作。 您必須將至少一個 Lakehouse 參考新增至工作。 此 Lakehouse 是工作的預設 Lakehouse 內容。
注意
Spark 工作定義是在你目前的工作空間中建立的。
自訂 Spark 工作定義的選項
有一些選項可以進一步自訂 Spark 工作定義的執行。
Spark Compute:在 Spark Compute 分頁中,你可以看到用來執行 Spark 工作的 Fabric 執行時版本 。 你也可以看到執行該工作時使用的 Spark 設定。 你可以透過選擇 新增 按鈕來自訂 Spark 的設定。
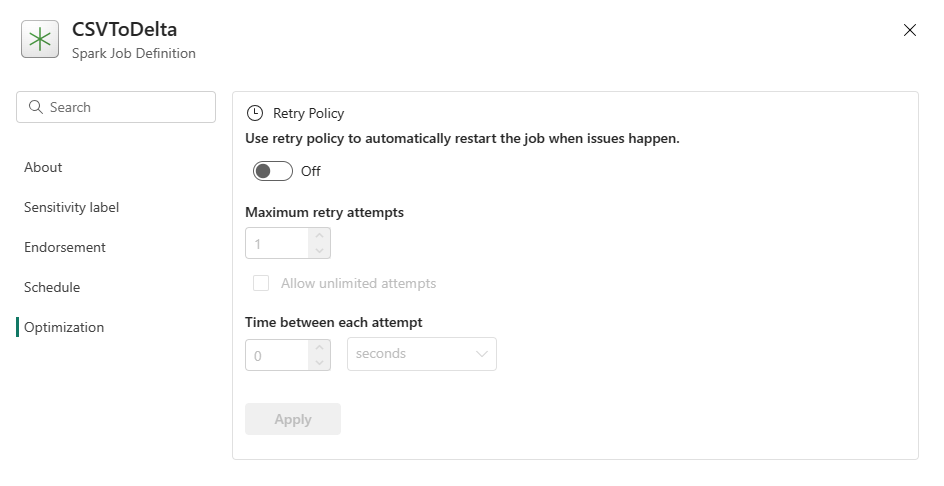
最佳化:在 [最佳化] 索引標籤上,您可以啟用和設定工作的重試原則。 啟用時,如果工作失敗,則會進行重試。 您也可以設定重試次數上限和重試之間的間隔。 每次進行重試嘗試時,工作都會重新啟動。 請確定工作等冪。