網狀架構執行階段提供與 Azure 的無縫整合。 它為使用 Apache Spark 的資料工程和資料科學項目提供複雜的環境。 本文概述了 Fabric Runtime 1.3 的基本功能與元件。
Microsoft Fabric Runtime 1.3 是一個通用執行版本,包含以下元件與升級,旨在提升您的資料處理能力:
- Apache Spark:3.5
- 作業系統: Mariner 2.0 (Azure Linux 2.0)
- Java:11
- Scala:2.12.17
- Python 3.11
- Delta Lake:3.2
- R:4.4.1
Important
Runtime 1.3 的搶先體驗版本包含從 Mariner 2.0(Azure Linux 2.0)升級至 Mariner 3.0(Azure Linux 3.0)的作業系統。 使用 搶先體驗發布通道,在這項變更成為預設值之前測試您的工作負載。 這種驗證非常重要,尤其是當你的工作負載依賴作業系統層級套件時。
提示
Fabric Runtime 1.3 包含 原生執行引擎的支援,可大幅提升效能,而不需要更多成本。 若要在環境中的所有作業和筆記本上啟用原生執行引擎,請流覽至您的環境設定、選取 [Spark 計算]、移至 [加速] 索引卷標,然後核取 [啟用原生執行引擎]。 儲存併發佈之後,此設定會套用到整個環境,因此所有新的作業和筆記本都會自動繼承並受益於增強的效能功能。
整合 Runtime 1.3
備註
有關所有可用的 Fabric 執行環境及其當前狀態,請參見 Apache Spark Runtimes in Fabric。
使用下列指示,將執行階段 1.3 整合到您的工作區,並使用其新功能:
瀏覽至您的 Fabric 工作區內的 工作區設定標籤頁。
移至資料工程師/科學 索引標籤,然後選取Spark 設定。
選取環境索引標籤。
在 [ 執行階段版本 ] 下展開下拉式清單。
選取 1.3(Spark 3.5、Delta 3.2) 並儲存變更。 此動作會將 1.3 設定為工作區的預設執行階段。
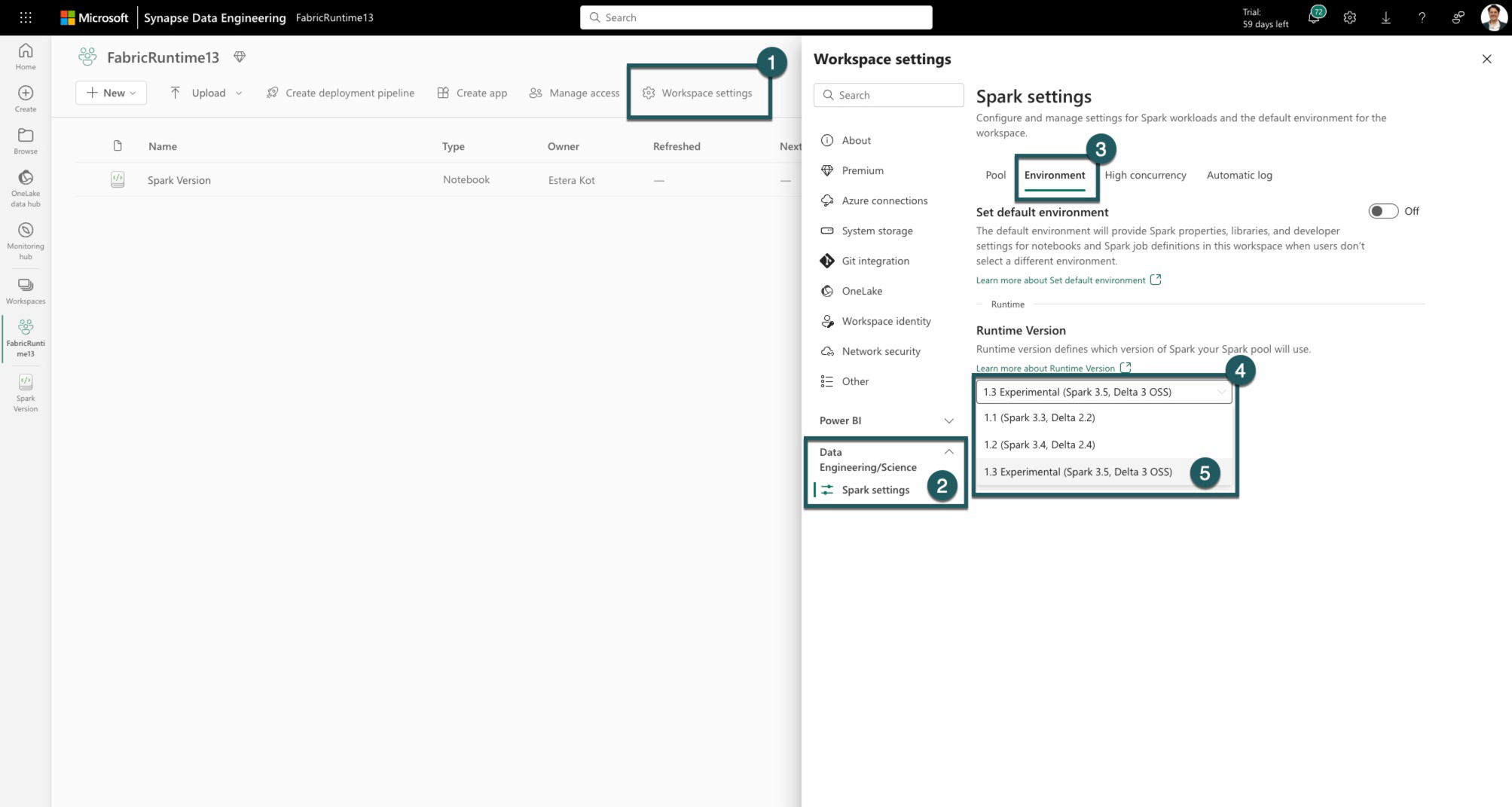

您現在可以開始使用最新引進的 Fabric Runtime 1.3(包括 Spark 3.5 和 Delta Lake 3.2)的改進和功能。
瞭解 Apache Spark 3.5
Apache Spark 3.5.0 是 3.x 系列中的第六個版本。 此版本是開放原始碼社群中廣泛共同作業的產物,可解決 Jira 中所記錄的 1,300 多個問題。
在此版本中,結構化串流的相容性有所升級。 此外,此版本會擴大 PySpark 和 SQL 中的功能。 它會新增 SQL 標識符子句、SQL 函數調用中的具名自變數,以及包含 HyperLogLog 近似彙總的 SQL 函式等功能。
其他新功能還包括 Python 使用者定義資料表函式、透過 DeepSpeed 簡化分散式訓練,以及新的結構化串流功能,例如水印傳播和 dropDuplicatesWithinWatermark 作業。
您可以在這裏檢查完整清單和詳細變更: Spark 3.5.0 版。
認識 Delta Spark 相關資訊
Delta Lake 3.2 標誌著一項集體承諾,讓 Delta Lake 跨格式互通、更容易使用,且效能更高。 Delta Spark 3.2 建置在 Apache Spark™ 3.5 之上。 Delta Spark Maven 工件的名稱已由 delta-core 更改為 delta-spark。
您可以在這裡檢查完整清單和詳細變更:https://docs.delta.io/index.html。
元件和程式庫
如需最新資訊、變更的詳細清單,以及 Fabric 執行時間的特定版本資訊,請檢查並訂閱 Spark 執行階段版本和更新。
備註
EventHubConnector 已在 Fabric 執行階段 1.3 (Spark 3.5) 中取代,並將從未來的 Fabric 執行階段版本中移除。 鼓勵用戶改用 Kafka Spark Connector,因為 Event Hubs 已經支援 Kafka。 你可以在這裡找到更多關於使用 Kafka Spark 連接器與事件中心的資訊: Event Hubs Kafka Spark 教學
相關內容
- 閱讀 Fabric 中的 Apache Spark 運行時概覽、版本控制、多個運行時支援和升級 Delta Lake 協議
- Spark Core 移轉指南
- SQL、資料集和資料框架移轉指南
- 結構化串流移轉指南
- MLlib (機器學習) 移轉指南
- PySpark (Spark 上的 Python) 移轉指南
- SparkR (Spark 上的 R) 移轉指南