執行 Azure Databricks 活動來轉換資料
Microsoft Fabric Data Factory 中的 Azure Databricks 活動可讓您協調下列 Azure Databricks 工作類型:
- Notebook
- Jar
- Python
本文章提供逐步解說,說明如何使用 Data Factory 介面建立 Azure Databricks 活動。
必要條件
若要開始使用,您必須滿足下列必要條件:
- 具有有效訂閱的租用戶帳戶。 免費建立帳戶。
- 已建立一個工作區。
設定 Azure Databricks 活動
若要在管線中使用 Azure Databricks 活動,請完成下列步驟:
設定連線
在工作區中建立新的管線。
按一下 [新增管線活動],然後搜尋 Azure Databricks。
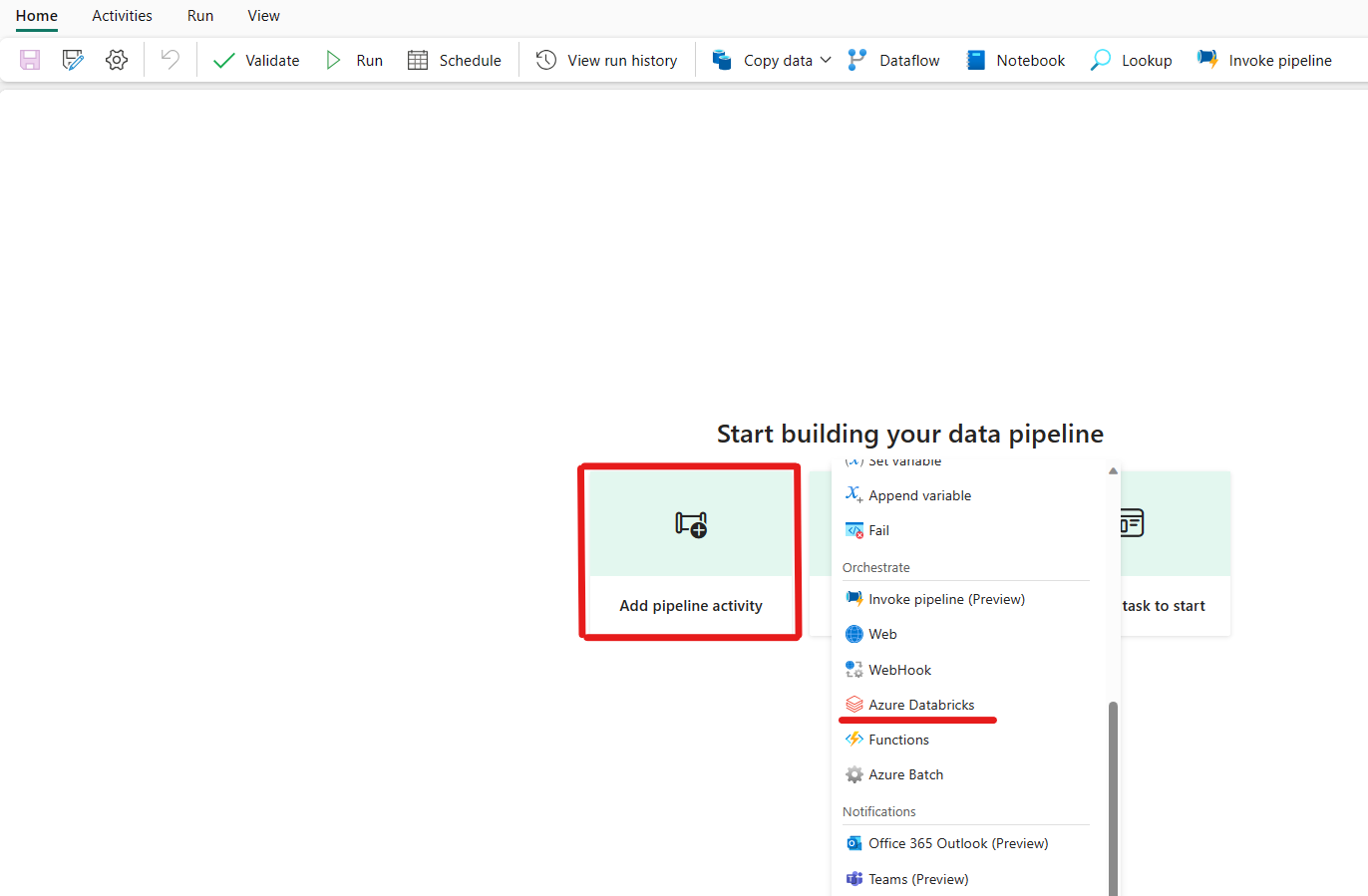
或者,可在管線 [活動] 窗格中搜尋 Azure Databricks,將其選中並新增至管線創作區。
![螢幕擷取畫面,其中已醒目提示 [活動] 窗格和 Azure Databricks 活動的 Fabric UI。](media/azure-databricks-activity/pick-databricks-activity-from-pane.png)
如果尚未進行選取,請在創作區選取新的 Azure Databricks 活動。
![螢幕擷取畫面,其中顯示了 Azure Databricks 活動的 [一般] 設定索引標籤。](media/azure-databricks-activity/databricks-activity-general.png)
請參閱<[一般] 設定>指導,來設定 [一般] 設定索引標籤。
設定叢集
選取 [叢集] 索引標籤。然後您可以選擇現有的或建立新的 Azure Databricks 連線,然後挑選新的工作叢集、現有的互動式叢集或現有的執行個體集區。
根據您為叢集挑選的內容,填寫所展示的對應欄位。
- 在新的工作叢集和現有的執行個體集區下,您也可以設定背景工作角色數目並啟用現成執行個體。
您也可以指定其他叢集設定,例如叢集原則、Spark 組態、Spark 環境變數和自訂標籤,視要連線的叢集需求而定。 Databricks init 指令和叢集記錄檔目的地路徑也可以在其他叢集設定下新增。
注意
AZURE Data Factory Azure Databricks 連結服務中支援的所有進階叢集屬性和動態運算式,現在在 UI 的 [其他叢集組態] 區段下 Microsoft Fabric Azure Databricks 活動中也支援。 因為這些屬性現在包含在活動 UI中;它們可以輕鬆地與運算式 (動態內容) 搭配使用,而不需要 Azure Data Factory Azure Databricks 連結服務中的進階 JSON 規格。
![螢幕擷取畫面,其中顯示了 Azure Databricks 活動的 [叢集設定] 索引標籤。](media/azure-databricks-activity/databricks-activity-cluster.png)
Azure Databricks 活動現在也支援叢集原則和 Unity 目錄支援。
- 在進階設定下,您可以選擇 [叢集原則],以便指定允許的叢集組態。
- 此外,在進階設定下,您可以選擇設定 [Unity 目錄存取模式],以增加安全性。 可用的存取模式類型如下:
- 單一使用者存取模式 此模式是針對單一使用者使用每個叢集的案例所設計。 它可確保叢集中的資料存取僅限於該使用者。 此模式適用於需要隔離和個別資料處理的工作。
- 共用存取模式 在此模式中,多個使用者可以存取相同的叢集。 它會結合 Unity 目錄的資料控管與舊版資料表存取控制清單 (ACL)。 此模式允許共同作業資料存取,同時維護治理和安全性通訊協定。 不過,它存在某些限制,例如不支援 Databricks Runtime ML、Spark 提交工作,以及特定的 Spark API 和 UDF。
- 無存取模式 此模式會停用與 Unity 目錄的互動,這表示叢集無法存取 Unity 目錄所管理的資料。 此模式適用於不需要 Unity 目錄治理功能的工作負載。
![螢幕擷取畫面,其中顯示了 Azure Databricks 活動 [叢集設定] 索引標籤下的原則 ID 和 Unity 目錄支援。](media/azure-databricks-activity/databricks-activity-policy-uc-support.png)
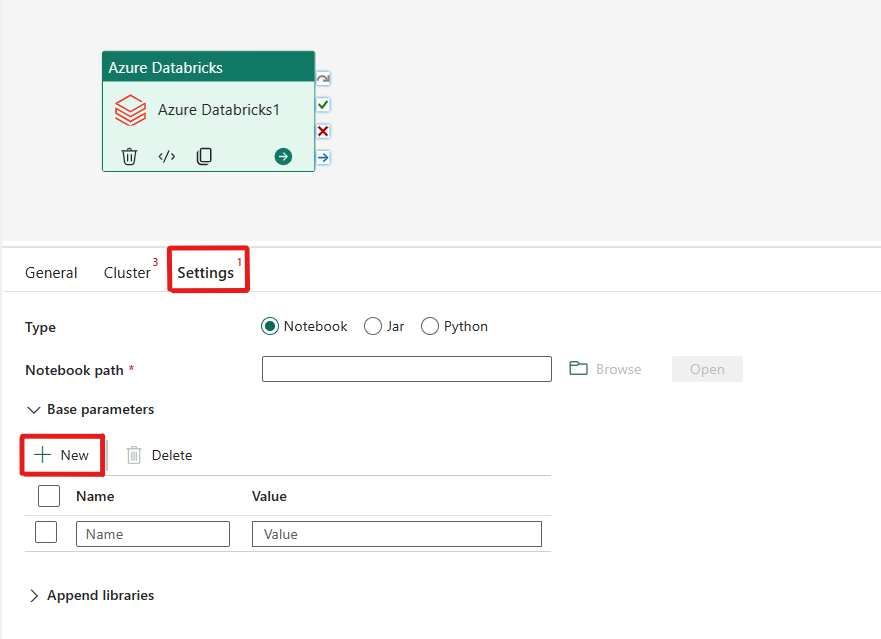
設定設定值
選取 [設定] 索引標籤,您可以在 3 個選項中選擇您想要協調的 [Azure Databricks 類型]。
![螢幕擷取畫面,其中顯示了 Azure Databricks 活動的 [設定] 索引標籤。](media/azure-databricks-activity/databricks-activity-settings.png)
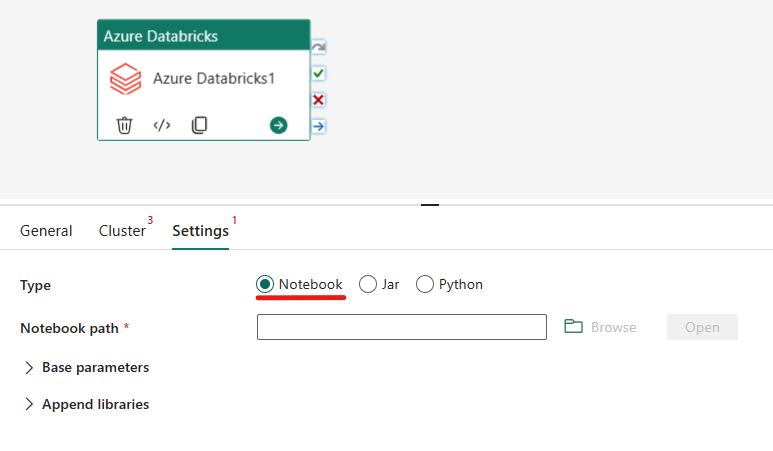
在 Azure Databricks 活動中協調 Notebook 類型:
在 [設定] 索引標籤下,您可以選擇 [Notebook] 圓形按鈕來執行 Jar。 您將需要指定 Azure Databricks 上所要執行的筆記本路徑、要傳遞至筆記本的選擇性基本參數,以及要安裝在叢集上以執行工作的任何程式庫。
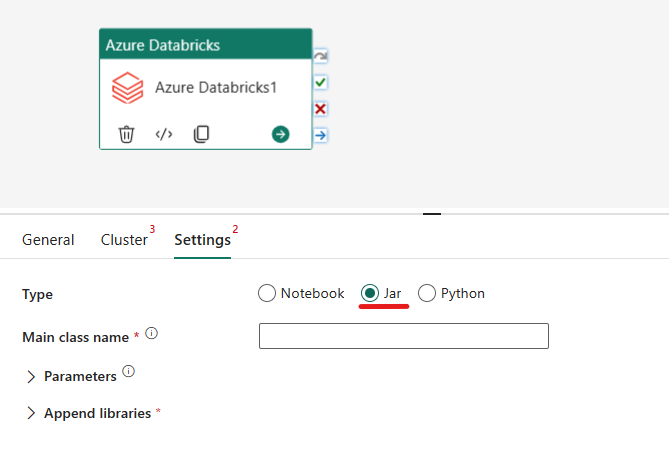
在 Azure Databricks 活動中協調 Jar 類型:
在 [設定] 索引標籤下,您可以選擇 [Jar] 圓形按鈕來執行 Jar。 指定要在 Azure Databricks 上執行的類別名稱、要傳遞至 Jar 的選用參數,以及要安裝於叢集上以執行該作業的任何其他程式庫。
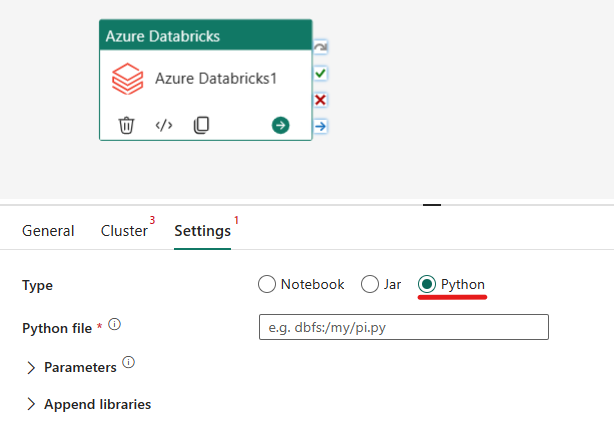
在 Azure Databricks 活動中協調 Python 類型:
在 [設定] 索引標籤下,您可以選擇 [Python] 圓形按鈕來執行 Python 檔案。 您需要指定 Azure Databricks 內所要執行 Python 檔案的路徑、要傳遞的選擇性參數,以及要安裝在叢集上以執行作業的任何其他程式庫。
Azure Databricks 活動支援的程式庫
在上述的 Databricks 活動定義中,您可指定以下的程式庫類型:jar、egg、whl、maven、pypi、cran。
如需詳細資訊,請參閱<Databricks 說明文件>,以了解程式庫型別。
在 Azure Databricks 活動和管線之間傳遞參數
您可以在 Databricks 活動中使用 baseParameters 屬性,將參數傳遞至筆記本。
在某些情況下,您可能需要將特定值從筆記本傳回服務,這可以用來控制服務內的流程 (條件式檢查),或由下游活動取用 (大小限制為 2 MB)。
舉例來說,在您的筆記本中,您可以呼叫 dbutils.notebook.exit("returnValue"),並將對應的 "returnValue" 傳回至服務。
您可以使用
@{activity('databricks activity name').output.runOutput}等運算式來取用服務中的輸出。
儲存並執行或排程管線
設定管線所需的任何其他活動之後,請切換至管線編輯器頂端的 [首頁] 索引標籤,然後選取 [儲存] 按鈕以儲存管線。 選取 [執行] 以直接執行,或選取 [排程] 來排程。 您也可以在這裡檢視執行歷程記錄,或進行其他設定。
