數據流 Gen2 資料目的地和受控設定
使用 Dataflow Gen2 清理並備妥數據之後,您想要將資料降落在目的地中。 您可以使用資料流 Gen2 中的數據目的地功能來執行這項操作。 透過這項功能,您可以從不同的目的地挑選,例如 Azure SQL、Fabric Lakehouse 等等。 然後,數據流 Gen2 會將您的數據寫入目的地,然後從該處使用您的數據進行進一步分析和報告。
下列清單包含支持的數據目的地。
- Azure SQL 資料庫
- Azure 資料總管 (Kusto)
- Fabric Lakehouse
- 網狀架構倉儲
- 網狀架構 KQL 資料庫
進入點
數據流 Gen2 中的每個數據查詢都可以有數據目的地。 不支援函式和清單;您只能將它套用至表格式查詢。 您可以個別指定每個查詢的數據目的地,而且可以在數據流內使用多個不同的目的地。
有三個主要進入點可指定數據目的地:
透過頂端功能區。
![Power Query 首頁索引標籤功能區的螢幕快照,其中強調 [新增數據目的地]。](media/dataflow-gen2-data-destinations-and-managed-settings/top-ribbon-destination.png)
透過查詢設定。
![[查詢設定] 窗格的螢幕快照,其中強調 [數據目的地] 按鈕和顯示的目的地清單。](media/dataflow-gen2-data-destinations-and-managed-settings/query-settings-destination.png)
透過圖表檢視。
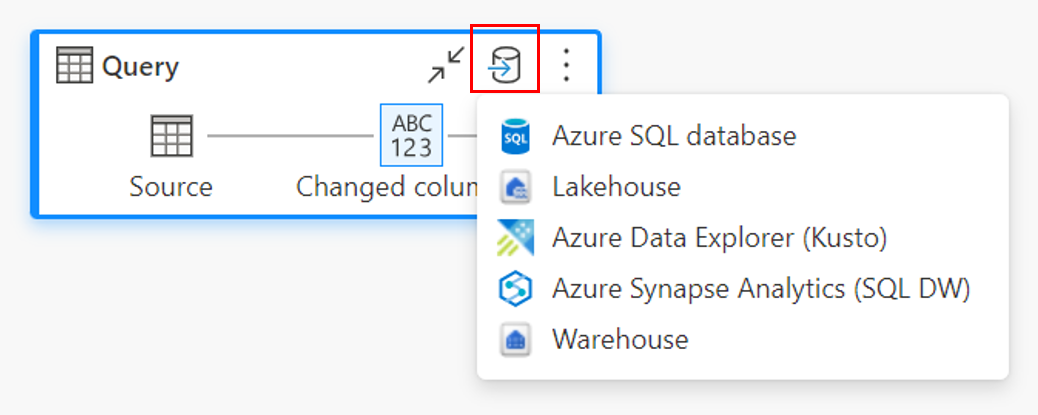
連線 至數據目的地
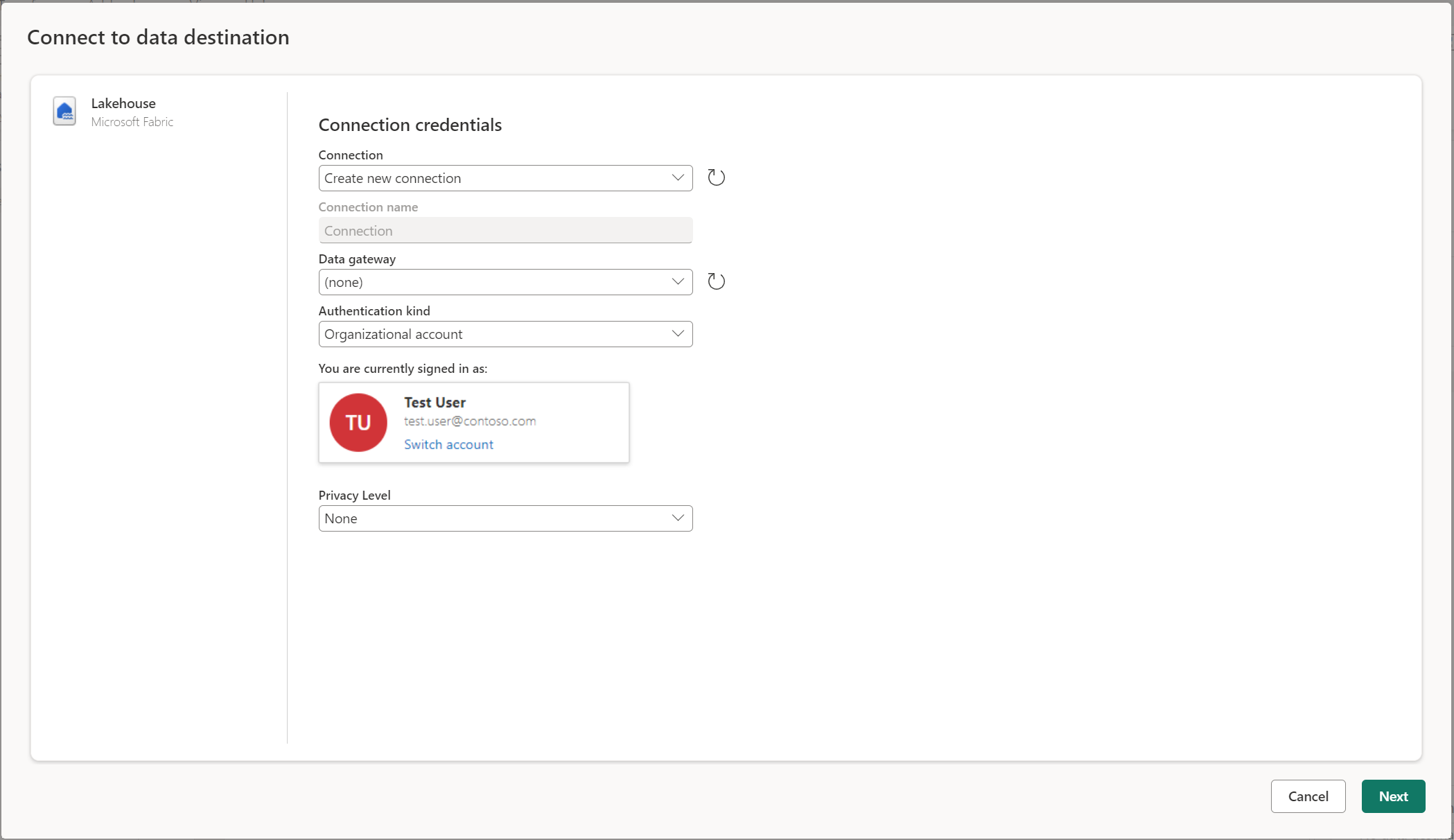
連線 至數據目的地類似於連接到數據源。 連線 可用於讀取和寫入數據,因為您擁有數據源的正確許可權。 您必須建立新的連線或挑選現有的連線,然後選取 [ 下一步]。
建立新的數據表或挑選現有的數據表
載入資料目的地時,您可以建立新的資料表或挑選現有的數據表。
建立新表格
當您選擇建立新的資料表時,在數據流 Gen2 重新整理期間,會在您的資料目的地中建立新的資料表。 如果數據表在未來透過手動進入目的地而刪除,數據流會在下一次數據流重新整理期間重新建立數據表。
根據預設,您的數據表名稱與查詢名稱的名稱相同。 如果您的數據表名稱中有任何無效的字元,目的地不支援,則會自動調整數據表名稱。 例如,許多目的地不支援空格或特殊字元。
![[選擇目的地目標] 視窗的螢幕快照,其中已選取 [新增數據表] 按鈕。](media/dataflow-gen2-data-destinations-and-managed-settings/new-table.png)
接下來,您必須選取目的地容器。 如果您選擇任何網狀架構資料目的地,您可以使用導覽器來選取您想要將數據載入的網狀架構成品。 針對 Azure 目的地,您可以在建立連線期間指定資料庫,或從導覽器體驗中選取資料庫。
使用現有的數據表
若要選擇現有的數據表,請使用導覽器頂端的切換開關。 選擇現有的數據表時,您必須使用導覽器來挑選 Fabric 成品/資料庫和數據表。
當您使用現有的數據表時,任何案例都無法重新建立數據表。 如果您從數據目的地手動刪除數據表,數據流 Gen2 不會在下一次重新整理時重新建立數據表。
![[選擇目的地目標] 視窗的螢幕快照,其中已選取 [現有數據表] 按鈕。](media/dataflow-gen2-data-destinations-and-managed-settings/existing-table.png)
新數據表的Managed設定
當您載入新資料表時,預設會開啟自動設定。 如果您使用自動設定,數據流 Gen2 會為您管理對應。 自動設定提供下列行為:
更新方法取代:每次數據流重新整理時都會取代數據。 會移除目的地中的任何數據。 目的地中的數據會取代為數據流的輸出數據。
受控對應:對應是為您管理的。 當您需要變更數據/查詢以新增另一個數據行或變更數據類型時,當您重新發佈數據流時,會自動調整此變更的對應。 每次對數據流進行變更時,您不需要進入數據目的地體驗,當您重新發佈數據流時,就能夠輕鬆變更架構。
卸除並重新建立數據表:若要允許這些架構變更,請在每個數據流重新整理時卸除並重新建立數據表。 數據流重新整理可能會導致移除先前新增至數據表的關聯性或量值。
注意
目前,僅支援 Lakehouse 和 Azure SQL 資料庫作為數據目的地的自動設定。
![[選擇目的地設定] 視窗的螢幕快照,其中已選取 [使用自動設定] 選項。](media/dataflow-gen2-data-destinations-and-managed-settings/use-automatic-settings.png)
手動設定
透過取消切換 [使用自動設定],您可以完全掌控如何將數據載入資料目的地。 您可以變更來源類型,或排除數據目的地中不需要的任何數據行,來對數據行對應進行任何變更。
![[選擇目的地設定] 視窗的螢幕快照,其中顯示 [使用自動設定選項] 和顯示的各種手動設定。](media/dataflow-gen2-data-destinations-and-managed-settings/use-manual-settings.png)
更新方法
大部分的目的地都支援附加和取代為更新方法。 不過,Fabric KQL 資料庫和 Azure 數據總管不支援取代為更新方法。
取代:在每個數據流重新整理時,您的數據會從目的地卸除,並由數據流的輸出數據取代。
附加:在每個數據流重新整理時,數據流的輸出數據會附加至數據目的地數據表中的現有數據。
發行的架構選項
只有在更新方法取代時,才會套用發佈上的架構選項。 當您附加資料時,無法變更架構。
動態架構:選擇動態架構時,您可以在重新發佈數據流時,允許數據目的地中的架構變更。 因為您不是使用 Managed 對應,因此當您對查詢進行任何變更時,仍然需要更新數據流目的地流程中的數據行對應。 重新整理數據流時,會卸除數據表並重新建立。 數據流重新整理可能會導致移除先前新增至數據表的關聯性或量值。
固定架構:當您選擇固定架構時,就無法進行架構變更。 重新整理數據流時,只會卸除數據表中的數據列,並以數據流的輸出數據取代。 數據表上的任何關聯性或量值都保持不變。 如果您在數據流中對查詢進行任何變更,如果數據流偵測到查詢架構不符合數據目的地架構,則數據流發佈會失敗。 當您不打算變更架構,並將關聯性或量值新增至目的地數據表時,請使用此設定。
注意
將數據載入倉儲時,僅支援固定架構。
![[發佈時架構選項] 選項的螢幕快照,其中已選取 [已修正架構]。](media/dataflow-gen2-data-destinations-and-managed-settings/fixed-schema.png)
每個目的地支持的數據源類型
| 每個記憶體位置支援的數據類型 | 數據流標記Lakehouse | Azure DB (SQL) 輸出 | Azure 資料總管輸出 | Fabric Lakehouse (LH) 輸出 | 網狀架構倉儲 (WH) 輸出 |
|---|---|---|---|---|---|
| 動作 | No | 無 | 無 | 無 | No |
| 任意 | No | 無 | 無 | 無 | No |
| 二進位 | No | 無 | 無 | 無 | No |
| 貨幣 | Yes | .是 | .是 | .是 | No |
| DateTimeZone | Yes | .是 | .是 | 無 | No |
| 期間 | No | 無 | .是 | 無 | No |
| 函式 | No | 無 | 無 | 無 | 否 |
| 無 | No | 無 | 無 | 無 | No |
| Null | No | 無 | 無 | 無 | No |
| Time | Yes | .是 | 無 | 無 | No |
| 類型 | No | 無 | 無 | 無 | No |
| 結構化 (List, Record, Table) | No | 無 | 無 | 無 | No |
進階主題
在載入至目的地之前使用預備
為了增強查詢處理的效能,您可以在數據流 Gen2 內使用暫存,以使用網狀架構計算來執行查詢。
在查詢上啟用預備時(預設行為),您的數據會載入暫存位置,這是只能由數據流本身存取的內部 Lakehouse。
在某些情況下,使用暫存位置可以增強效能,其中將查詢折疊至 SQL 端點的速度比記憶體處理快。
當您將數據載入 Lakehouse 或其他非倉儲目的地時,我們預設會停用暫存功能以改善效能。 當您將數據載入資料目的地時,數據會直接寫入數據目的地,而不使用暫存。 如果您想要針對查詢使用預備,您可以再次啟用它。
若要啟用預備,請選取 [啟用預備] 按鈕,以滑鼠右鍵按下查詢並啟用預備 。 您的查詢接著會變成藍色。
![已強調 [啟用預備] 的查詢下拉功能表螢幕快照。](media/dataflow-gen2-data-destinations-and-managed-settings/disable-staging.png)
將數據載入倉儲
當您將數據載入倉儲時,必須在寫入作業至數據目的地之前暫存。 這項需求可改善效能。 目前僅支援載入與數據流相同的工作區。 請確定已針對載入倉儲的所有查詢啟用預備。
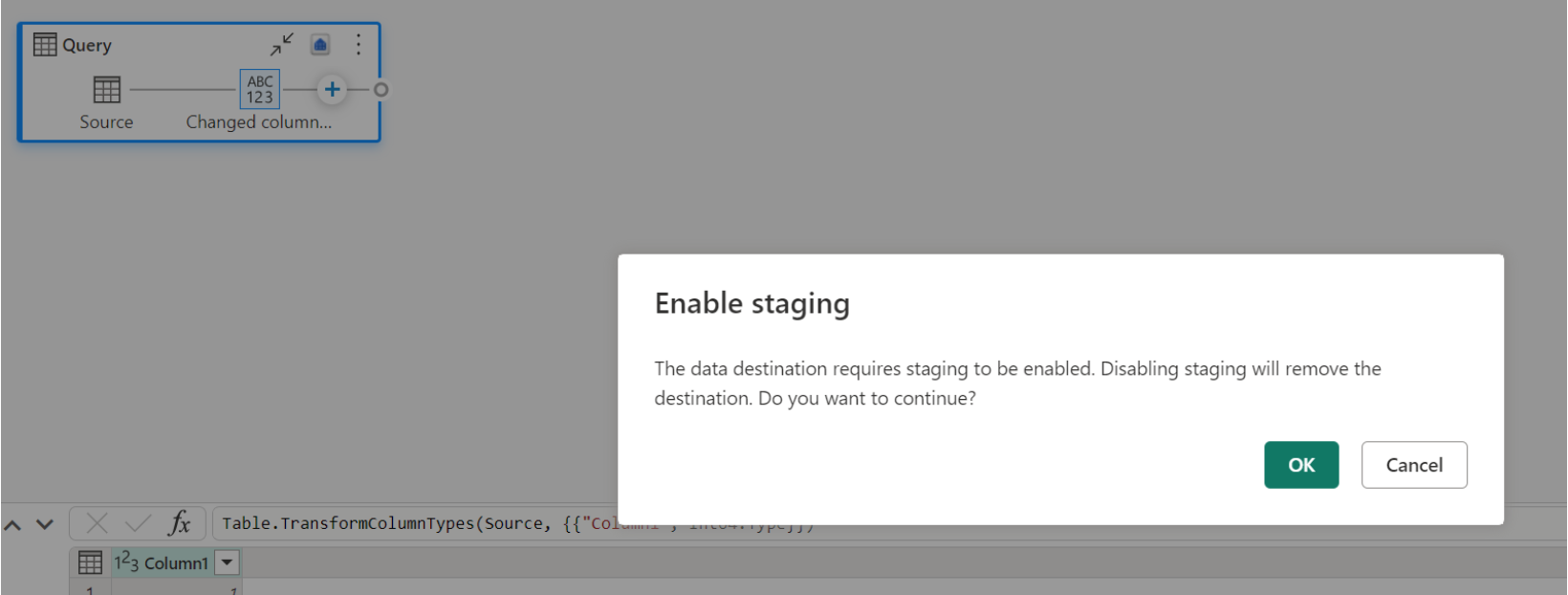
停用暫存時,並選擇 [倉儲] 作為輸出目的地時,您會先收到警告以先啟用預備,再設定數據目的地。
![[新增數據目的地警告] 的螢幕快照。](media/dataflow-gen2-data-destinations-and-managed-settings/add-data-destination.png)
如果您已經有作為目的地的倉儲,並嘗試停用預備,則會顯示警告。 您可以將倉儲移除為目的地,或關閉暫存動作。
Nullable
在某些情況下,當您有可為 Null 的數據行時,Power Query 會偵測為不可為 Null,而且寫入數據目的地時,數據行類型不可為 Null。 在重新整理期間,會發生下列錯誤:
E104100 Couldn’t refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table’s content with new data in a version: #{0}., InnerException: We can’t insert null data into a non-nullable column., Underlying error: We can’t insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can’t insert null data into a non-nullable column.; Message.Format = we can’t insert null data into a non-nullable column.
若要強制可為 Null 的數據行,您可以嘗試下列步驟:
從資料目的地刪除數據表。
從數據流中移除數據目的地。
使用下列 Power Query 程式代碼進入資料流並更新資料類型:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )新增數據目的地。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應