本教學課程需要 15 分鐘,並說明如何使用 Dataflow Gen2 以累加方式將資料匯總到 Lakehouse。
以逐步累積的方式在資料目的地中收集資料需要一個方法,以便將新的或更新的資料載入資料目的地。 您可以使用查詢來根據資料目的地篩選資料,以完成這項技術。 本教學課程示範如何建立資料流程,以將資料從 OData 來源載入 Lakehouse,以及如何將查詢新增至資料流程,以根據資料目的地篩選資料。
本教學課程中的高階步驟如下:
- 建立資料流程,將資料從 OData 來源載入 Lakehouse。
- 將查詢新增至資料流程,以根據資料目的地篩選資料。
- (選擇性) 使用筆記本和管線重新載入資料。
必要條件
您必須有啟用 Microsoft Fabric 的工作區。 如果您還沒有工作區,請參閱建立工作區。 此外,本教學課程假設您在 Dataflow Gen2 中使用圖表檢視。 若要檢查您是否使用圖表檢視,請在頂端功能區中移至 [檢視],並確定已選取 [圖表檢視]。
建立資料流程,將資料從 OData 來源載入 Lakehouse
在本節中,您會建立資料流程,以將資料從 OData 來源載入 Lakehouse。
在工作區中建立一個新的 Lakehouse。
![顯示 [建立 Lakehouse] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/new-lakehouse.png)
在工作區中建立新的 Dataflow Gen2。
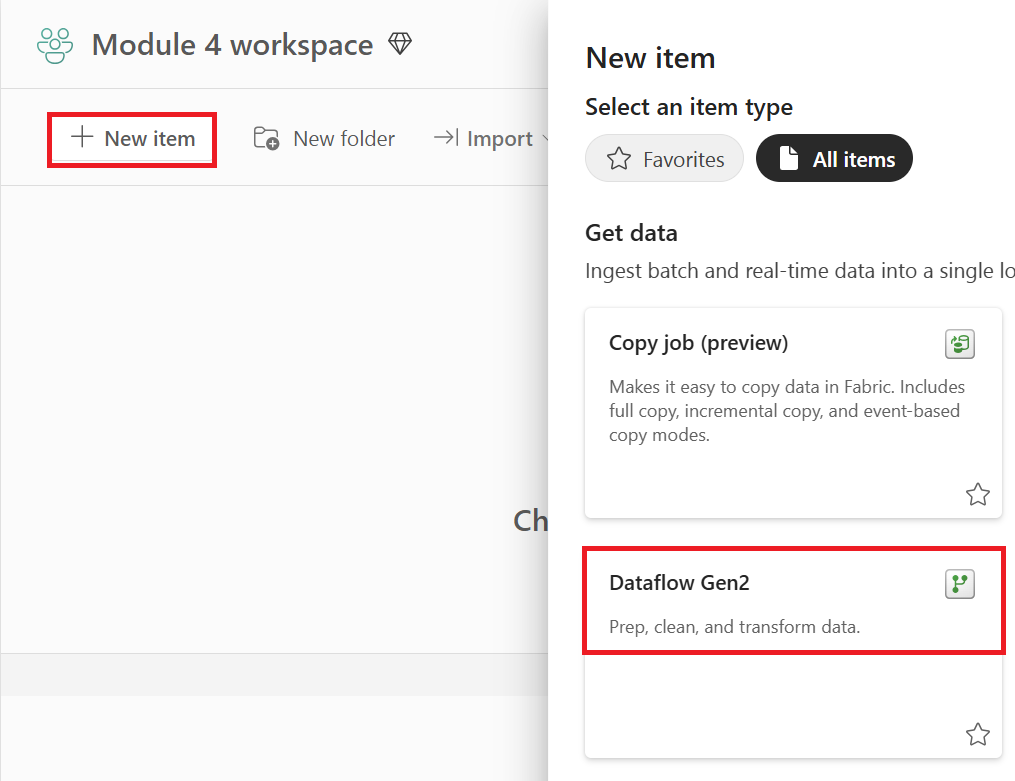
將新的來源新增至資料流程。 選取 OData 來源,然後輸入下列 URL:
https://services.OData.org/V4/Northwind/Northwind.svc![顯示 [取得資料] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/get-data.png)
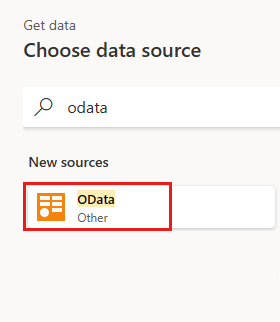

請選取 Orders 資料表,然後選取 [下一步]。
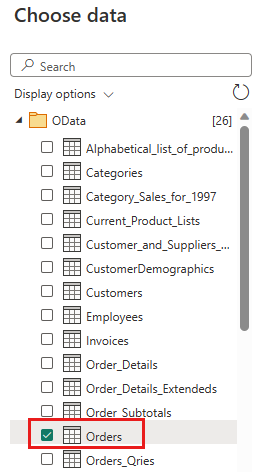
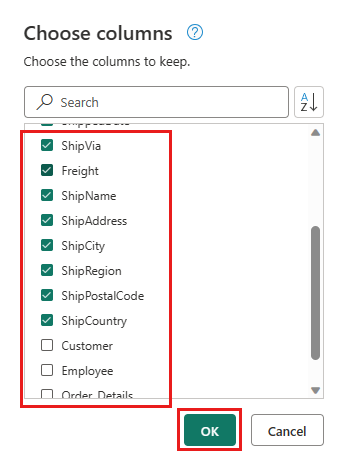
請選擇要保留的下列欄位:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
將
OrderDate、RequiredDate和ShippedDate的資料類型變更為datetime。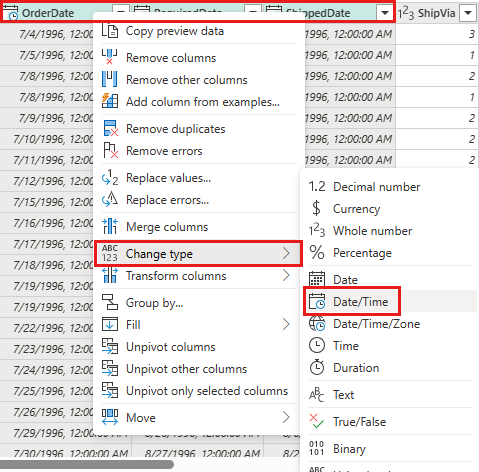
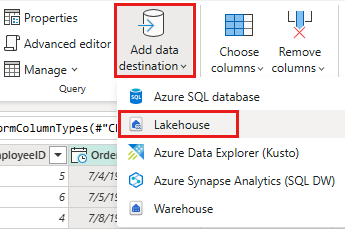
使用下列設定來設定 Lakehouse 的資料目的地:
- 資料目的地:
Lakehouse - Lakehouse: 選取您在步驟 1 中建立的 Lakehouse。
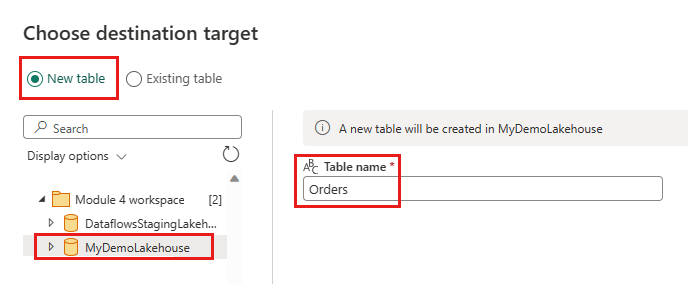
- 新資料表名稱:
Orders - 更新方法:
Replace
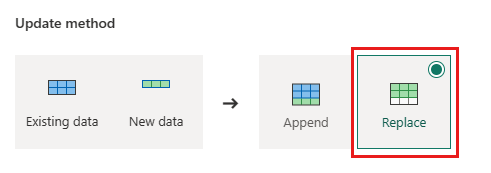
- 資料目的地:
選取下一步並發布資料流程。
![顯示 [發佈資料流程] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/publish-dataflow.png)



您現在已建立資料流程,以將資料從 OData 來源載入 Lakehouse。 下一節會使用此資料流程,將查詢新增至資料流程,以根據資料目的地篩選資料。 之後,您可以使用資料流程,使用筆記本和管線來重新載入資料。
將查詢新增至資料流程,以根據資料目的地篩選資料
本節會將查詢加入至資料流程,以目的地 Lakehouse 中的資料為依據篩選資料。 此查詢會在資料流程重新整理開始時取得 lakehouse 中的最大值 OrderID,並使用最大 OrderId 僅從來源取得具有更高 OrderId 的訂單,以便附加到您的資料目標。 這假設訂單會以 OrderID 的遞增排序新增至來源。 如果情況並非如此,您可以使用不同的資料行來篩選資料。 例如,您可以使用 OrderDate 資料行來篩選資料。
注意
從數據源接收數據之後,就會在 Fabric 內套用 OData 篩選條件,不過,對於 SQL Server 等資料庫來源,篩選條件會套用在提交至後端數據源的查詢中,而且只會將篩選的數據列傳回至服務。
重新整理資料流程之後,請重新開啟您在上一節中建立的資料流程。
建立名為
IncrementalOrderID的新查詢,並從您在上一節中建立的 Lakehouse 中 Orders 資料表取得資料。
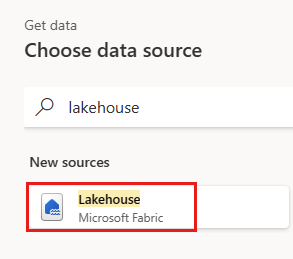
顯示取得訂單資料表的 Lakehouse 螢幕擷取畫面。
停用此查詢的預備過程。
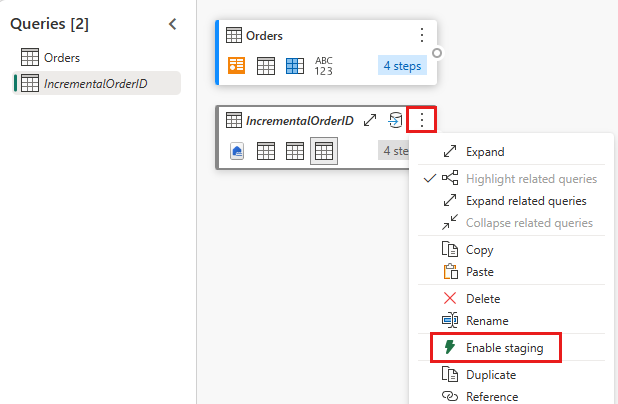
在資料預覽中,以滑鼠右鍵按一下
OrderID資料行,然後選取 [向下切入]。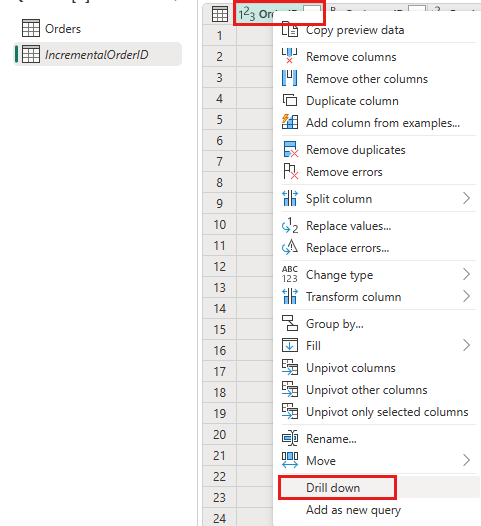
從功能區中,選取 [列表工具] -> [統計資料] -> [最大值]。
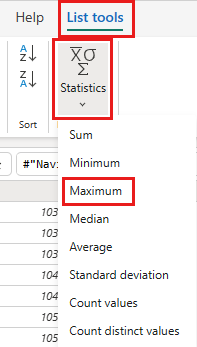
您現在有一個查詢,可以傳回 Lakehouse 中的最大 OrderID。 此查詢可用於篩選 OData 來源的資料。 下一節會將查詢新增至資料流程,以根據 Lakehouse 中的 OrderID 上限篩選 OData 來源的資料。
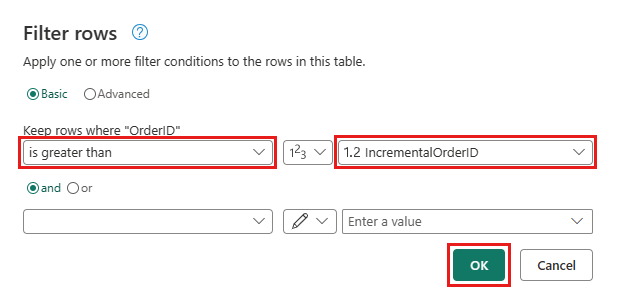
返回 Orders 查詢,然後新增步驟來篩選資料。 使用下列設定:
- 欄:
OrderID - 作業:
Greater than - 值:參數
IncrementalOrderID

- 欄:
透過確認下列對話方塊,允許合併 OData 來源和 Lakehouse 的資料:
![顯示 [允許合併資料] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/combine-datasources-confirmation.png)
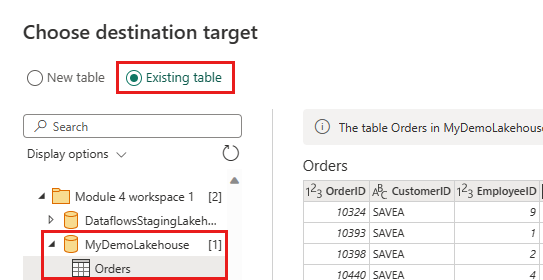
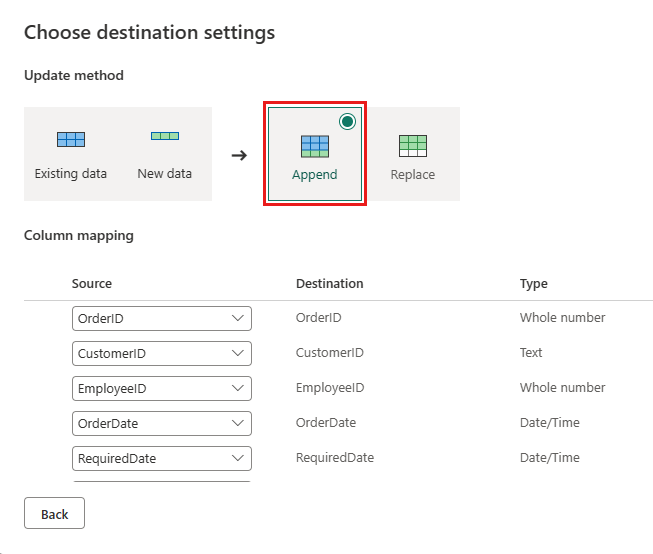
更新資料目的地以使用下列設定:
- 更新方法:
Append

- 更新方法:
發布資料流程。
您的資料流程現在包含一個查詢,根據 Lakehouse 中的 OrderID 上限篩選 OData 來源的資料。 這表示只有新的或更新的資料會載入湖倉。 下一節會使用資料流,以使用筆記本和管線重新載入資料。
(選擇性) 使用筆記本和管線重新載入資料
您可以選擇性地使用筆記本和管線來重新載入特定資料。 在筆記本中使用自訂的 Python 程式碼,您可以移除 Lakehouse 中的舊資料。 接著,建立一個管線,先執行筆記本,然後依序執行資料流程,即可將資料從 OData 來源重新載入至資料湖屋。 筆記本支援多種語言,但本教學課程使用 PySpark。 Pyspark 是適用於 Spark 的 Python API,在本教學課程中會用於執行 Spark SQL 查詢。
在工作區中建立新的筆記本。
請將下列 PySpark 程式碼新增至筆記本:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))執行筆記本以確認資料已從 Lakehouse 中移除。
在工作區中建立新的管線。
將新的筆記本活動新增到管線中,然後選擇您在前一個步驟中創建的筆記本。
![顯示 [新增筆記本活動] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/add-notebook-activity.png)
![顯示 [選取筆記本] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/select-notebook.png)
在管線中新增一個新的資料流程活動,然後選擇您在上一節中建立的資料流程。
![顯示 [新增資料流程活動] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/add-dataflow-activity.png)
![顯示 [選取資料流程] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/select-dataflow.png)
使用成功觸發器將筆記本活動連結至資料流活動。
![顯示 [連線活動] 對話方塊的螢幕擷取畫面。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/connect-activities.png)
儲存並執行管線。
![顯示 [執行管道] 對話方塊的截圖。](media/tutorial-setup-incremental-refresh-with-dataflows-gen2/run-pipeline.png)

您現在擁有一個管線,可以從湖泊之家移除舊資料,並將資料從 OData 來源重新載入至湖泊之家。 透過此設定,您可以定期將 OData 來源的數據重載至 Lakehouse。