機器學習模型是一種訓練用來辨識特定模式的檔案。 你在一組資料上訓練模型,並提供一個演算法,用來推理並從該資料集中學習。 訓練模型後,你可以用它推理它從未見過的資料,並對這些資料做出預測。
在 MLflow 中,機器學習模型可以包含多個模型版本。 在這裡,每個版本都可以代表一個模型迭代。 在本文中,您將學習如何與機器學習模型互動,以追蹤並比較模型迭代。
在本文中,您將學習如何:
- 在 Microsoft Fabric 中建立機器學習模型
- 管理與追蹤模型版本
- 比較不同版本的模型效能
- 應用模型進行評分與推論
建立機器學習模型
你可以從 Fabric UI 建立機器學習模型,或用 MLflow API 程式化建立。 在 MLflow 中,模型使用標準的封裝格式,可搭配多種下游工具使用,包括 Apache Spark 上的批次推論。 這種格式保存了不同「版本」的模型,讓不同的下游工具能理解。
要從使用者介面建立機器學習模型:
- 選擇現有的資料科學工作區,或 建立新的工作區。
- 透過工作區或使用「建立」按鈕建立新項目:
- 工作區
- 選取您的工作區。
- 選擇 新增專案。
- 在分析與訓練資料中選擇機器學習模型。
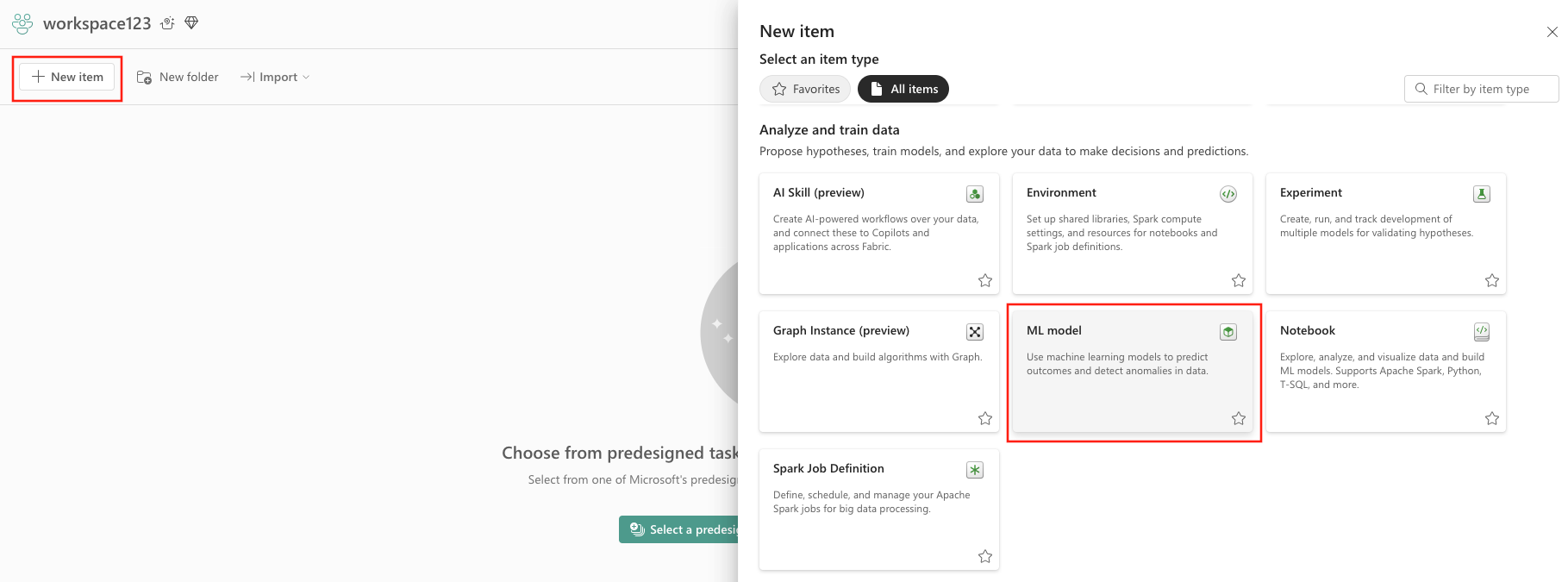
- 建立按鈕:
- 選取 建立,您可以在垂直功能表中找到 ...。
- 在資料科學中選擇機器學習模型。

- 選取 建立,您可以在垂直功能表中找到 ...。
- 工作區
- 建立模型後,你可以開始新增模型版本來追蹤運行指標和參數。 註冊或儲存實驗運行到現有模型。



你也可以直接從你的編輯體驗中,使用 mlflow.register_model() API 來建立機器學習模型。 如果註冊的機器學習模型沒有該名稱,API 會自動建立它。
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
在機器學習模型中管理版本
機器學習模型包含多個模型版本,方便簡化追蹤與比較。 在模型中,資料科學家可以瀏覽不同模型版本,探索底層參數與指標。 資料科學家也能比較不同模型版本,以判斷更新模型是否能產生更好的結果。
Note
有了 Fabric 對 MLflow 3 的支援,你使用 mlflow.<flavor>.log_model(model, name="...") 記錄的每個模型都會建立一個與其來源執行、參數、指標、資料集和環境連結的 LoggedModel 實體。 你可以從實驗頁面開啟一個 LoggedModel,並將其註冊為新的機器學習模型或現有模型的新版本。 如需詳細資訊,請參閱Fabric 資料科學中的 MLflow 3。
追蹤機器學習模型
機器學習模型版本代表一個已註冊以進行追蹤的個別模型。
![]()
每個型號版本包含以下資訊:
| 房產 | Description |
|---|---|
| 建立時間 | 模型創建的日期與時間。 |
| 運行名稱 | 用於創建此特定模型版本的實驗識別碼。 |
| 超參數 | 儲存為鍵值對。 索引鍵和值都是字串。 |
| Metrics | 執行儲存為鍵值對的指標。 值為數值。 |
| 模型架構/簽名 | 模型輸入與輸出的描述。 |
| 已記錄的檔案 | 任何格式的已記錄檔案。 例如,您可以記錄影像、環境、模型和資料檔案。 |
| 標籤 | 自訂元資料以鍵值對的形式附加於執行。 學習如何套用標籤。 |
將標籤套用到機器學習模型
模型版本的 MLflow 標籤讓使用者能將自訂的元資料附加到 MLflow 模型登錄中註冊模型的特定版本。 這些標籤以鍵值對形式儲存,有助於組織、追蹤及區分模型版本,使管理模型生命週期更為簡便。 標籤可用來表示模型的目的、部署環境或其他相關資訊,促進團隊內更有效率的模型管理與決策。
此程式碼示範如何使用 Scikit-learn 訓練 RandomForestRegressor 模型,使用 MLflow 記錄模型與參數,然後以自訂標籤在 MLflow 模型登錄庫中註冊模型。 這些標籤提供有用的元資料,如專案名稱、部門、團隊及專案季度,方便管理與追蹤模型版本。
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
套用標籤後,你可以直接在模型版本詳情頁面查看。 此外,標籤可隨時新增、更新或移除。

比較與過濾機器學習模型
為了比較和評估機器學習模型版本的品質,你可以比較選定版本間的參數、指標和元資料。
視覺化比較機器學習模型
你可以在現有模型中視覺化比較運行。 視覺比較讓使用者能輕鬆瀏覽並跨越多個版本進行排序。

要比較運行結果,你可以:
- 選擇包含多個版本的現有機器學習模型。
- 選擇 「檢視 」標籤,然後導覽到 模型清單 檢視。 您也可以直接從詳細檢視中選擇 「查看模型清單 」選項。
- 你可以自訂表格中的欄位。 展開 「自訂欄位」 窗格。 接著,你可以選擇你想看到的屬性、指標、標籤和超參數。
- 最後,你可以在指標比較窗格中選擇多個版本,以比較結果。 從這個窗格,你可以自訂圖表標題、視覺化類型、X 軸、Y 軸等。
使用 MLflow API 比較機器學習模型
資料科學家也可以利用 MLflow 在工作空間內儲存的多個模型中搜尋。 請造訪 MLflow 文件 ,探索其他用於模型互動的 MLflow API。
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
應用機器學習模型
一旦你在資料集中訓練模型,就可以將該模型套用到它從未見過的資料來產生預測。 我們稱這種模型使用技術為評分 或推論。
Fabric 支援多種方法來應用已訓練的模型:
- 批次計算評分 使用 Apache Spark 將模型應用於大規模資料集。 這非常適合對歷史或排程資料產生預測。
- 即時評分 將模型部署到端點進行按需預測,對需要即時結果的應用非常有用。
要開始應用你的模型,請選擇最適合你情境的方法: