適用於:✅ Microsoft Fabric 中的倉儲
本文重點介紹 Fabric Data Warehouse 架構中推動其效能、可擴展性及成本效益的特色與創新。
Fabric Data Warehouse 以具備未來發展潛力的架構運行於整合資料平台上。 透過開放的 Delta 儲存格式與 OneLake 整合,您在 Fabric Data Warehouse 中的資料已準備好進行分析。
高階結構

Fabric Data Warehouse 專為大規模分析而設計,包含以下組件:
| 建築單元 | 說明 |
|---|---|
| 統一查詢優化器 | 為分散式雲端環境生成最佳執行計畫,無論使用者自創的 SQL 查詢品質如何。 |
| 分散式查詢處理 | 支援大規模平行查詢執行,並具備快速自動擴展的雲端基礎設施,即時提供查詢所需的運算資源。 獨立的 SELECT 與 DML 工作負載使用不同的池,以實現高效且隔離的執行。 |
| 查詢執行引擎 | 一個基於 SQL 的引擎,能以快速效能與高並發性執行大量資料的分析查詢。 |
| 元資料與交易管理 | 元資料存在於前端、後端,以及本地 SSD 快取和遠端 OneLake 儲存中。 支援並行 交易並確保符合 ACID 規範。 |
| OneLake 的儲存 | 日誌結構化表格採用 開放式 Delta 表格格式,這是一種湖屋模型,具備安全的開放儲存。 |
| 布料平台 | Fabric 平台提供 統一的認證與安全模型、 監控與 稽核功能。 您的 Fabric Data Warehouse 會自動開放給其他 Fabric 平台服務,以滿足業務需求,包括 Power BI、Data Factory 中的資料管線、Real-Time Intelligence 等。 |
統一查詢優化引擎
Fabric Data Warehouse 中的統一查詢優化器是決定執行 SQL 查詢最聰明方式的引擎。
當你提交查詢時,統一的查詢優化器會檢視可能的執行方式:如何連接資料表、資料移動位置,以及如何使用像 CPU、記憶體和網路等資源。 統一查詢優化器不只是選擇第一個選項,而是在有限時間內,透過評估這些因素的成本、可用元資料和統計,選擇最優方案。
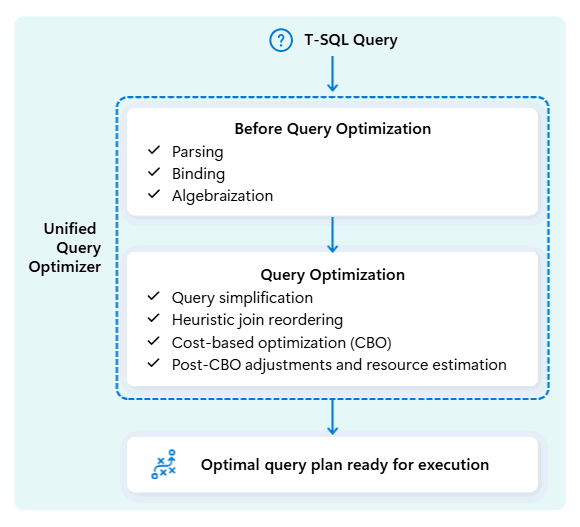
在優化查詢執行計畫時,統一查詢優化器會一次性考量所有因素:查詢的形狀、資料表的資料分布,以及移動資料與本地處理的成本。 統一的查詢優化器可以做出明智的取捨,例如決定廣播一個小資料表是否比洗牌一個大資料表更便宜。 這意味著減少不必要的資料洗牌、更好的運算效率,以及更快的效能,即使是複雜或寫得不佳的 T-SQL 查詢也能如此。
穩定的效能不需要開發者花時間手動調整 T-SQL 查詢。 例如,你不必手動決定查詢的最佳 JOIN 順序。 如果你的 SQL 先列出大型資料表,再列出較小且高度選擇性的資料表,優化器就能自動切換位置以提升效能。 它會用較小的表格作為配對列的起點(「建置」側),而較大的表格則作為搜尋的起點(「探針」側,已檢查匹配)。 此方法可減少記憶體使用、減少資料移動並提升平行性,同時仍能提供準確的結果。
統一查詢優化器會隨著工作負載演進,持續從過去的查詢執行中學習,精進優化演算法以提供最佳效能。 使用者能自動享受快速執行查詢,無論複雜度如何,且無需介入。
分散式查詢處理引擎
在 Fabric Data Warehouse 中,分散式查詢處理引擎將運算資源分配給查詢計畫中的任務。 分散式查詢處理引擎能在計算節點間排程任務,使每個節點執行部分查詢計畫,實現平行執行以提升效能。 對於大型資料集的複雜報告,分散式查詢處理能帶來好處。
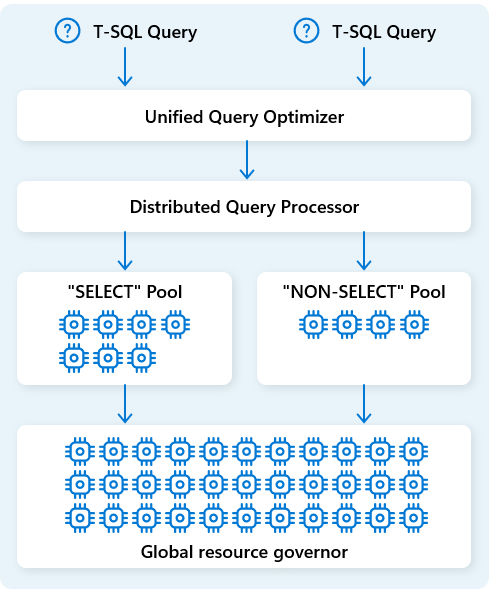
為了進一步優化資源,分散式查詢處理引擎將運算資源分為兩個池:用於 SELECT 查詢與資料擷取任務(NON-SELECT 查詢)。 每個工作負載會根據需要獲得專用資源。 這代表,例如,你的夜間 ETL 工作不會延誤早晨的儀表板。
透過雲端快速節點配置,分散式查詢處理引擎會自動根據查詢量、資料大小及查詢複雜度的變化,調整計算資源的規模。 Fabric Data Warehouse 具備多拍字節規模的小型資料集或資料平行處理能力。
查詢執行引擎
查詢執行引擎是一個程序,負責執行分配給各個計算節點的分散式執行計畫部分。 查詢執行引擎基於 SQL Server 與 Azure SQL Database 相同的引擎,採用 批次模式 執行與 欄式 資料格式,以最佳成本進行大數據的高效分析。
查詢執行引擎直接讀取 Fabric OneLake 中儲存的 Delta Parquet 檔案資料,並利用多層快取(記憶體與 SSD)以加速查詢效能並確保查詢以最佳速度執行。 查詢執行引擎處理記憶體中的資料,並在必要時從 SSD 快取或 OneLake 儲存中擷取額外資料。
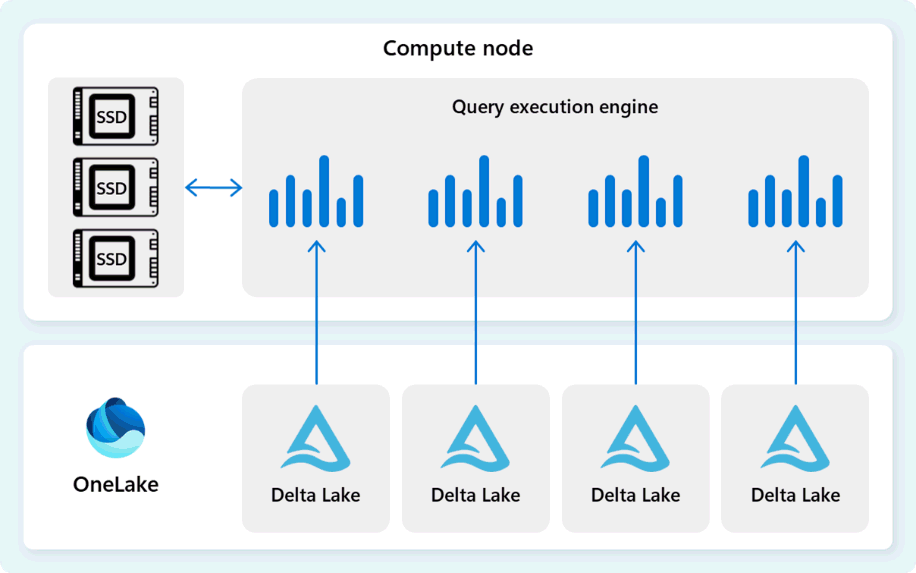
在處理資料時,查詢執行引擎會進行欄位和列群組的消除,以跳過與查詢無關的區段。 此優化減少從檔案與記憶體快取掃描的資料量,有助於降低資源使用並提升整體執行時間。
查詢執行引擎擅長過濾與彙整數十億筆資料,支援現代資料倉儲解決方案中使用的通用資料分析模式。 批次處理模式利用現代 CPU 平行處理多列的能力,大幅降低開銷,並使查詢速度比傳統逐列執行快數百倍。
元資料與交易管理
倉庫引擎利用元資料描述資料表結構、檔案組織、版本歷史及交易狀態。 這些元資料讓倉儲引擎能有效管理與查詢資料。 Fabric Data Warehouse 提供穩健且全面的元資料與交易管理架構,擴展 OLTP 交易管理器,以協調高度同步的元資料操作並確保 ACID 合規。
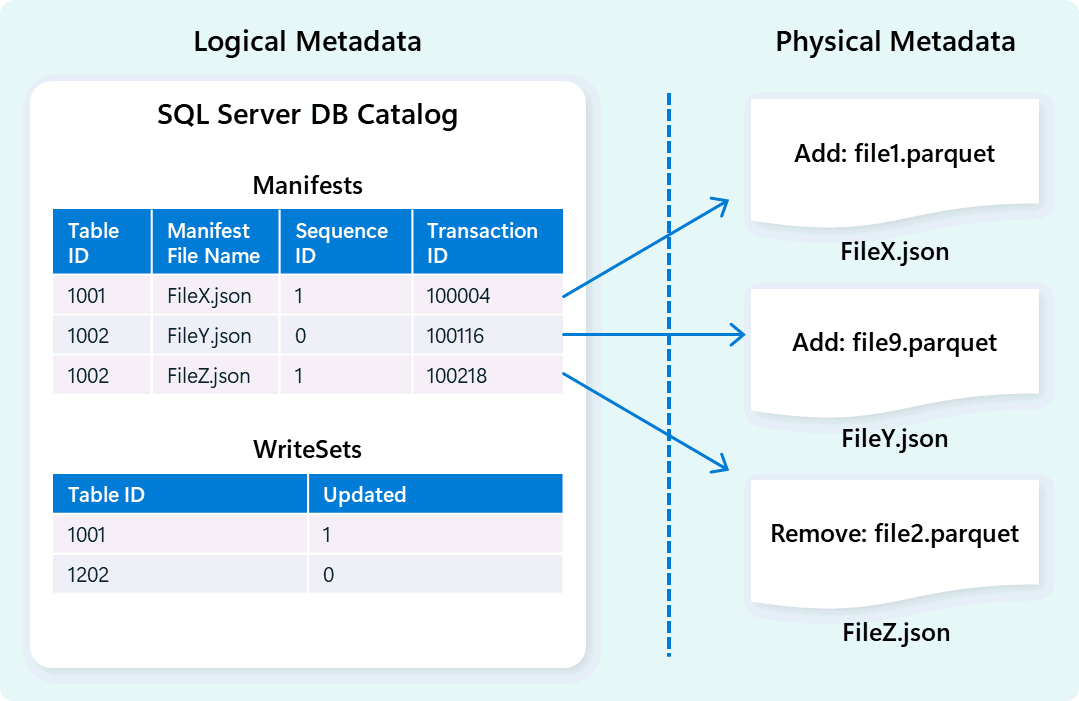
此設計能快速且可靠地導航交易狀態,支援高並發性工作負載同時確保一致性。
儲存與資料擷取
Fabric Data Warehouse 採用湖屋架構,採用開源 Delta 格式,實現可擴展、安全且高效能的儲存。 Delta 表格格式支援資料版本控制,能透過 時間旅行 與 零複製複製 即刻存取歷史快照,從而保障測試的安全性並輕鬆回滾操作。 使用者資料儲存在 OneLake 中,使所有 Fabric 引擎能有效存取共享資料而無需冗餘。
在此基礎上,Fabric Data Warehouse 旨在提供最佳的資料擷取效能,並著重於簡易與彈性。 該引擎透過 自動資料壓縮有效管理資料表資料儲存,將碎片檔案整合於背景,減少不必要的資料掃描。 其智慧資料分發方法將資料劃分並組織至微分割區格,以提升平行處理並提升查詢結果。 這些功能可自主運作,無需手動調整。