體驗特定災害復原指導
本檔提供在發生區域性災害時復原 Fabric 數據的經驗特定指引。
範例案例
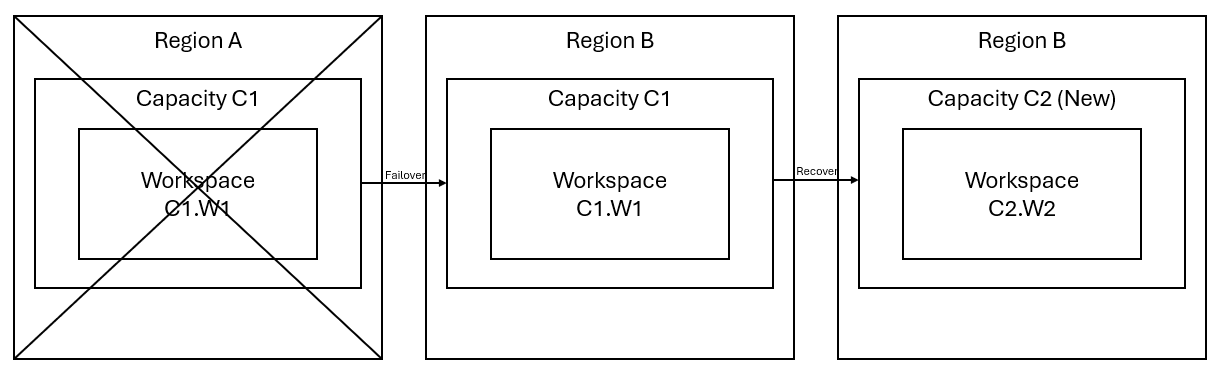
本檔中的一些指引區段會使用下列範例案例來說明和說明。 視需要參考此案例。
假設您在區域 A 中具有工作區 W1 的容量 C1。 如果您已 開啟容量 C1 的災害復原 ,OneLake 數據將會復寫到區域 B 中的備份。如果區域 A 面臨中斷,C1 中的網狀架構服務會故障轉移至區域 B。
下圖說明這個案例。 左側方塊會顯示中斷的區域。 中間方塊代表故障轉移後數據的繼續可用性,右側方塊會顯示客戶執行還原其服務至完整功能之後的完整涵蓋情況。
以下是一般復原方案:
在新區域中建立新的 Fabric 容量 C2。
在 C2 中建立新的 W2 工作區,包括其對應專案,其名稱與 C1 相同。W1。
從中斷的 C1 複製數據。W1 到 C2。W2.
請遵循每個元件的專用指示,將專案還原至其完整功能。
體驗特定的復原方案
下列各節提供每個網狀架構體驗的逐步指南,以協助客戶完成復原程式。
資料工程
本指南會逐步引導您完成 資料工程師 體驗的復原程式。 其涵蓋 Lakehouse、Notebook 和 Spark 作業定義。
Lakehouse
來自原始區域的 Lakehouses 仍然無法供客戶使用。 若要復原 Lakehouse,客戶可以在工作區 C2 中重新建立它。W2. 我們建議使用兩種方法來復原 Lakehouse:
方法 1:使用自定義腳本複製 Lakehouse Delta 數據表和檔案
客戶可以使用自定義 Scala 腳本重新建立 Lakehouse。
在新建立的工作區 C2 中建立 Lakehouse (例如 LH1)。W2.
在工作區 C2 中建立新的筆記本。W2.
若要從原始 Lakehouse 復原數據表和檔案,您必須使用 ABFS 路徑來存取數據(請參閱 連線 至 Microsoft OneLake)。 您可以使用下列程式代碼範例(請參閱 筆記本中的 Microsoft Spark 公用程式簡介),從原始 Lakehouse 取得檔案和數據表的 ABFS 路徑。 (取代 C1。具有實際工作區名稱的 W1)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')使用下列程式代碼範例,將數據表和檔案複製到新建立的 Lakehouse。
針對 Delta 數據表,您必須一次複製一個數據表,才能在新 Lakehouse 中復原。 在 Lakehouse 檔案的情況下,您可以使用單一執行的所有基礎資料夾來複製完整的檔案結構。
請連絡支援小組以取得腳本中所需的故障轉移時間戳。
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)執行腳本之後,數據表就會出現在新的 Lakehouse 中。
方法 2:使用 Azure 儲存體 Explorer 複製檔案和數據表
若要只從原始 Lakehouse 復原特定的 Lakehouse 檔案或數據表,請使用 Azure 儲存體 Explorer。 如需詳細步驟,請參閱整合 OneLake 與 Azure 儲存體 Explorer。 針對大型數據大小,請使用 方法 1。
注意
上述的兩種方法會復原 Delta 格式數據表的元數據和數據,因為元數據是與 OneLake 中的數據共置並儲存。 對於使用 Spark 資料定義語言 (DDL) 文稿/命令所建立的非差異格式數據表(e.g. CSV、Parquet 等),使用者須負責維護和重新執行 Spark DDL 腳本/命令來復原它們。
Notebook
來自主要區域的筆記本仍無法供客戶使用,且筆記本中的程式代碼不會復寫至次要區域。 若要復原新區域中的 Notebook 程式代碼,有兩種方法可以復原 Notebook 程式代碼內容。
方法 1:使用 Git 整合的使用者管理備援 (公開預覽版)
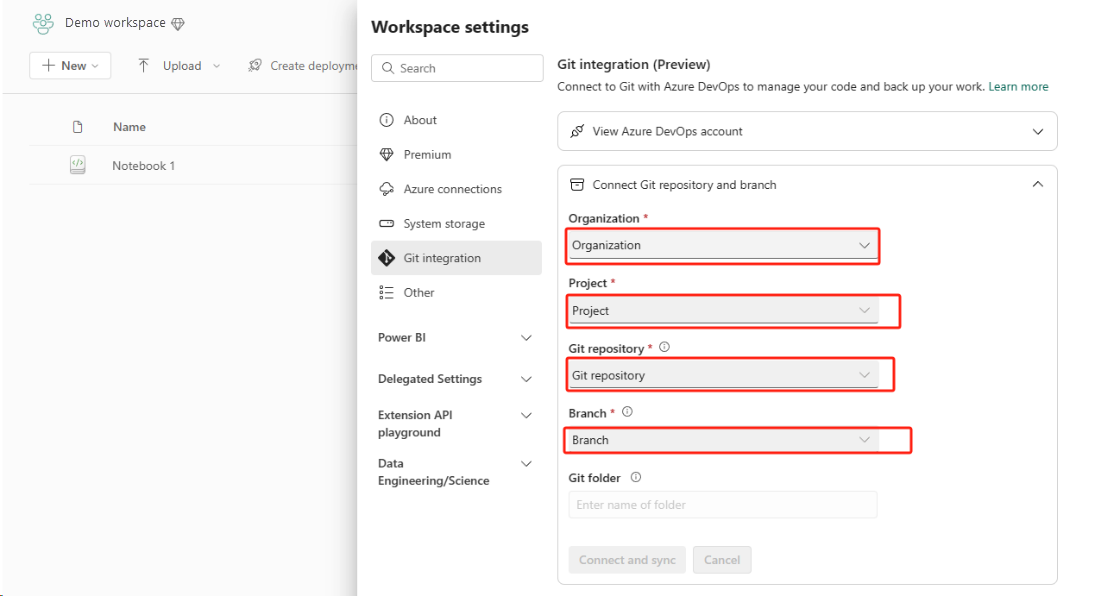
讓此作業變得簡單且快速的最佳方式是使用 Fabric Git 整合,然後將筆記本與您的 ADO 存放庫同步處理。 服務故障轉移至另一個區域之後,您可以使用存放庫在您所建立的新工作區中重建筆記本。
設定 Git 整合,然後選取 [連線],然後與 ADO 存放庫同步。
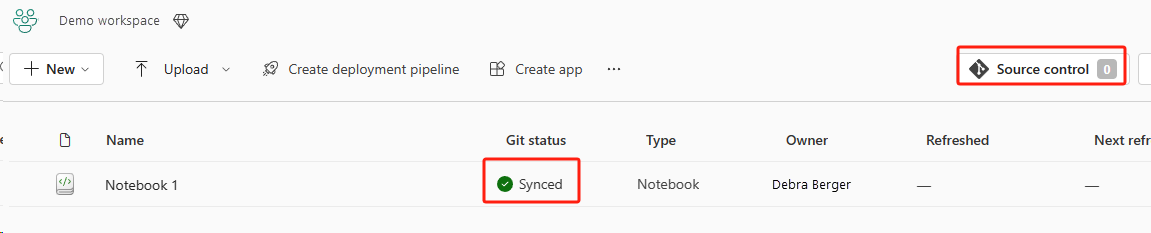
下圖顯示已同步的筆記本。
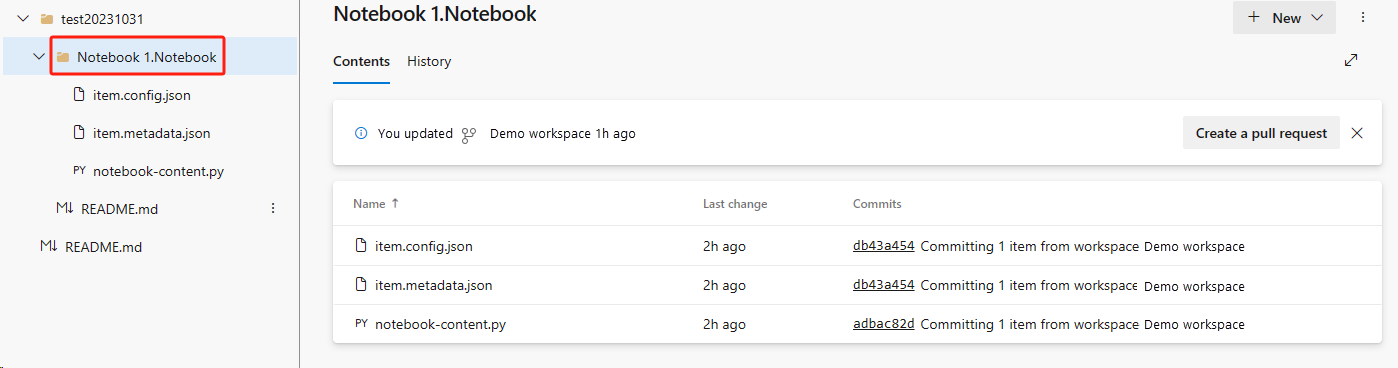
從 ADO 存放庫復原筆記本。
在新建立的工作區中,再次連線到您的 Azure ADO 存放庫。
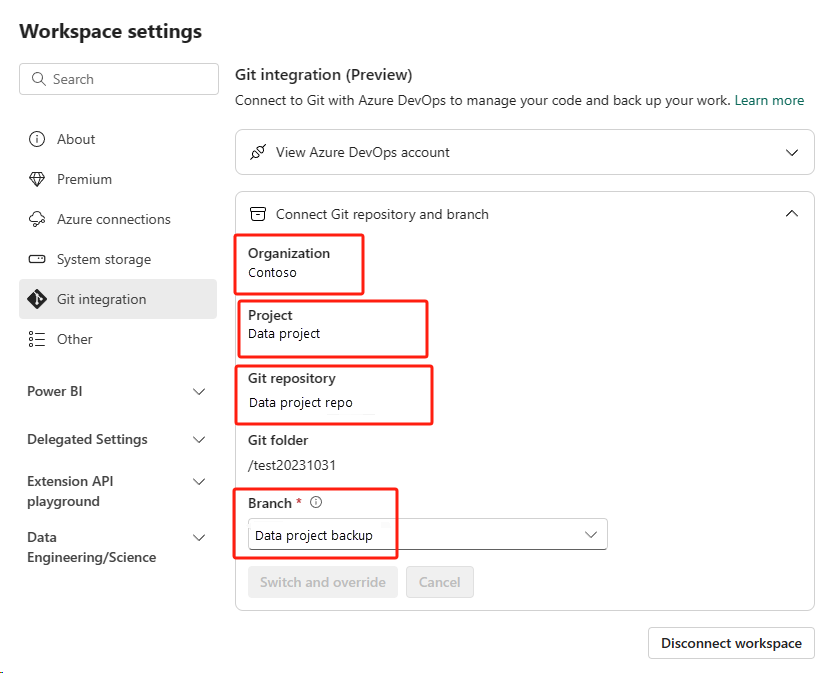
選取 [原始檔控制] 按鈕。 然後選取存放庫的相關分支。 然後選取 [ 全部更新]。 原始筆記本隨即出現。
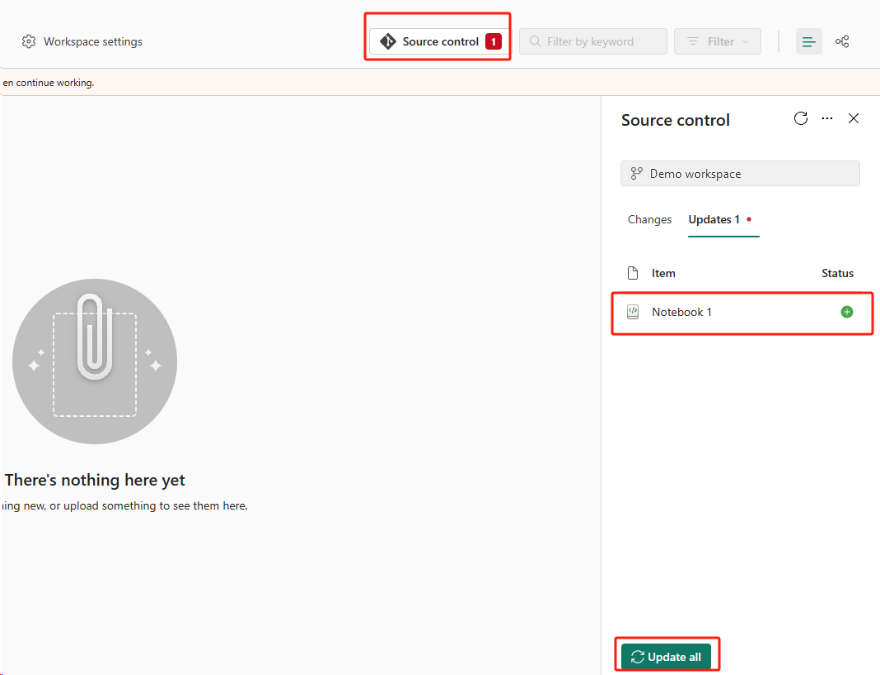
如果原始筆記本有預設的 Lakehouse,用戶可以參考 Lakehouse 區段 來復原 Lakehouse,然後將新復原的 Lakehouse 連接到新復原的筆記本。
Git 整合不支援在筆記本資源總管中同步處理檔案、資料夾或筆記本快照集。
如果原始筆記本在筆記本資源總管中有檔案:
請務必將檔案或資料夾儲存到本機磁碟或其他位置。
將檔案從本機磁碟或雲端磁碟驅動器重新上傳至復原的筆記本。
如果原始筆記本有筆記本快照集,也請將筆記本快照集儲存至您自己的版本控制系統或本機磁碟。
如需 Git 整合的詳細資訊,請參閱 Git 整合簡介。
方法 2:備份程式代碼內容的手動方法
如果您沒有採用 Git 整合方法,則可以將最新版本的程式代碼、檔案儲存在資源總管中,以及 Git 等版本控制系統中的筆記本快照集,並在災害發生後手動復原筆記本內容:
使用「匯入筆記本」功能匯入您想要復原的筆記本程序代碼。
匯入之後,請移至所需的工作區(例如“C2”。W2“) 以存取它。
如果原始筆記本有預設的 Lakehouse,請參閱 Lakehouse 區 段。 然後將新復原的湖屋(與原始預設湖屋的內容相同)連接到新復原的筆記本。
如果原始筆記本在資源總管中有檔案或資料夾,請重新上傳儲存在使用者版本控制系統中的檔案或資料夾。
Spark 作業定義
主要區域的 Spark 作業定義 (SJD) 仍然無法供客戶使用,筆記本中的主要定義檔案和參考檔案將會透過 OneLake 複寫到次要區域。 如果您想要復原新區域中的 SJD,您可以遵循下列手動步驟來復原 SJD。 請注意,SJD 的歷史執行將不會復原。
您可以從原始區域複製程序代碼,方法是使用 Azure 儲存體 Explorer,並在災害發生後手動重新連線 Lakehouse 參考,以復原 SJD 專案。
在新工作區 C2 中建立新的 SJD 專案(例如 SJD1)。W2,其設定和設定與原始 SJD 專案相同(例如語言、環境等)。
使用 Azure 儲存體 總管,將 Libs、Mains 和 Snapshots 從原始 SJD 專案複製到新的 SJD 專案。
程式代碼內容會出現在新建立的 SJD 中。 您必須手動將新復原的 Lakehouse 參考新增至作業(請參閱 Lakehouse 復原步驟)。 用戶必須手動重新輸入原始命令行自變數。
現在您可以執行或排程新復原的 SJD。
如需 Azure 儲存體 Explorer 的詳細資訊,請參閱整合 OneLake 與 Azure 儲存體 Explorer。
資料科學
本指南會逐步引導您完成 資料科學 體驗的復原程式。 其涵蓋 ML 模型和實驗。
ML 模型和實驗
資料科學 主要區域中的專案仍無法供客戶使用,而且 ML 模型和實驗中的內容和元數據將不會復寫到次要區域。 若要在新的區域中完全復原它們,請將程式代碼內容儲存在版本控制系統中(例如 Git),並在災害發生後手動重新執行程式代碼內容。
復原筆記本。 請參閱 Notebook 復原步驟。
設定、過去執行計量,且元數據不會復寫到配對的區域。 您必須重新執行數據科學程序代碼的每個版本,才能在災害之後完整復原 ML 模型和實驗。
資料倉儲
本指南會逐步引導您完成數據倉儲體驗的復原程式。 它涵蓋倉儲。
倉庫
來自原始區域的倉儲仍無法供客戶使用。 若要復原倉儲,請使用下列兩個步驟。
在工作區 C2 中建立新的過渡湖屋。W2,用於您要從原始倉儲複製的數據。
利用倉儲總管和 T-SQL 功能填入倉儲的差異數據表(請參閱 Microsoft Fabric 中的數據倉儲中的數據表)。
注意
建議您根據您的開發做法,將倉儲程式代碼(架構、數據表、檢視、預存程式、函式定義和安全性代碼)版本設定並儲存在安全的位置(例如 Git)。
透過 Lakehouse 和 T-SQL 程式代碼的數據擷取
在新建立的工作區 C2 中。W2:
在 C2 中建立臨時湖屋 「LH2」。W2.
遵循 Lakehouse 復原步驟,從原始倉儲復原臨時湖屋中的 Delta 數據表復原。
在 C2 中建立新的倉儲 「WH2」。W2.
連線 倉庫總管中的臨時湖屋。
根據您要如何在數據匯入之前部署數據表定義,用於匯入的實際 T-SQL 可能會有所不同。 您可以使用 INSERT INTO、SELECT INTO 或 CREATE TABLE AS SELECT 方法,從 Lakehouses 復原倉儲數據表。 在範例中,我們會使用 INSERT INTO 類別。 (如果您使用下列程式代碼,請將範例取代為實際的數據表和資料行名稱)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GO最後,使用網狀架構倉儲變更應用程式中 連接字串。
注意
對於需要跨區域災害復原和完全自動化商務持續性的客戶,我們建議在個別網狀架構區域中保留兩個網狀架構倉儲設定,並透過定期部署和數據擷取這兩個月臺來維護程式代碼和數據同位。
Data Factory
來自主要區域的 Data Factory 專案仍然無法供客戶使用,而且數據管線或數據流 gen2 專案中的設定和設定將不會復寫到次要區域。 若要在發生區域失敗時復原這些專案,您必須從不同區域重新建立另一個工作區中的 資料整合 專案。 下列各節概述詳細數據。
數據流 Gen2
如果您想要在新區域中復原數據流 Gen2 專案,您必須將 PQT 檔案匯出至 Git 等版本控制系統,然後在災害發生後手動復原數據流 Gen2 內容。
從您的數據流 Gen2 專案中,於 Power Query 編輯器的 [首頁] 索引標籤中,選取 [匯出範本]。
![顯示 Power Query 編輯器的螢幕快照,其中強調 [匯出範本] 選項。](media/experience-specific-guidance/dataflow-gen2-export-template.png)
在 [匯出範本] 對話框中,輸入此範本的名稱(必要)和描述(選擇性)。 完成時,選取確定。
災害發生之後,請在新的工作區 「C2 中建立新的數據流 Gen2 專案。W2“。。
從 Power Query 編輯器的目前檢視窗格中,選取 [從 Power Query 樣本匯入]。
![顯示目前檢視的螢幕快照,其中強調 [從 Power Query] 樣本匯入。](media/experience-specific-guidance/dataflow-gen2-import-from-power-query-template.png)
在 [開啟] 對話框中,流覽至您的預設下載資料夾,然後選取 您在先前步驟中儲存的 .pqt 檔案。 然後選取 [開啟]。
範本接著會匯入至新的 Dataflow Gen2 專案。
資料管線
客戶無法在發生區域性災害時存取數據管線,且設定不會復寫到配對的區域。 建議您在不同的區域中,在多個工作區中建置重要的數據管線。
實時智慧
本指南會逐步引導您完成即時智慧體驗的復原程式。 其涵蓋 KQL 資料庫/查詢集和事件數據流。
KQL 資料庫/查詢集
KQL 資料庫/查詢集用戶必須採取主動措施,以防止區域性災害。 下列方法可確保在發生區域性災害時,KQL 資料庫查詢集中的數據會保持安全且可存取。
使用下列步驟來保證 KQL 資料庫和查詢集的有效災害復原解決方案。
建立獨立的 KQL 資料庫:在專用網狀架構容量上設定兩個或多個獨立的 KQL 資料庫/查詢集。 這些應該設定在兩個不同的 Azure 區域(最好是 Azure 配對的區域),以最大化復原能力。
複寫管理活動:在一個 KQL 資料庫中採取的任何管理動作都應該鏡像到另一個資料庫。 這可確保這兩個資料庫保持同步。要復寫的主要活動包括:
數據表:確定數據表結構和架構定義在資料庫之間是一致的。
對應:複製任何必要的對應。 請確定數據源和目的地正確對齊。
原則:確定這兩個資料庫都有類似的數據保留、存取和其他相關原則。
管理驗證和授權:針對每個複本,設定必要的許可權。 請確定已建立適當的授權層級,同時授與必要人員的存取權,同時維護安全性標準。
平行數據擷取:若要讓數據在多個區域中保持一致且就緒,請在您內嵌數據的同時,將相同的數據集載入每個 KQL 資料庫中。
Eventstream
eventstream 是 Fabric 平臺中的集中式位置,可擷取、轉換和路由即時事件到各種目的地(例如 lakehouses、KQL 資料庫/查詢集),且沒有程式代碼體驗。 只要災害復原支援目的地,事件串流就不會遺失數據。 因此,客戶應該使用這些目的地系統的災害復原功能來保證數據可用性。
客戶也可以在多個 Azure 區域中部署相同的 Eventstream 工作負載,作為多站臺主動/主動策略的一部分,來達成異地備援。 透過多網站主動/主動方法,客戶可以在任何已部署區域中存取其工作負載。 這種方法是災害復原最複雜且成本最高的方法,但在大部分情況下,它可以將復原時間減少到接近零。 若要完全異地備援,客戶可以
在不同的區域中建立其數據源的複本。
在對應的區域中建立 Eventstream 專案。
連線 這些新專案到相同的數據源。
為不同區域中的每個事件數據流新增相同的目的地。