描述 Spark 結構化串流
Spark 結構化串流是一種用於記憶體內部處理的熱門平台。 其具有適用於批次和串流的統一範例。 您學到並用於批次的一切,都可以用於串流,因此可以輕鬆地從批次處理資料成長到串流處理資料。 Spark 串流只是在 Apache Spark 上執行的引擎。

結構化串流會建立長時間執行的查詢,在這段期間您會將作業套用到輸入資料,例如選取範圍、投影、彙總,視窗化,以及聯結串流 DataFrame 與參考 DataFrame。 接下來,您會使用自訂程式碼(例如 SQL Database 或 Power BI)將結果輸出至檔案儲存體 (Azure 儲存體 Blob 或 Data Lake Storage) 或任何資料存放區。 結構化串流也會提供輸出給主控台以在本機偵錯,和給記憶體內部資料表,讓您可以查看在 HDInsight 中偵錯所產生的資料。
以資料表的形式串流
Spark 結構化串流會將資料流表示為無限深度的資料表,也就是資料表會在新資料到達時繼續成長。 此輸入資料表會持續由長時間執行的查詢處理,並將結果傳送至輸出資料表:

在結構化串流中,資料抵達系統後會立即內嵌至輸入資料表。 您可以撰寫查詢 (使用 DataFrame 和資料集 API),以針對此輸入資料表執行作業。 查詢輸出會產生另一個資料表,即結果資料表。 結果資料表包含您的查詢結果,您可以從中為外部資料存放區提取資料,例如關聯式資料庫。 從輸入資料表處理資料的時機是由觸發程序間隔所控制。 根據預設,觸發程序間隔為零,因此結構化串流會在資料到達時立即嘗試處理資料。 實際上,這表示只要結構化串流完成執行前一個查詢,就會針對任何新收到的資料啟動另一個處理回合。 您可以設定觸發程序以間隔執行,讓以時間為基礎的批次處理串流資料。
結果資料表中的資料可能只包含自上次處理查詢後的新資料 (附加模式),或是每次有新資料時,結果資料表中的資料就會重新整理,使該資料表包含自串流查詢開始後的所有輸出資料 (完整模式)。
附加模式
在附加模式中,只有自從上次查詢執行之後新增至結果資料表的資料列才會出現在結果資料表中,並寫入外部儲存體。 例如,最簡單的查詢是將所有資料完全不變地從輸入資料表直接複製到結果資料表。 每次觸發程序間隔經過時,都會處理新的資料,以及代表新資料的資料列會出現在結果資料表中。
請考慮您正在其中處理股票價格資料的情節。 假設第一個觸發程序已於時間 00:01 處理一個事件,而 MSFT 股票的價格為 95 美元。 在查詢的第一個觸發程序中,只有時間為 00:01 的資料列才會出現在結果資料表中。 當另一個事件於時間 00:02 到達時,唯一新資料列是時間為 00:02 的資料列,因此,結果資料表將只包含該資料列。
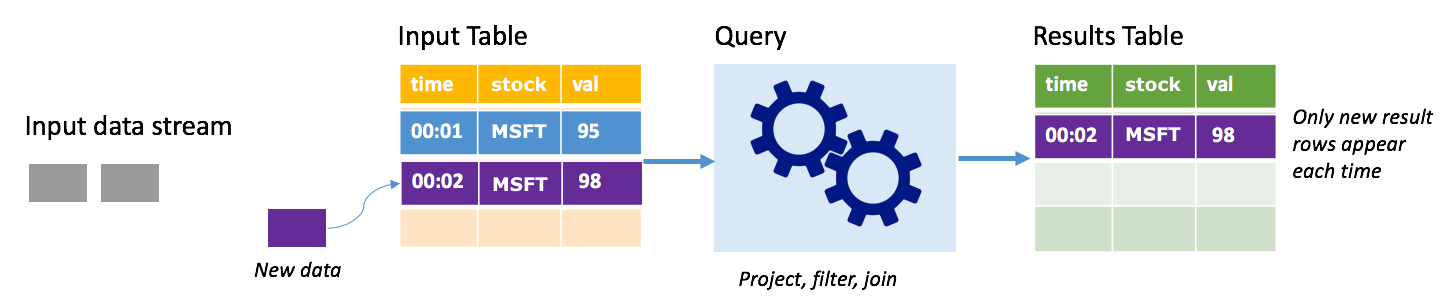
使用附加模式時,您的查詢會套用投影 (選取它關心的資料行)、篩選 (只挑選符合特定條件的資料列) 或聯結 (以靜態查閱資料表中的資料增強資料)。 附加模式可讓您輕鬆地只將相關的新資料點推送至外部儲存體。
完整模式
請考慮相同的情節,這次使用完整模式。 在完整模式中,會在每個觸發程序時重新整理整個輸出資料表,因此資料表不僅包含來自最近觸發程序執行的資料,也包含來自所有執行的資料。 您可以使用完整模式,將未改變的資料從輸入資料表複製到結果資料表。 每次觸發執行時,新的結果資料列會與先前的所有資料列一起出現。 輸出結果資料表最後會儲存查詢開始後所收集的所有資料,而且您最終會用光記憶體。 完整模式旨在與彙總查詢搭配使用,以相同的方式彙總傳入資料,因此,每次觸發時,就會以新的彙總更新結果資料表。
假設目前為止已處理五秒的資料,而且是時候處理第六秒的資料。 輸入資料表有時間 00:01 及時間 00:03 的事件。 此查詢範例的目標是每五秒提供股票的平均價格。 此查詢的實作會套用彙總,以取得落入每 5 秒這個時間範圍內的所有值,將股票價格平均,並產生一列代表該間隔的平均股票價格。 在第一個 5 秒視窗結束時,有兩個 Tuple:(00:01、1、95) 和 (00:03、1、98)。 因此,針對時間範圍 00:00-00:05,彙總會產生平均股票價格為 $96.50 的元組。 在下一個 5 秒的時間範圍內,只有時間 00:06 上有一個資料點,所以產生的股票價格為 $98。 在時間 00:10 上使用完整模式,則結果資料表具 00:00-00:05 和 00:05-00:10 這兩個時間範圍的資料列,因為查詢會輸出所有彙總的資料列,而不是只輸出新的資料列。 因此,若新增時間範圍,結果資料表就會繼續成長。
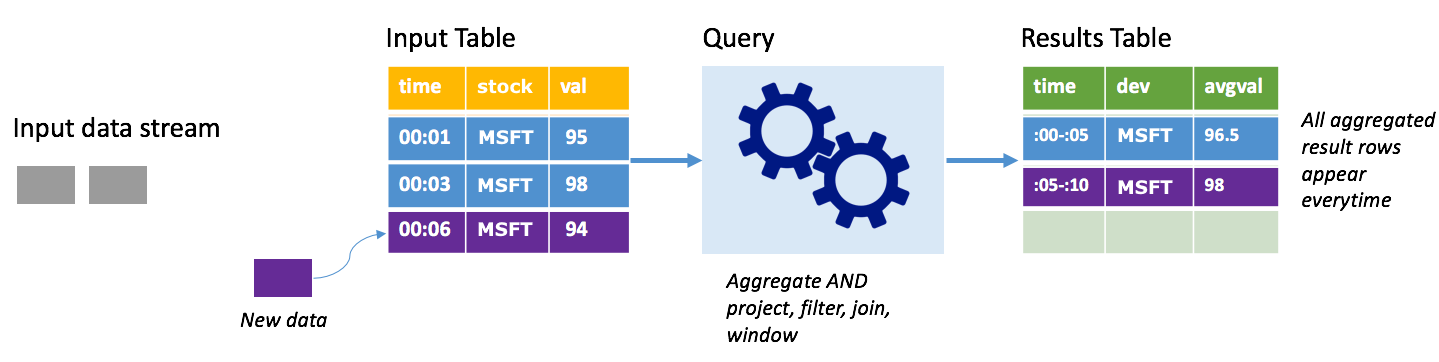
並非所有使用完整模式的查詢都會導致資料表無極限地成長。 在前一個案例中,考慮的不是根據時間範圍來平均股票價格,而是依股票來平均股票價格。 結果資料表會包含固定數目的資料列 (每個股票一列),其中包含股票的平均股票價格 (利用從該裝置接收的所有資料點來計算)。 當收到新的股票價格時,結果資料表就會更新,以便資料表中的平均值一直都是最新的。
Spark 結構化串流有哪些優點?
在財務部門中,交易的時機非常重要。 例如,在股票交易中,股票交易發生於股票市場的時間、當您收到交易的時間,或當讀取資料的時間,這些時間的差異都很重要。 對於金融機構來說,它們取決於此重要資料,以及與其相關聯的時機。
事件時間、晚期資料和浮水印
Spark 結構化串流知道事件時間與系統處理事件時間之間的差異。 每個事件都是資料表中的資料列,而事件時間是資料列中的資料行值。 這允許時間範圍型彙總 (例如,每分鐘的事件數目) 只是事件時間資料行上的群組和彙總 – 每個時間範圍都是群組,而且每個資料列都可以屬於多個時間範圍/群組。 因此,可以在靜態資料集以及資料流上一致地定義這類事件時間範圍的彙總查詢,讓資料工程師的生活更輕鬆。
此外,這個模型會根據事件時間,自然處理晚於預期時間到達的資料。 Spark 可在有延遲的資料時,完全控制更新舊彙總,以及清除舊彙總以限制中繼狀態資料的大小。 此外,自 Spark 2.1 起,Spark 支援浮水印,這可讓您指定延遲資料的閾值,並可讓引擎相應地清除舊狀態。
上傳最近資料或所有資料的彈性
如上一個單元中所討論,您可以在使用 Spark 結構化串流時選擇使用附加模式或完整模式,以便結果資料表只包含最新的資料或所有資料。
支援從微批次移至連續處理
藉由變更 Spark 查詢的觸發程序類型,您可以從處理微批次移至連續處理,而不需要對您的架構進行其他變更。 以下是 Spark 支援的各種不同觸發程序。
- 未指定,這是預設值。 如果未明確設定觸發程序,則會以微批次執行查詢,並持續處理。
- 固定間隔微批次。 查詢會依使用者設定的週期性間隔開始。 如果沒有收到任何新資料,則不會執行微批次程序。
- 一次性微批次。 此查詢會執行單一微批次,然後停止。 自上一個微批次後,如果您想要處理所有資料,這會很有幫助,而且可以為不需要持續執行的作業節省成本。
- 利用固定檢查點間隔持續進行。 此查詢是以新的低延遲、連續處理模式執行,其會啟用低 (~1 毫秒) 端對端延遲,而且至少有一次容錯保證。 這類似於預設值,其可以實現正好一次的保證,但最多只實現 ~100 毫秒的延遲。
合併批次和串流作業
除了簡化從批次移至串流作業的動作之外,您也可以合併批次和串流作業。 當您想要使用長期歷程記錄資料來預測未來的趨勢,同時處理即時資訊時,此功能特別有用。 針對股票,您可能會想要查看過去 5 年的股票價格 (除了目前的價格之外),以預測根據每年或每季收入公告所做的變更。
事件時間範圍
您可能想要擷取時間範圍中的資料,例如,一天時間範圍或一分鐘時間範圍內的高股票價格和低股票價格 (無論您決定哪個間隔),以及 Spark 結構化串流也支援此功能。 也支援重疊時間範圍。
失敗復原的檢查點
如果失敗或刻意關閉,您可以復原前一個進度和前一個查詢的狀態,並從離開之處繼續進行。 此做法是使用檢查點和預寫記錄檔。 您可以使用檢查點位置設定查詢,而且查詢會將所有進度資訊 (亦即,每個觸發程序中處理的位移範圍) 和執行中彙總儲存到檢查點位置。 此檢查點位置必須是 HDFS 相容檔案系統中的路徑,而且可以在啟動查詢時設定為 DataStreamWriter 中的選項。