練習 - 將 Kafka 資料串流至 Jupyter 筆記本並將資料視窗化
Kafka 叢集現在會將資料寫入至其記錄,這可透過 Spark 結構化串流處理。
Spark 筆記本包含在您所複製的範例中,因此您必須將該筆記本上傳至 Spark 叢集才能加以使用。
將 Python 筆記本上傳至 Spark 叢集
在 Azure 入口網站中,按一下 [首頁] > [HDInsight 叢集],然後選取您剛才建立的 Spark 叢集 (不是 Kafka 叢集)。
在 [叢集儀表板] 窗格中,按一下 [Jupyter 筆記本]。

提示您輸入認證時,請輸入系統管理員的使用者名稱,然後輸入您建立叢集時所建立的密碼。 Jupyter 網站隨即顯示。
按一下 [PySpark],然後在 [PySpark] 頁面上,按一下 [上傳]。
瀏覽至您從 GitHub 下載範例的位置、選取 RealTimeStocks.ipynb 檔案,然後按一下 [開啟],再按一下 [上傳],然後按一下網際網路瀏覽器中的 [重新整理]。
筆記本上傳至 PySpark 資料夾後,按一下 RealTimeStocks.ipynb,即可在瀏覽器中開啟筆記本。
將您的游標放在資料格中,然後按 Shift + Enter 鍵執行資料格,以執行筆記本中的第一個資料格。
當 [設定程式庫和套件] 資料格顯示 [正在啟動 Spark 應用程式] 訊息和其他資訊 (如下列螢幕標題所示),即表示其成功完成。
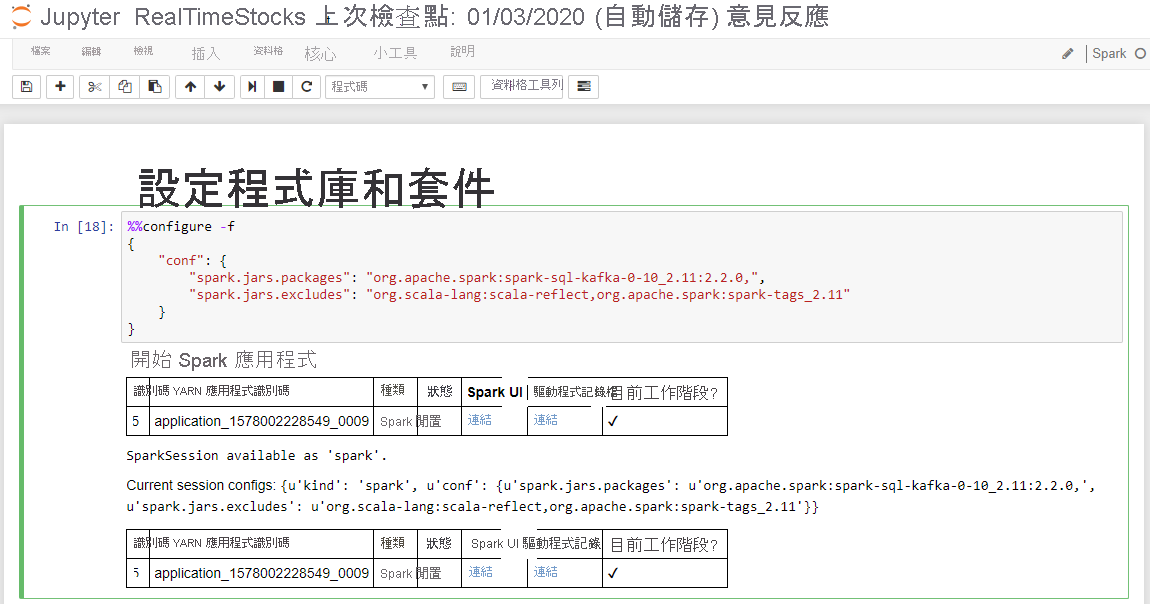
在 [設定 Kafka 的連線] 資料格中,於 .option("kafka.bootstrap.servers", "") 行上的第二組引號之間輸入 Kafka 訊息代理程式。 例如, .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"),然後按 Shift+Enter 鍵以執行資料格。
當 [設定 Kafka 的連線] 資料格顯示訊息「inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 more fields]」時,即表示其成功完成。 Spark 會使用 readStream API 來讀取資料。
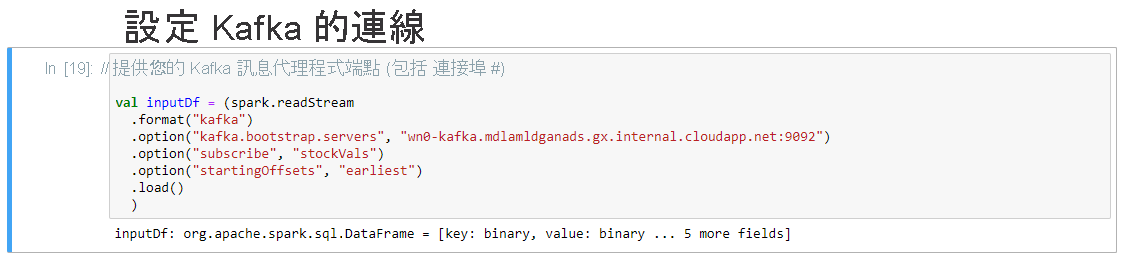
選取 [從 Kafka 讀入串流資料框架] 資料格,然後按 Shift+Enter 鍵以執行資料格。
當資料格顯示下列訊息時,即表示其成功完成:stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
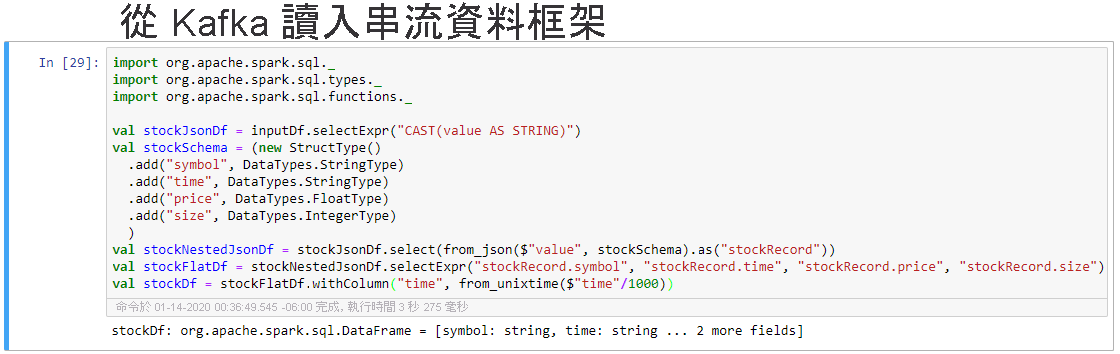
選取 [將串流資料框架輸出至主控台] 資料格,然後按 Shift+ Enter 鍵以執行資料格。
當資料格顯示如下資訊時,即表示其成功完成。 輸出會在每個資料格傳入微批次時顯示其值,而且每秒有一個批次。
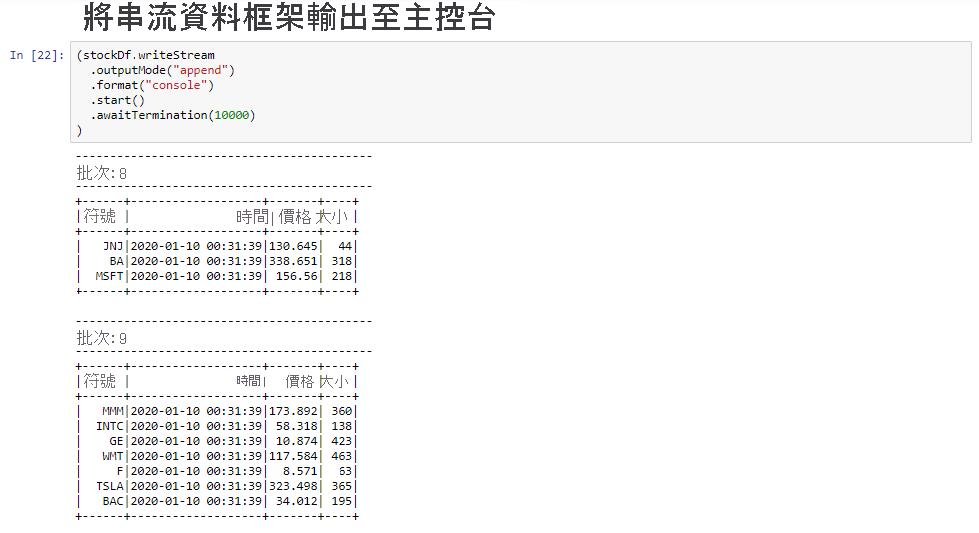
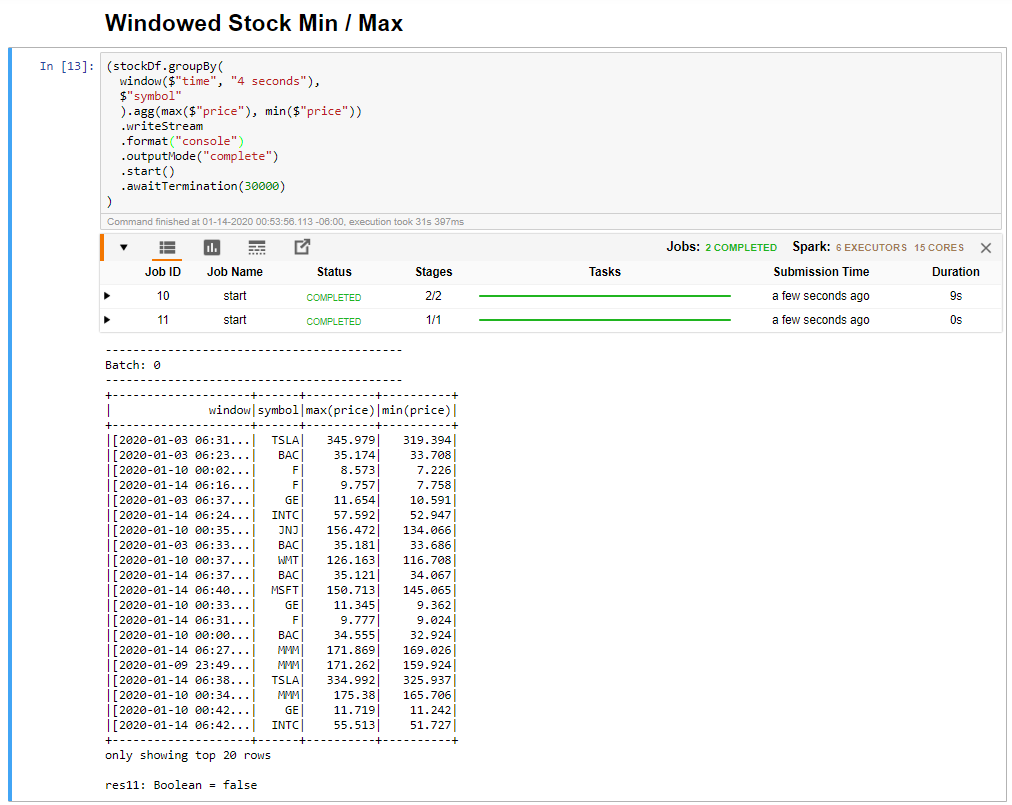
選取 [視窗型股票下限/上限] 資料格,然後按 Shift + Enter 鍵以執行資料格。
當資料格提供 4 秒時間範圍中每個股票的最大和最小價格 (定義在資料格中) 時,即表示其成功完成。 如上一個單元中所討論,提供特定時間範圍的相關資訊是使用 Spark 結構化串流所獲得的優點之一。
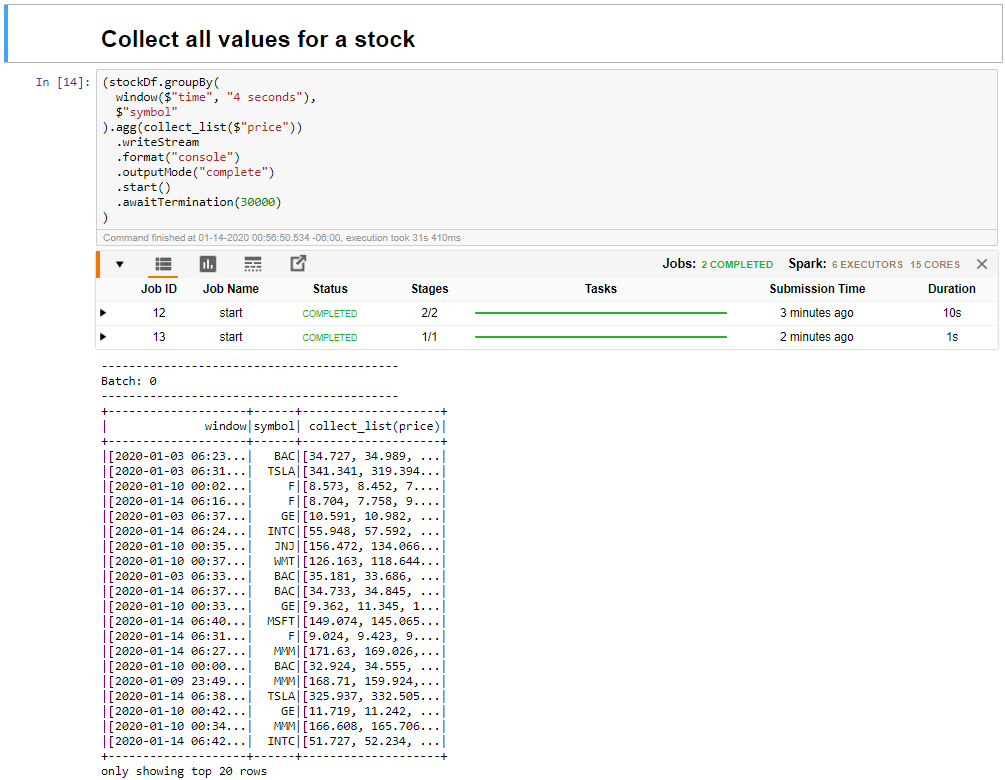
選取 [收集時間範圍中股票的所有值] 資料格,然後按 Shift + Enter 以執行資料格。
當資料格提供資料表中股票的值表時,即表示其成功完成。 OutputMode 完成,以便所有資料都會顯示出來。
在此單元中,您已將 Jupyter 筆記本上傳至 Spark 叢集、將它連接到您的 Kafka 叢集、將 Python 生產者檔案所建立的串流資料輸出至 Spark 筆記本、定義串流資料的時間範圍並顯示該時間範圍中的高低股票價格,以及顯示資料表中股票的所有值。 恭喜,您已成功使用 Spark 和 Kafka 執行結構化串流!