何時應該使用 HDInsight Interactive Query?
身為業務分析師,您需要確定要建立的最適當的 HDInsight 叢集類型,以建立您的解決方案。 Interactive Query 叢集提供許多功能和互通性選項,可讓熟悉 SQL 的業務分析師擁有獨特的好處。 適合想要使用商業智慧工具,而且需要快速互動式查詢的使用者。 還有其他優點,例如支援各種檔案格式、並行,以及不可部分完成、一致、隔離且持久 (ACID) 的交易。 更不用說與 Apache Ranger 的整合,以對資料進行更細微的資料列和資料行層級控制。
注意
本課程模組的內容適用於針對 HDInsight 4.0 建立的 Interactive Query 叢集,其使用 Hive 3.1 和 LLAP,也稱為 Hive LLAP。
您有一個已準備好可供查詢的大型資料集
Interactive Query 叢集最適用於可以依原樣 (或使用最少的轉換) 查詢的大型資料集。 當您要對資料執行各種查詢,而且需要立即回應的情況。 Interactive Query 叢集未針對執行長時間執行的批次計算進行最佳化。 互動式查詢支援下列檔案格式:ORC、Parquet、CSV、Avro、JSON、文字和 tsv。
您需要類似 SQL 的功能
當您需要針對 Azure 儲存體和 Azure Data Lake Storage 中的巨量資料執行互動式和特定亞秒延遲查詢時,且您偏好使用類似 SQL 的體驗,Azure HDInsight Interactive Query 叢集是很好的選擇。 身為業務分析師,您非常熟悉 SQL 資料表和使用 SQL 來建立查詢。 Apache Hadoop 是一個功能強大的工具,可執行巨量資料分析。 如果您的 Java 程式設計技能有點生疏,Apache Hadoop對 MapReduce 架構及其 Java API 的使用可能會對您造成阻礙。 在此情況下,HDInsight Interactive Query 較適合,因為其是以 Apache Hadoop 為基礎進行建置,但對於具備 SQL 體驗的任何人而言,會更容易使用。 Interactive Query 會使用類似 SQL 的 Hive 資料表來處理資料,以及使用類似 SQL 的查詢語言 (稱為 HiveQL) 來查詢資料。 使用 Hive 比在 Apache Hadoop 中使用 MapReduce 處理資料更為複雜。 Hive 可讓您更快速且更有效率地將解決方案推出給您的公司。
使用智慧型快取的快速互動式查詢
Interactive Query 叢集使用智慧型快取技術,跨動態 RAM、本機叢集節點 SSD 和遠端儲存體系統 (例如 Azure Blob 和 Azure Data Lake Storage) 將資料分層,以在巨量資料上達到互動式且快速的查詢結果。 先進快取技巧的一個好例子是動態文字快取,它會即時將 CSV 資料轉換成最佳化記憶體內部格式,因此快取是動態的,而且查詢會決定要快取的資料。 這種功能表示您不需要先載入並轉換資料。 您可以將資料以原始格式上傳至 Azure 儲存體,並開始加以查詢。 此外,這也表示查詢在第二次執行時效率更高。 第一次執行查詢時,會從 Azure 儲存體或 Azure Data Lake Gen2 中的業務資料儲存層讀取資料。 然後,資料會快取到叢集中的共用記憶體內部快取。 下一次執行查詢時,只會從共用記憶體內部快取中取出資料,並無需從遠端儲存層取出資料,從而節省時間。
使用熱門工具執行查詢
交互式查詢使您可以使用熟悉的 BI 工具 (例如 Microsoft Power BI 和 Tableau) 輕鬆處理巨量資料。 在巨量資料分析中,組織越來越擔心其終端使用者無法從分析系統中取得足夠的價值,因為這通常具有挑戰性,而且需要使用不熟悉且難以學習的工具來執行分析。 HDInsight Interactive Query 透過最少的使用者訓練,甚至不需要進行新的使用者訓練來從資料中取得見解,藉此解決此問題。 使用者可以在其已使用的工具中撰寫類似 SQL 的 HiveQL 查詢。 這些工具包括 Visual Studio Code、Power BI、Apache Zeppelin、Visual Studio、Ambari Hive View、Beeline、Data Analytics Studio 和 Hive ODBC。 您無法使用 Hive 主控台、Templeton、Azure 傳統 CLI 或 Azure PowerShell 在您的 Interactive Query 叢集上執行查詢。
您需要交易一致性和並行
隨著引入更細緻的資源管理、在查詢和使用者之間優先使用與共用快取資料,Interactive Query 可輕鬆地支援並行使用者。 HDInsight 支援在共用的 Azure 儲存體上建立多個叢集。 Hive 中繼存放區有助於達到高度並行。 您可以新增更多叢集節點,或加入更多指向相同基礎資料和中繼資料的叢集,以調整並行。 Interactive Query 也支援不可部分完成、一致、隔離且持久 (ACID) 的資料庫交易。 ACID 交易保證即使交易包含多個作業,也會包含在單一單位中。 因此,如果交易中的任何單一作業失敗,則可以復原整個作業,讓資料保持一致且正確。
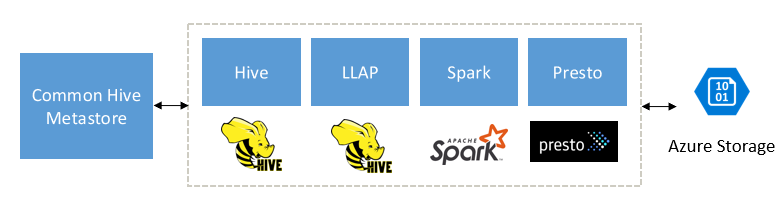
專門用來補充 Spark、Hive、Presto 和其他巨量資料引擎
HDInsight Interactive Query 的設計可與熱門的巨量資料引擎搭配使用,例如 Apache Spark、Hive、Presto 等等。 這種類型的查詢特別有用,因為您的使用者可以選擇這些工具中的任何一個來執行其分析。 透過 HDInsight 的共用資料和外部資料表的中繼資料架構,使用者可以使用指向相同基礎資料和中繼資料的相同或不同的引擎來建立多個叢集。 這項功能是強大的概念,因為您不再受限於一種分析技術。