HDInsight 互動式查詢
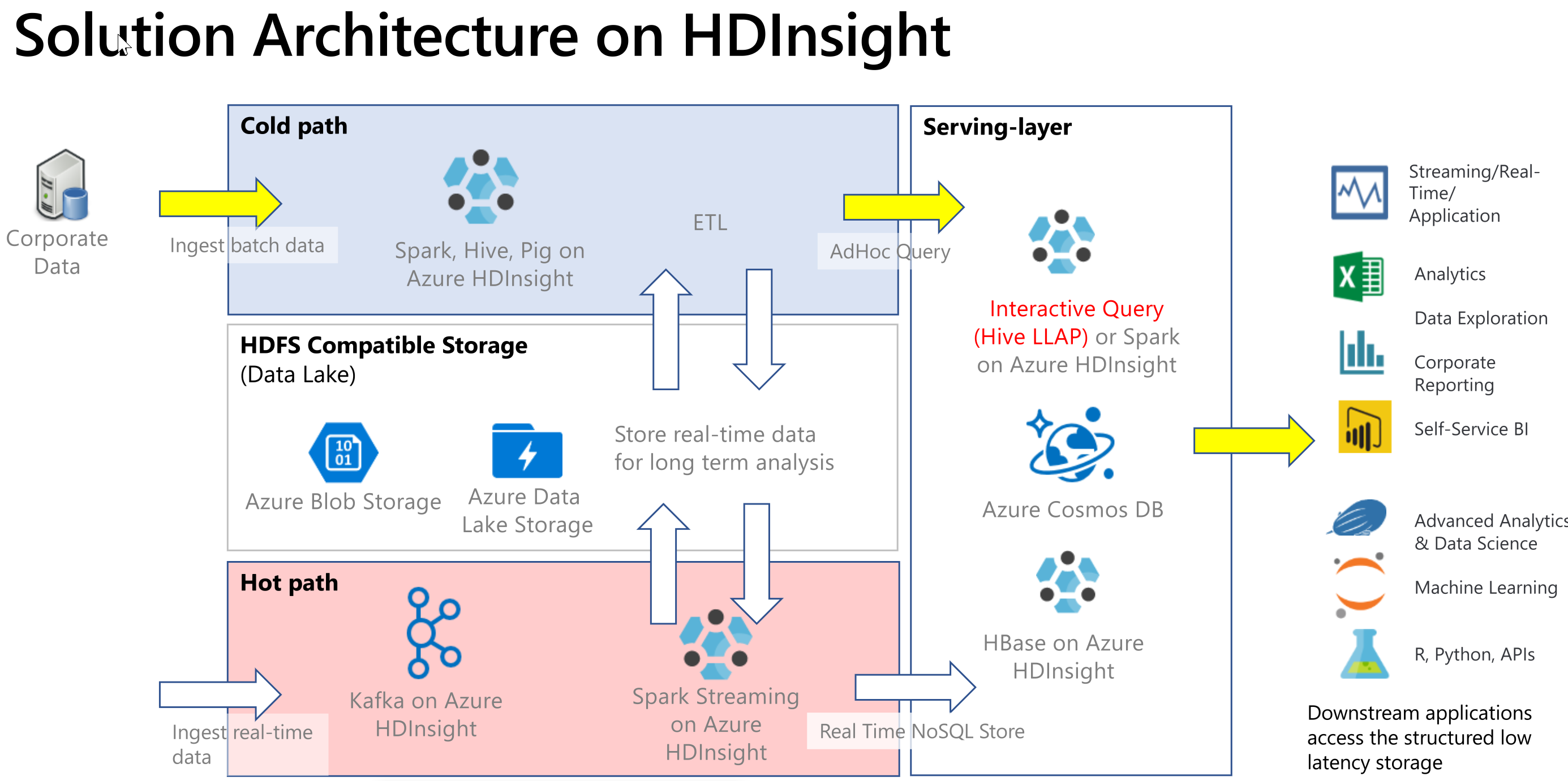
Interactive Query 通常會在冷路徑情節中實作,其中您的資料採用表格式格式,而且想要使用 SQL 語法快速提出問題並取得互動式回應。 下圖顯示所有 HDInsight 冷路徑和最忙碌路徑解決方案的解決方案架構,並呼叫如何透過服務層中的 Hive LLAP 來處理互動式查詢。 您可以透過 Hive 內嵌資料,互動式查詢會透過 Hive LLAP 來處理,而輸出則可以提供給下游應用程式,例如 Power BI。
Interactive Query 架構
現在讓我們來深入探討 Interactive Query 架構。
Interactive Query 使用者可以從各種不同的 ODBC 或 JDBC 用戶端進行選擇,對其業務資料執行查詢,例如 Data Analytics Studio、Zeppelin 筆記本和 Visual Studio Code。 在用戶端提交 HiveQL 查詢之後,查詢會抵達 HiveServer,其負責查詢計劃、最佳化,以及安全性調整。 Hive 的運作方式是將分析工作劃分到叢集中的各個分散式節點。 查詢會分割成子工作,並傳送至處理每個子工作的節點,而這些子工作會更進一步分割,而且每個工作都會從基礎業務資料儲存層讀取資料。 由於使用了「永遠啟動」的 LLAP 精靈 (可避免啟動時間) 以及共用的記憶體內部快取 (用於儲存從儲存體取出的資料,並在所有節點之間共用資料)J,該架構已最佳化。
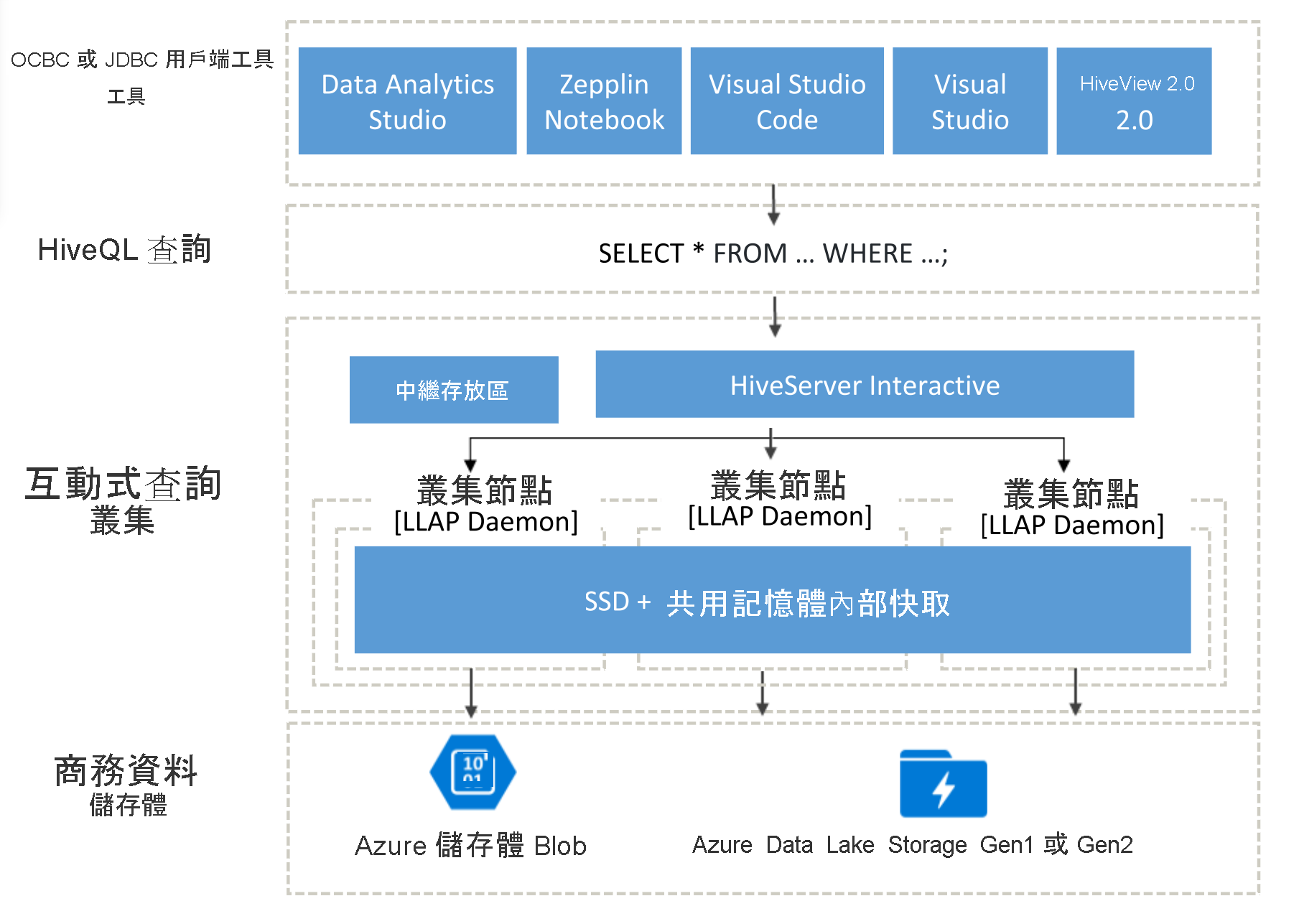
Interactive Query 叢集使用的固態硬碟 (SSD),會將 RAM 和 SSD 結合成大型記憶體集區,以供快取所使用。 透過這種資源組合,一般伺服器設定檔可以快取 4 倍以上的資料,使您可以處理較大型的資料集,並支援更多使用者。 Interactive Query 快取知道遠端存放庫 (Azure 儲存體) 中的基礎資料變更,因此,如果基礎資料變更和使用者發出查詢,更新的資料就會載入記憶體中,而不需要任何額外的使用者步驟。