整合 Apache Spark 和 Hive LLAP 查詢
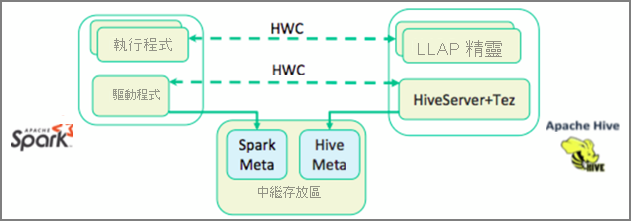
在上一個單元中,我們探討了兩種方法來查詢儲存在 Interactive Query 叢集中的靜態資料 – Data Analytics Studio 和 Zeppelin 筆記本。 但是,如果您想要使用 Spark 將最新的房地產資料串流至您的叢集,然後使用 Hive 查詢它呢? 因為 Hive 和 Spark 有兩個不同的中繼存放區,所以它們需要連接器在兩者之間橋接,而 Apache Hive Warehouse Connector (HWC) 就是該橋接器。 Hive Warehouse Connector 程式庫可讓您更輕鬆地使用 Apache Spark 和 Apache Hive,方法是支援例如在 Spark DataFrames 和 Hive 資料表之間移動資料,以及將 Spark串流資料導向到 Hive 資料表之類的工作。 我們不會在我們的情節中設定連接器,但請務必了解此選項是否存在。
Apache Spark 具有結構化串流 API,可提供 Apache Hive 中沒有提供的串流功能。 從 HDInsight 4.0 開始,Apache Spark 2.3.1 和 Apache Hive 3.1.0 有個別的中繼存放區,這使得互通性變得困難。 Hive Warehouse Connector 可讓您更輕鬆地搭配使用 Spark 和 Hive。 Hive Warehouse Connector 程式庫會以平行方式將 LLAP 精靈中的資料載入 Spark 執行程式,與使用從 Spark 到 Hive 的標準 JDBC 連線相比,它更有效率且更具擴充性。
Hive Warehouse Connector 所支援的部分作業包括:
- 描述資料表
- 為最佳化資料列單欄式 (ORC) 格式的資料建立資料表
- 選取 Hive 資料並擷取資料架構
- 將資料架構批次寫入至 Hive
- 執行 Hive 更新陳述式
- 從 Hive 讀取資料表資料、在 Spark 中轉換它,並將它寫入至新的 Hive 資料表
- 使用 HiveStreaming 將資料架構或 Spark 串流寫入至 Hive
一旦部署了 Spark 叢集和 Interactive Query 叢集,就可以在 Ambari 中設定 Spark 叢集設定,Ambari 是所有 HDInsight 叢集中都包含的 Web 型工具。 若要開啟 Ambari,請在您的網際網路瀏覽器中瀏覽至 https://servername.azurehdinsight.net,其中 servername 是您的 Interactive Query 叢集的名稱。
然後,若要將 Spark 串流資料寫入資料表中,您可以建立 Hive 資料表,並開始將資料寫入其中。 然後,針對您的串流資料執行查詢,您可以使用下列任何一項:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy